Setting up GitOps integration isn't as clean as the architecture diagrams suggest. Here's what you'll actually encounter when wiring together Docker, Kubernetes, ArgoCD, and Prometheus.
Docker: The Easy Part That Gets Complicated
Docker containers work great until you start optimizing them. Multi-stage builds will save you disk space but cost you sanity when debugging why your production image is missing dependencies that were available during the build stage.
The gotcha: Alpine-based images look appealing because they're tiny, but you'll spend hours tracking down missing `glibc` dependencies. Ubuntu images are 10x larger but actually fucking work. Choose your pain.
Version warning: Docker 20.10.17 has a known issue with BuildKit that causes random build failures on ARM64. In 2025, use Docker 27.x+ with containerd integration - it's finally stable and fixes most ARM64/Apple Silicon issues.
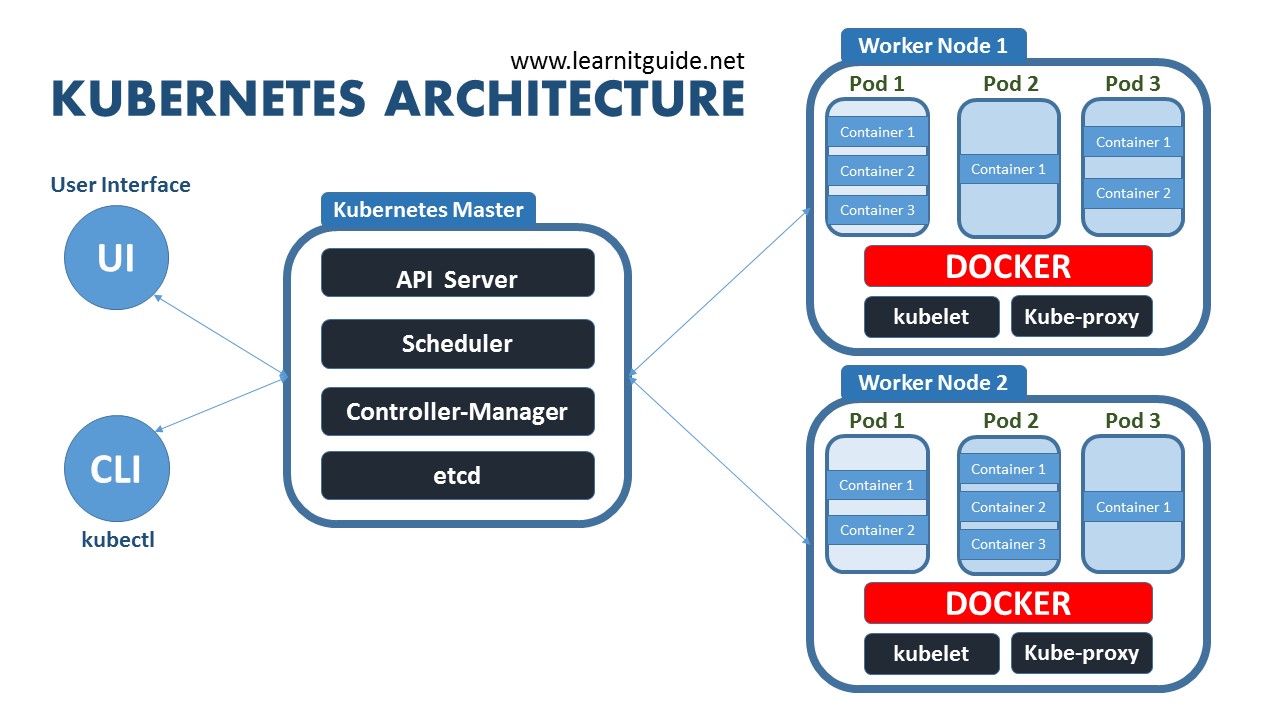
Kubernetes: Where Dreams Go to Die
Kubernetes networking is about as intuitive as assembly language. You'll spend your first week figuring out why pods can't reach each other despite being in the same namespace.
The learning curve: Expect 2-3 months before you stop googling "how to debug CrashLoopBackOff". Kubernetes 1.30+ improved error messages slightly, but the logs are still scattered across multiple components, and `kubectl describe` output reads like machine-generated poetry.
Memory management: If you don't set resource limits, one runaway pod will consume all available memory and crash your entire node. If you set limits too low, your perfectly working application will get OOMKilled during peak traffic.
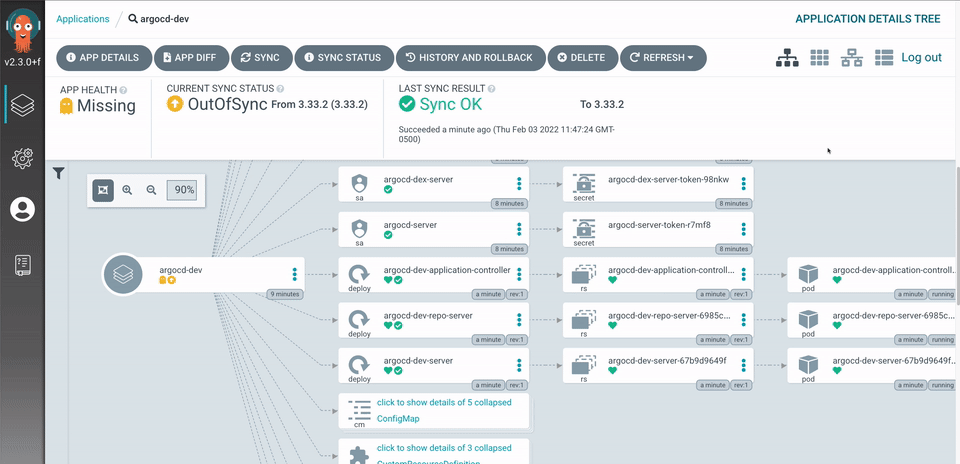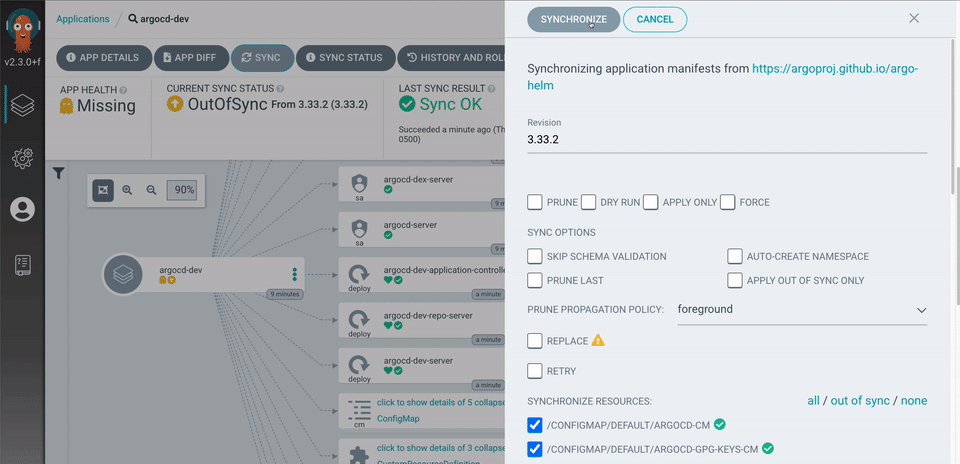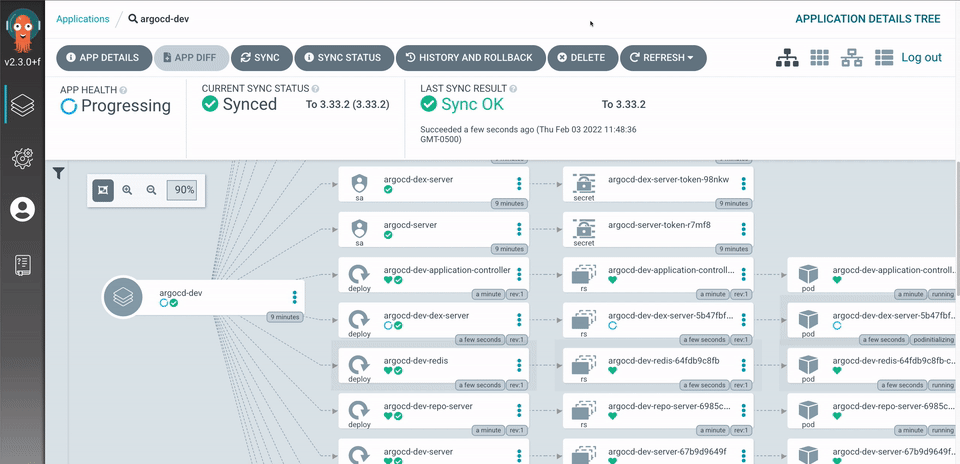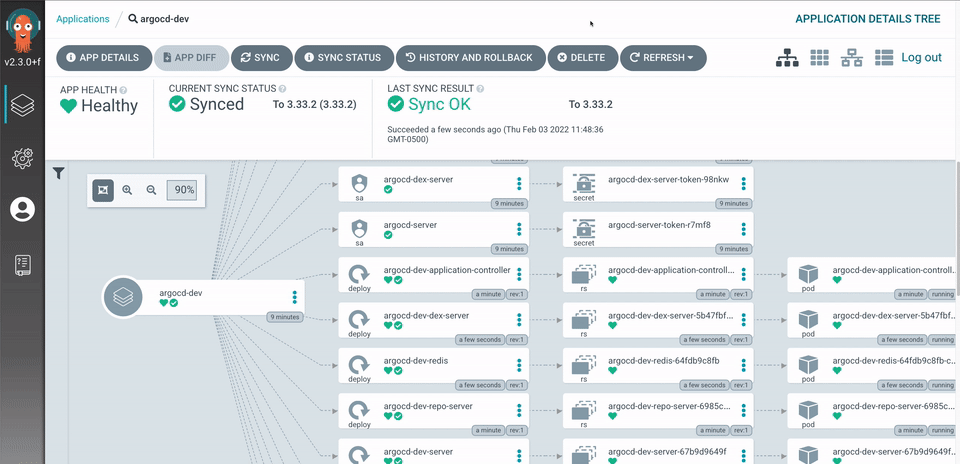
ArgoCD: Beautiful UI, Terrible Debugging
ArgoCD's interface looks professional but becomes useless the moment something breaks. The sync status will show "Healthy" while your application returns 500 errors because ArgoCD only checks if Kubernetes accepted the manifests, not if they actually work.
Sync failures: ArgoCD will randomly stop syncing and you'll spend 3 hours troubleshooting only to discover it was a Redis connection timeout. The solution is always "restart the ArgoCD pods" but the root cause is never documented.
RBAC nightmares: Getting permissions right requires a PhD in Kubernetes RBAC. Too restrictive and deployments fail silently. Too permissive and you've violated every security policy your company has.
Prometheus: Memory Eating Monster

Prometheus collects every metric from every pod and will happily consume all your RAM doing it. The default retention policy keeps data forever, which sounds great until you realize it's storing terabytes of mostly useless metrics.
Storage nightmare: Plan for 200GB+ storage minimum. Without proper configuration, Prometheus will fill your disk in a few weeks. Set retention to 15 days unless you have infinite money for storage.
Grafana dependency: Prometheus metrics are useless without Grafana dashboards. You'll spend days creating custom PromQL queries only to discover someone already built the exact dashboard you need and published it on grafana.com.
The Repository Structure That Actually Works
Forget the textbook patterns. Here's what works in practice:
Separate app and config repos: Your application code goes in one repo, Kubernetes manifests in another. Why? Because developers will push broken YAML if you mix them, and debugging becomes impossible.
Branch-based environments are garbage: Using git branches for dev/staging/prod sounds clever but creates merge conflicts from hell. Use directory-based environments instead:
/environments/
/prod/
/staging/
/dev/
Config templates save sanity: Use Helm or Kustomize. Raw YAML files mean copying the same configuration 20 times and forgetting to update half of them when values change.
Security: The Thing Everyone Ignores
Kubernetes security is an afterthought until your cluster gets compromised. Here's the minimum you need:
Image scanning: Trivy finds vulnerabilities but produces so many false positives you'll ignore them all. Configure it to only alert on "High" and "Critical" CVEs or prepare to hate your life.
RBAC hell: Every service account needs exactly the permissions it requires and nothing more. Good luck figuring out what that is without breaking everything first.
Secret management: Don't put secrets in Git even if they're "encrypted". Use External Secrets Operator or similar tools. Your future self will thank you when you're not rotating API keys after accidentally committing them to GitHub.
This stack works once you accept that it will break in creative ways and build your debugging skills accordingly.