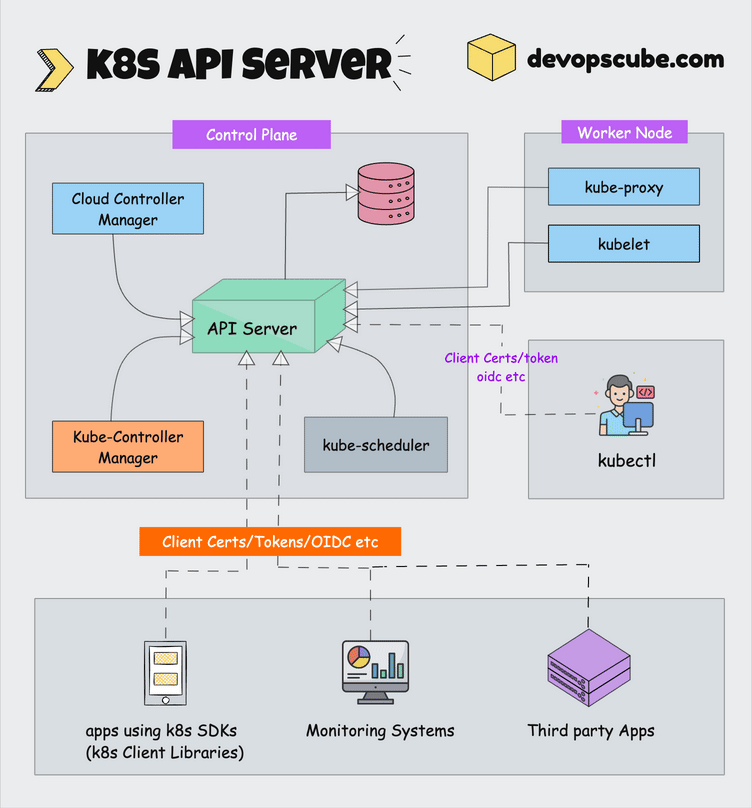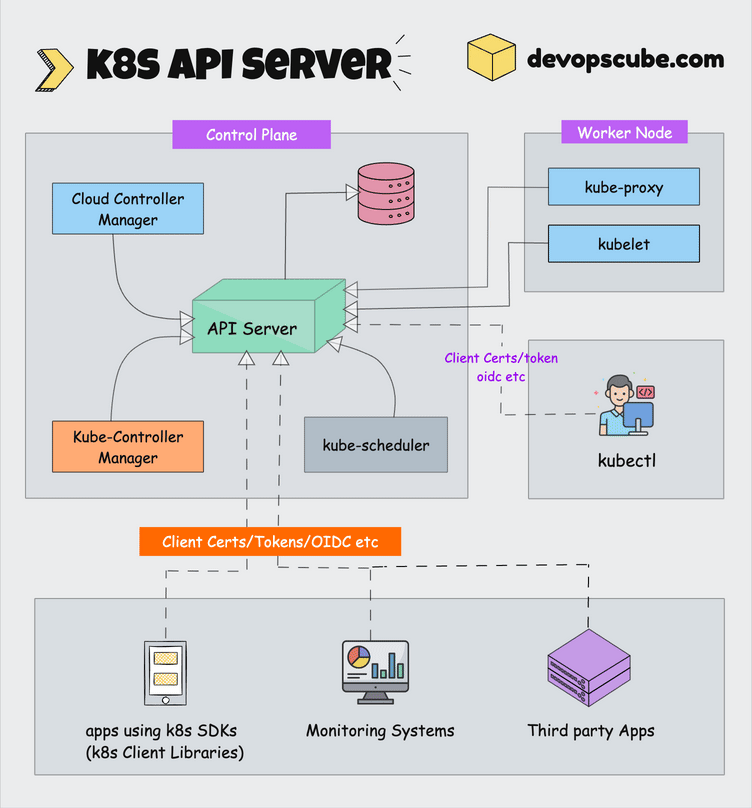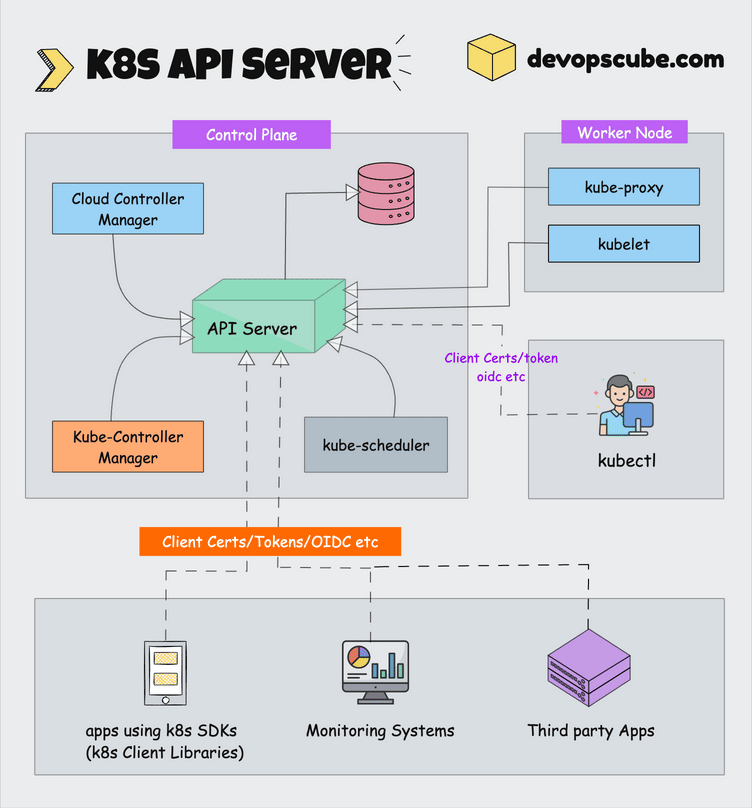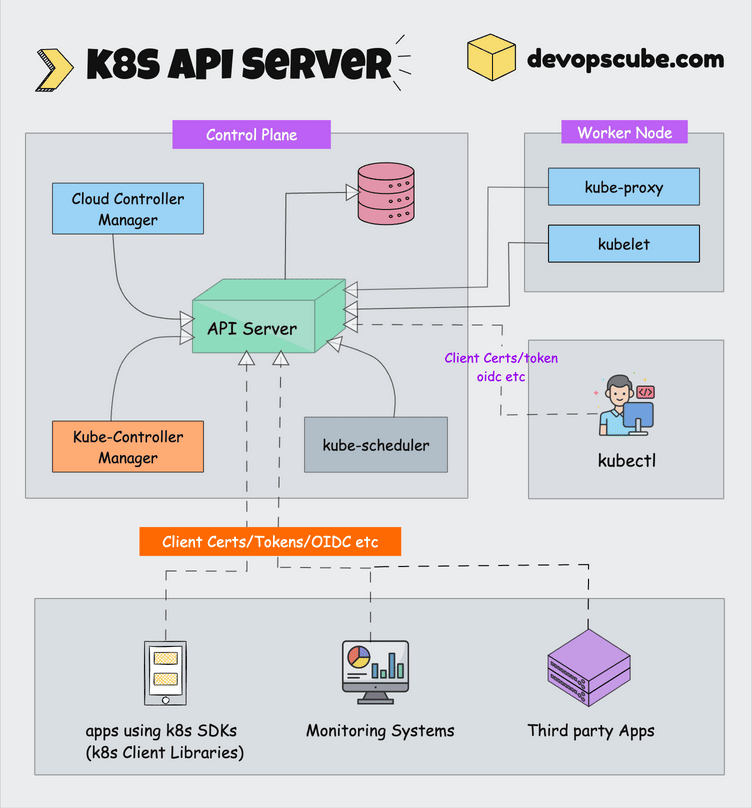
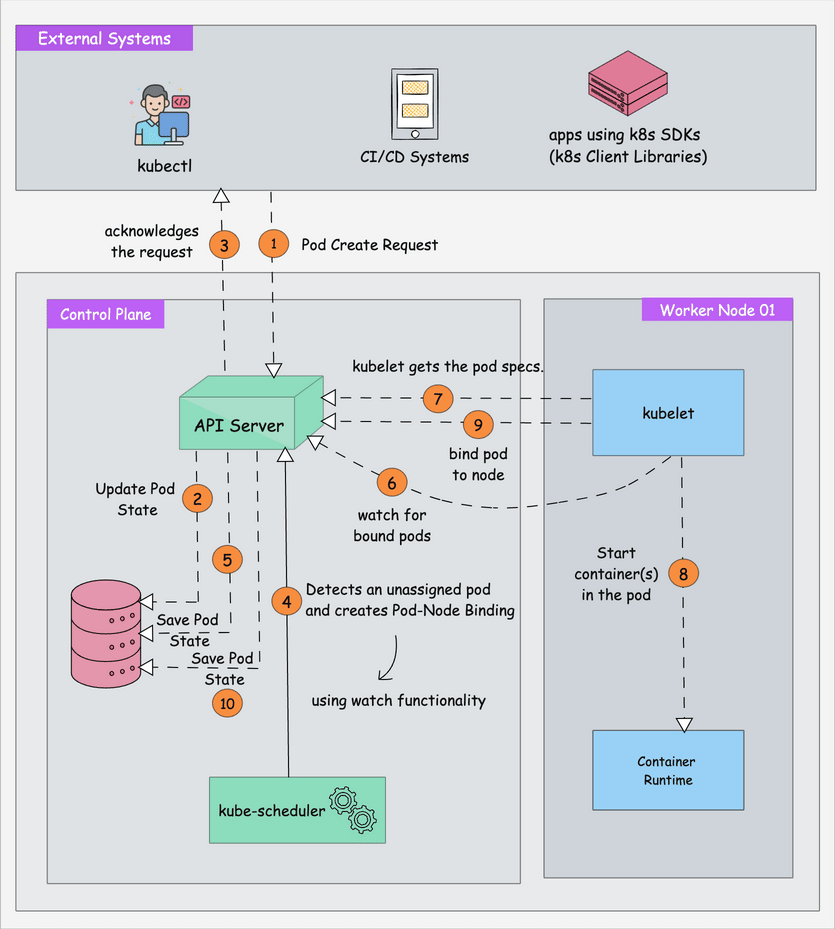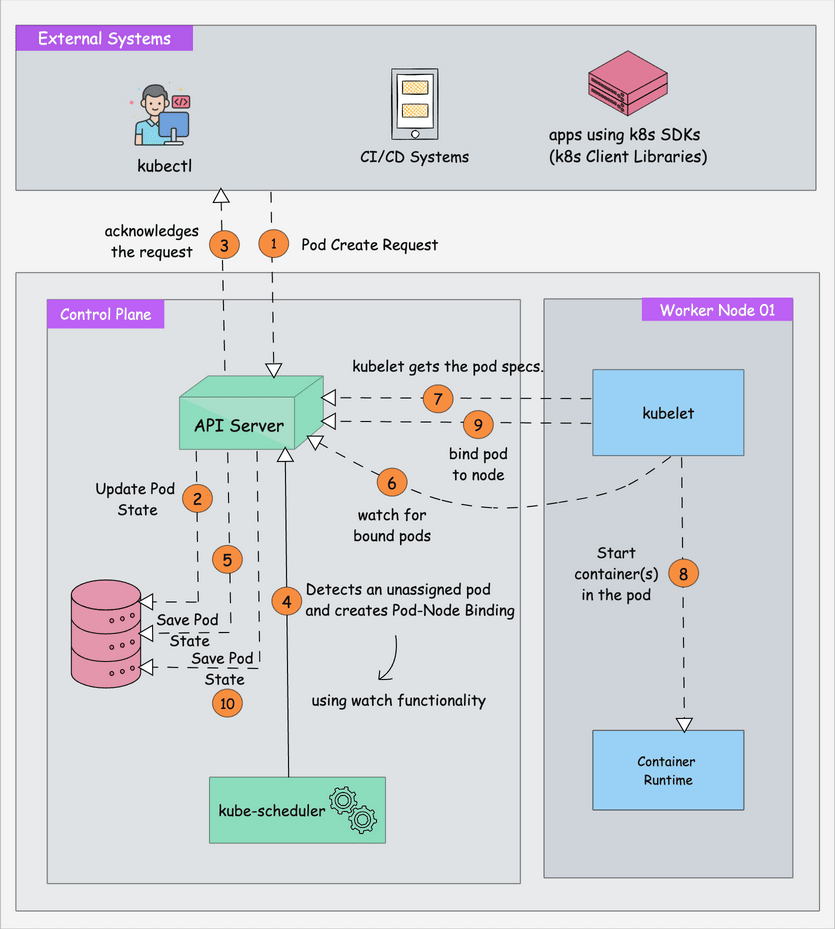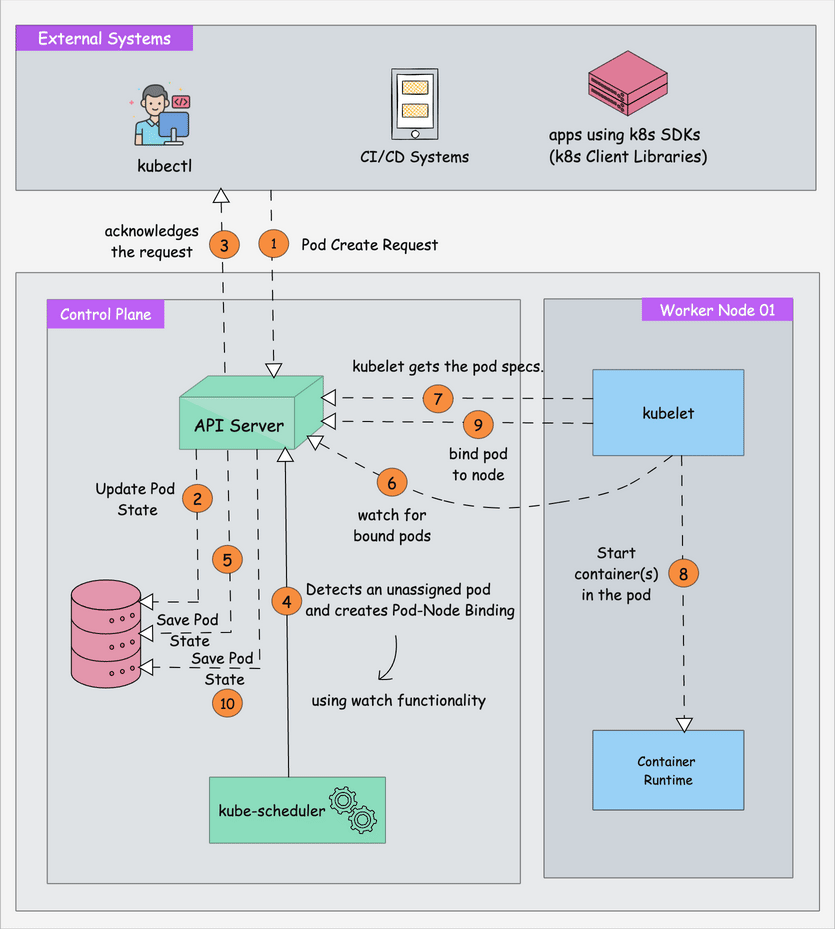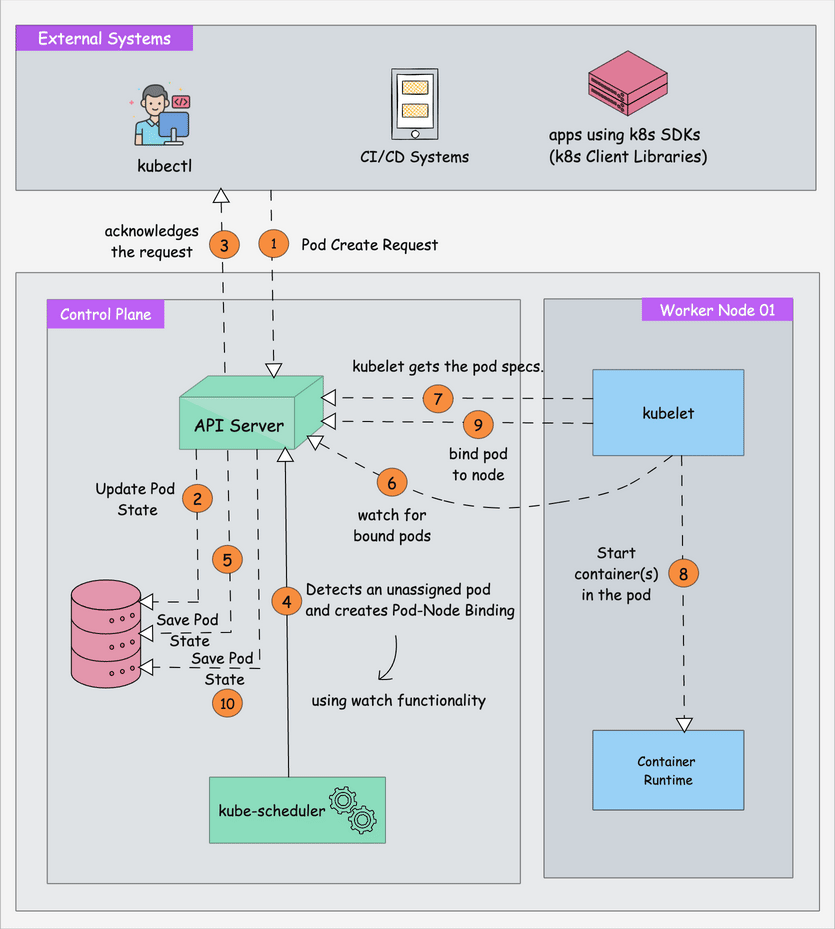
kubeadm is the official command-line tool that actually works. After watching Kustomize break with every kubectl update and OpenShift charge enterprise prices for basic features, kubeadm's boring reliability is refreshing. It boots clusters and gets out of your way.
What kubeadm Actually Does (And Doesn't)
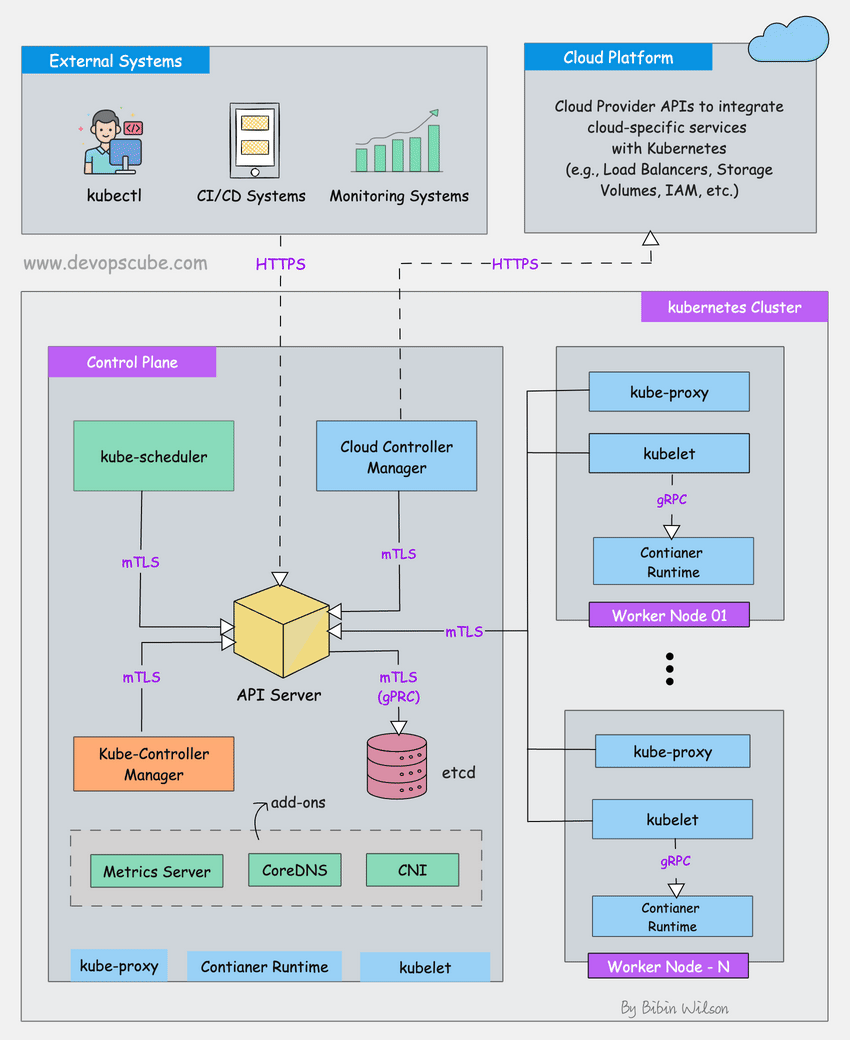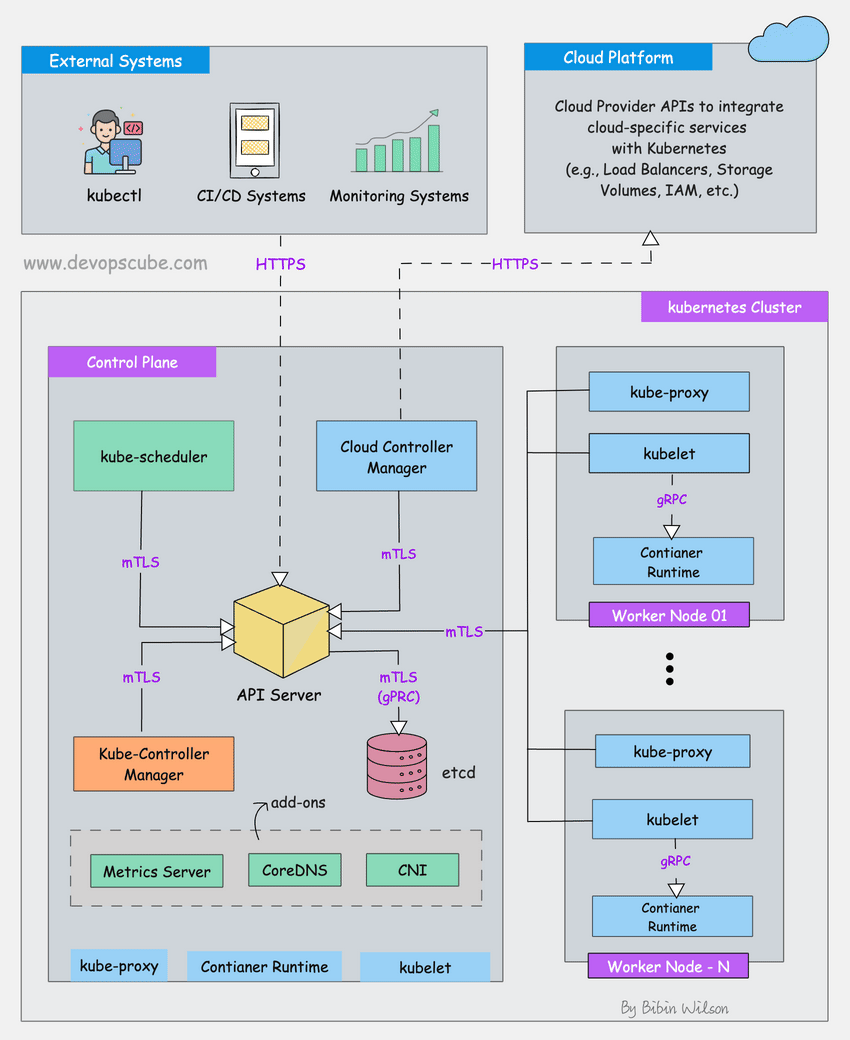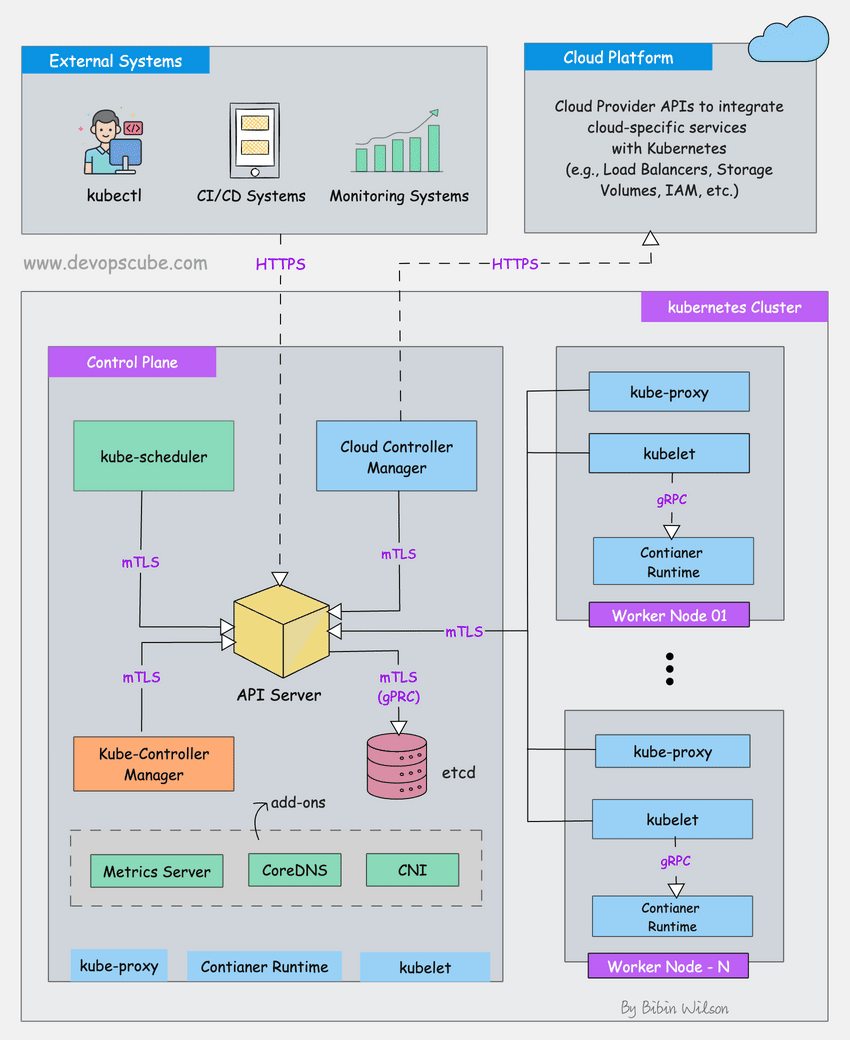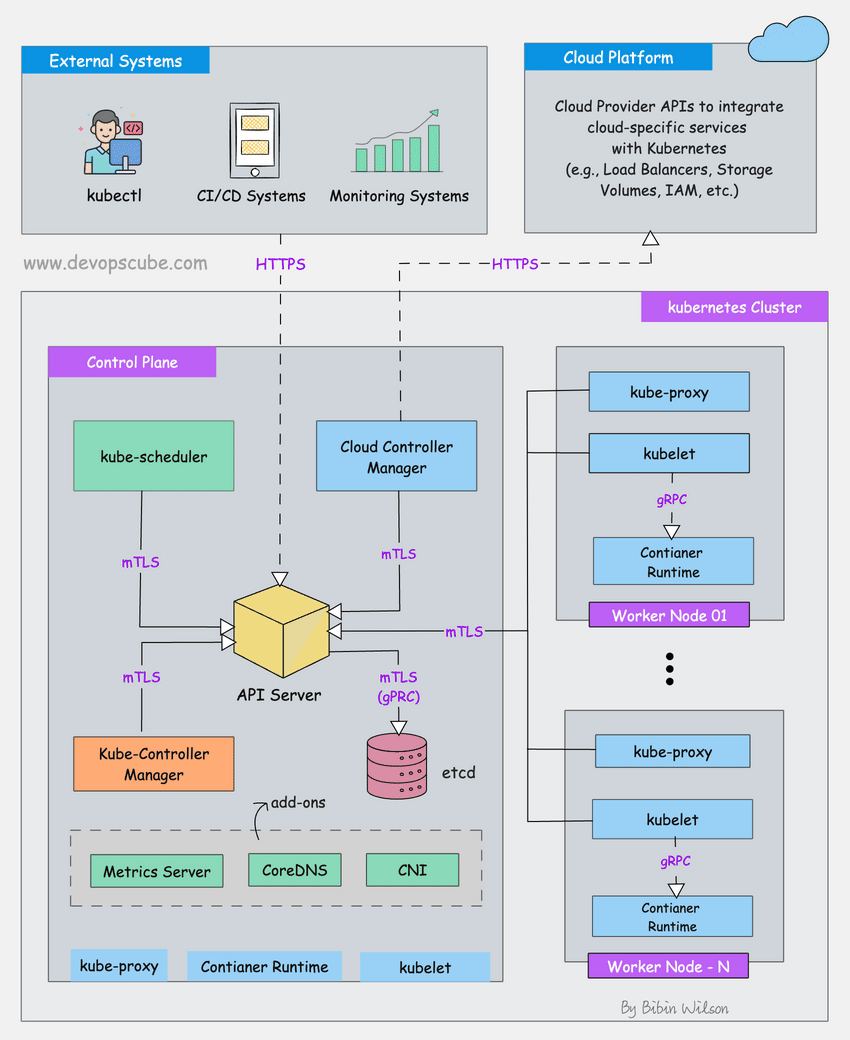
kubeadm does one thing: boots clusters. It won't provision your AWS instances, pick your CNI plugin, or pretend to understand your storage needs. When something breaks, you know it was either kubeadm (rare) or your config (usually).
What kubeadm handles well:
- Certificate generation (expires in 1 year - set a calendar reminder or enjoy explaining downtime)
- Control plane setup with proper RBAC
- Worker node joining with cryptographic tokens
- Cluster upgrades that don't randomly break your workloads
What you're still fucked on:
- CNI plugin choice (Calico? Flannel? Cilium? Pick your poison)
- Storage classes (500 lines of YAML incoming)
- Load balancers, ingress, monitoring, logging, backup... the endless list
The Commands That Actually Matter
Bootstrap a control plane:
kubeadm init --pod-network-cidr=10.244.0.0/16
Spits out a join command that dies in 24 hours. Screenshot it, copy it, tattoo it on your arm - whatever. If you lose it, kubeadm token create --print-join-command generates a new one.
Join worker nodes:
kubeadm join 192.168.1.100:6443 --token abc123.def456 --discovery-token-ca-cert-hash sha256:...
The token and hash change every time. Don't hardcode them in scripts.
Check upgrade paths:
kubeadm upgrade plan
Shows what versions you can upgrade to and what might break. Always run this before upgrading anything.
Version Reality Check
kubeadm supports Kubernetes v1.34 as of August 2025. Each release brings new features and new ways for things to break. The version skew policy means you can't mix random versions - kubeadm prevents most bad combinations, but read the release notes anyway.
Real talk: Don't upgrade to .0 releases unless you want to debug weird shit for free. Wait for .2 or .3 - let someone else find the edge cases that broke prod at 3am.
When to Use kubeadm (And When Not To)
Use kubeadm when:
- You actually want to learn K8s instead of clicking "deploy" buttons
- Running on bare metal because cloud bills hurt your soul
- Spinning up test clusters that you can break guilt-free
- Your team doesn't panic when YAML doesn't parse
- Studying for CKA (it's literally all kubeadm commands)
Skip kubeadm when:
- You want daddy Google/AWS to handle everything (EKS, GKE, AKS)
- Your team has meltdowns over certificate errors
- You need multi-cluster bullshit on day one
- You believe GitOps marketing promises about "simple deployments"
kubeadm doesn't promise magic. It boots clusters reliably. That's it. Most other tools promise unicorns and deliver vendor lock-in wrapped in buzzwords.