Flux is great when it works. When it doesn't, you're fucked and have no idea why. I've been running Flux in production for 3 years and here's what actually breaks (and how to fix it without losing your mind).
The problems outlined in the hero section aren't theoretical - they're the exact issues that will wake you up at 3am. Let's dive into each category with real debugging approaches that work.
Memory Consumption Patterns That Kill Clusters
The Problem: Flux controllers start with 50-100MB each but can balloon to 2GB+ under specific conditions, causing OOMKilled events and cascade failures.
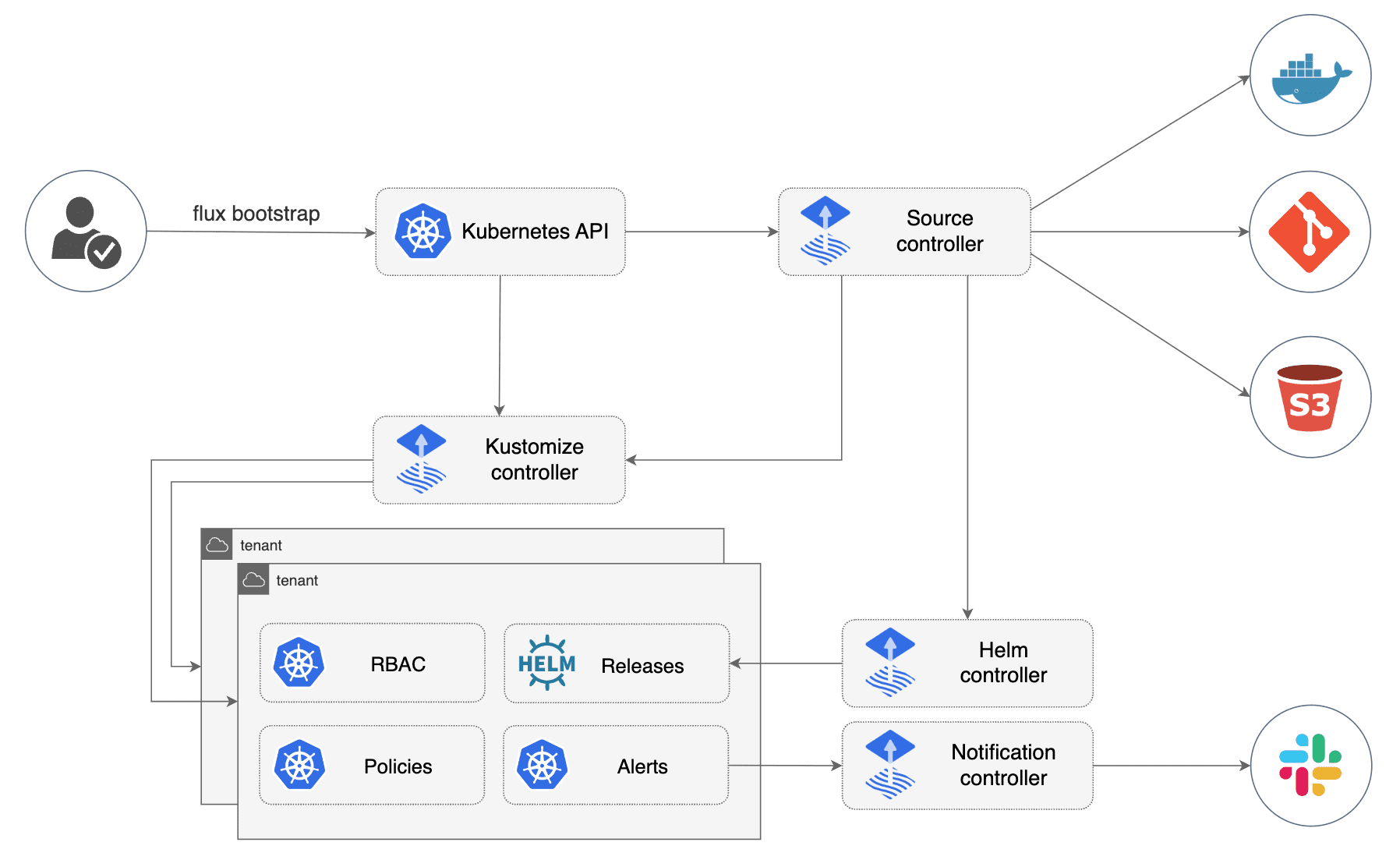
Flux's modular controller architecture means performance issues can cascade across components - understanding the data flow is crucial for debugging.
Source Controller Memory Leaks - The biggest offender. Source Controller clones Git repos and caches them in-memory. Large monorepos with frequent commits cause unbounded memory growth. I've seen teams hit sync intervals that were originally fine suddenly taking forever because repos were consuming way too much RAM. This relates to the Kubernetes OOMKilled troubleshooting patterns that many teams struggle with.
Real clusterfuck I debugged: One team had like 200MB of manifests in their monorepo. Source Controller kept cloning the whole damn history instead of shallow clones. Memory went from normal to completely fucked over about a day, then the pod died. Took me most of a weekend to figure out it was the Git implementation setting - turns out libgit2 just keeps everything in memory like a hoarder. This shit happens more than you'd think with Git performance issues in Kubernetes.
Fix: Configure vertical scaling limits and enable shallow clones:
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
metadata:
name: webapp
spec:
url: https://github.com/fluxcd/flux2-kustomize-helm-example
ref:
branch: main
interval: 5m
gitImplementation: go-git # Better memory management than libgit2
verification:
mode: strict
Kustomize Controller Manifest Bloat - When managing 500+ applications, the controller loads all YAML into memory simultaneously. Each manifest gets stored in etcd with full metadata.managedFields, which can reach several MB per resource with frequent updates.
What happens: etcd becomes the bottleneck. I've seen clusters where a simple kubectl get kustomizations -A takes like 30+ seconds because etcd is serving hundreds of MB of metadata bloat. Your cluster feels completely broken but it's just choking on YAML garbage - Kubernetes' favorite way to die slowly.
Monitor your controller resource usage with the Flux2 Grafana dashboard - memory spikes indicate when controllers are struggling with large manifests.
etcd performance bottlenecks are one of the most common causes of Flux reconciliation slowdowns in production environments - manifest bloat causes etcd to struggle with hundreds of MB of metadata.
Fix: Implement Flux controller sharding and tune etcd compression. This requires understanding etcd performance optimization and Kubernetes etcd scaling practices:
## Split workloads across multiple Kustomize controllers
flux install --components-extra=kustomize-controller-shard1
flux install --components-extra=kustomize-controller-shard2
## Enable etcd compression (reduces metadata bloat by 60-80%)
etcd --auto-compaction-retention=1000 --auto-compaction-mode=revision
Git API Rate Limiting Hell
The Reality: GitHub/GitLab APIs have rate limits that become critical at scale. Default Flux intervals will exhaust your API quota within hours if you manage 50+ repos.
Rate limit math: GitHub allows 5,000 API calls/hour with authentication. Each GitRepository burns through a couple API calls per sync. With tons of repos syncing every minute, you'll hit the limit embarrassingly fast - I've watched teams exhaust their quota in under 20 minutes with large setups, then spend 40 minutes wondering why deployments just stopped.
The cascade effect: When Source Controller hits rate limits, it backpressures all other controllers. Nothing deploys until rate limits reset, but your monitoring shows "everything is healthy" because the controllers are still running. This is a classic GitOps scaling challenge and mirrors problems documented in GitHub API rate limiting best practices.
Production fix: Implement exponential backoff and GitHub Apps authentication:
## Use GitHub Apps instead of personal tokens (10x higher rate limits)
apiVersion: v1
kind: Secret
metadata:
name: github-app-auth
data:
private-key: <base64-encoded-private-key>
app-id: <github-app-id>
installation-id: <installation-id>
---
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
spec:
secretRef:
name: github-app-auth
interval: 5m # Longer intervals reduce API pressure
GitHub API rate limits become critical bottlenecks when managing 50+ repositories with frequent sync intervals - standard tokens get 5,000 API calls per hour, which sounds like a lot until you have 100 repositories syncing every minute.
Alternative: Use OCI artifacts instead of Git for high-frequency deployments. Container registries have higher API limits and better caching. This approach aligns with GitOps scaling best practices for production environments.
Reconciliation Loops and Dependency Deadlocks
The Problem: Circular dependencies between resources cause infinite reconciliation loops, consuming CPU and creating confusing logs that make debugging impossible.
Common pattern: HelmRelease depends on a ConfigMap that's created by a Kustomization that depends on the HelmRelease being healthy. The controllers endlessly retry without clear error messages.
Debugging nightmare: Spent 3 days on a "ReconciliationFailed" error with zero useful logs. Turns out the Service needed a StatefulSet that couldn't start because PVCs weren't created because the StorageClass got deleted during some cluster maintenance nobody remembered. The error message told us absolutely nothing useful about this dependency chain - Flux errors are about as helpful as a broken GPS when you're lost. This happens constantly with Kubernetes dependency hell patterns.
Debugging workflow that actually works:
## 1. Check overall health
flux get all --all-namespaces
## 2. Look for stuck reconciliations (status shows old timestamps)
kubectl get gitrepositories,kustomizations,helmreleases -A -o wide
## 3. Deep dive on failing resource (this shows dependency chain)
kubectl describe kustomization app-name -n namespace
## 4. Check events across all related namespaces
kubectl get events --sort-by=.metadata.creationTimestamp -A | grep -E \"flux|gitops\"
## 5. Enable debug logging on controllers (CPU intensive - use sparingly)
flux logs --level=debug --kind=Kustomization --name=app-name
Large-Scale Performance Tuning
Enterprise reality: Teams managing 1000+ applications need different approaches than the default Flux configuration. Standard advice doesn't apply.
Deutsche Telekom's Production Setup: They manage 200+ 5G infrastructure clusters with 10 engineers using hub-and-spoke architecture. Their approach follows multi-cluster GitOps patterns and enterprise scaling strategies. Key insights:
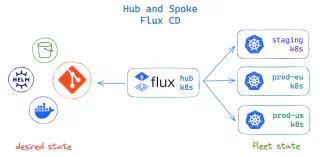
Hub-and-spoke deployment reduces operational overhead but requires careful resource sizing for the central hub cluster.
- Separate cluster configs from app configs: Prevents merge conflicts when 50 teams are deploying simultaneously
- Controller resource limits: 2GB memory, 500m CPU per controller minimum for enterprise workloads
- Sync intervals: 15-minute intervals for infrastructure, 2-minute for applications
- Repository structure: 1 repo per 10-20 applications maximum (Git performance degrades beyond this)
Resource sizing for production (based on real deployments):
| Scale | Controllers | Memory/Controller | CPU/Controller | Sync Interval |
|---|---|---|---|---|
| < 50 apps | Default (4) | 100MB | 100m | 1m |
| 50-200 apps | Default (4) | 500MB | 200m | 2m |
| 200-500 apps | Sharded (6) | 1GB | 300m | 5m |
| 500+ apps | Sharded (8+) | 2GB | 500m | 15m |
The Flux Cluster Stats dashboard shows controller metrics and reconciliation health across all controllers - this is what healthy looks like vs. the disaster you'll see when things go wrong.
The Flux Cluster Stats dashboard provides critical visibility into controller performance and reconciliation health - essential for diagnosing performance issues before they cascade. Monitor reconciliation duration, memory usage, and queue lengths to catch problems early.
Performance monitoring that catches issues before they cascade:
## Memory growth pattern (normal vs. problematic)
kubectl top pods -n flux-system --sort-by=memory
## Reconciliation lag (healthy systems show <30s average)
kubectl get kustomizations -A -o jsonpath='{range .items[*]}{.metadata.name}{" "}{.status.lastAttemptedRevision}{" "}{.status.lastAppliedRevision}{"
"}{end}'
## Git API quota usage (GitHub Apps provide 10x limits)
curl -H \"Authorization: Bearer $GITHUB_TOKEN\" https://docs.github.com/en/rest/rate-limit
Here's the thing: the most common production issue isn't some obscure config bug. It's teams trying to scale Flux like it's kubectl and being completely shocked when everything catches fire.
The defaults are fine for demos but complete garbage for anything real. You can't just flux install and expect it to handle 500 applications with 2-minute sync intervals. That's like expecting a Honda Civic to tow a semi trailer - sounds reasonable in theory until physics kicks your ass on the first hill.