So you deployed your gRPC services with Kubernetes and they're load balancing like shit. Welcome to the club. I've watched senior engineers stare at dashboards for hours wondering why 80% of traffic hits one pod while the others are basically doing nothing.
Why Your Load Balancer Is Useless
Here's the thing nobody tells you upfront: traditional load balancers see gRPC as one fat TCP connection. HTTP/2 multiplexing means thousands of requests flow through a single connection, and your fancy load balancer just routes that entire stream to pod-1. Pods 2-5? They're playing solitaire.
Found this out when our order service started choking. CPU was maxed on one pod, the other four were basically idle. Spent forever thinking memory leak, tried bumping resources, restarted everything twice. Finally some contractor was like "hey did you check the connection thing" and it clicked.
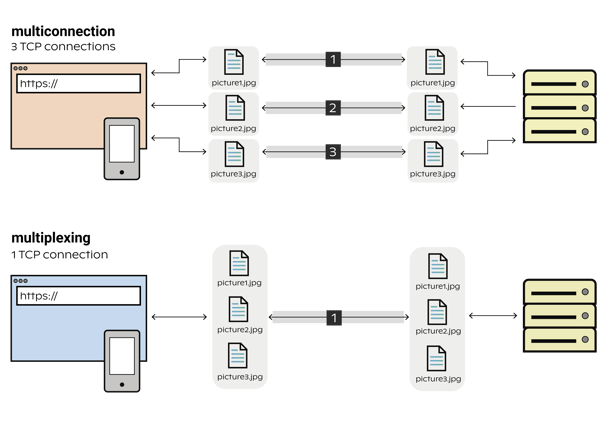
The Layer 7 Solution (That Actually Works)
The fix is layer 7 load balancing. Envoy proxy understands gRPC and can distribute individual requests across backends even within the same HTTP/2 connection. It's like having a bouncer who actually looks at each person instead of just counting cars in the parking lot.

Istio: The Battle-Tested Option
Istio gets the most hate because it's complex, but it works. Used it at a few places now and yeah, learning curve is brutal, but once you get it working it doesn't randomly fall over under load.
The basic DestinationRule that fixed our load balancing:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: grpc-load-balancing
spec:
host: order-service
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN # This actually matters for gRPC
connectionPool:
http:
http2MaxRequests: 100
maxRequestsPerConnection: 10 # Forces new connections
That maxRequestsPerConnection: 10 is critical. It forces Envoy to cycle connections, which spreads load across your pods. Without it, you're back to everything hitting one backend.
Consul Connect: If You're Already Using Consul
If you're already using Consul for service discovery, Connect makes sense. It handles gRPC properly and integrates with the rest of their stack. But don't switch to HashiCorp just for the service mesh - that's a lot of new tooling for one feature.
Used it at a place that was deep into Terraform and Vault. Worked fine but the docs assume you already know Consul inside out. If you don't, expect some confusion around configuration.

Linkerd: The "Simple" Option
Linkerd markets itself as simple, and compared to Istio it actually is. The Rust proxy is lighter on resources and protocol detection works without much configuration. But simple also means limited - don't expect advanced traffic management or fine-grained security policies.
One team I worked with chose it because they were scared of Istio's complexity. It worked fine for their basic use case, but they hit the feature ceiling pretty quickly when they wanted to do canary deployments.


The Reality of Production Deployments
Full Mesh: Maximum Pain, Maximum Gain
Every service talks through mTLS with automatic cert rotation. Looks great on security compliance checklists, hurts like hell to operate. Your certificate authority becomes a critical dependency and every cert rotation is a potential outage.
One place I worked went full mesh from the start. Big mistake. Certs would randomly fail to rotate, usually around 2am. Took months to figure out the root cause was some admission controller conflict. But once we got it stable, debugging became way easier with proper tracing.
Edge-Only: The Compromise Position
North-south traffic goes through the mesh, east-west stays direct. Good middle ground if you want some service mesh benefits without the full operational overhead. Most teams start here and either go backwards (too much hassle) or forwards (full mesh).
The Gradual Migration: How Adults Do It
Start with your most critical services, expand gradually. Takes longer but you won't get fired when something breaks. Just be prepared for weird edge cases where meshed services talk to non-meshed ones.
The Config That Actually Matters
Forget the demo configurations. Here's the stuff that prevents 3am pages:
## This goes in your pilot deployment
env:
- name: PILOT_ENABLE_CROSS_CLUSTER_WORKLOAD_ENTRY
value: "true"
- name: PILOT_ENABLE_WORKLOAD_ENTRY_AUTOREGISTRATION
value: "true"
And for the love of all that's holy, set proper resource limits:
resources:
requests:
memory: 256Mi # Start here, not 128Mi
cpu: 100m
limits:
memory: 512Mi # Double the request
cpu: 1000m # Allow bursts
The Resource Reality Check
Those "lightweight sidecar" claims are bullshit. In production:
- Istio sidecar: 256MB minimum, 512MB if you want it to not OOM during traffic spikes
- Control plane: 3GB+ across replicas if you want HA that doesn't fall over
- Each cert rotation: temporary 50-100MB spike per service
Plan accordingly. I've seen too many clusters fall over because someone believed the marketing material about resource usage.
The Certificates Will Break Everything
mTLS: Not Optional, Always Painful
Your security team will insist on mTLS for everything. Fine. But understand that certificate rotation is now your problem. I've been woken up more times by cert rotation failures than actual service outages.
The default cert lifetime in Istio is 24 hours. That means daily rotation. If anything goes wrong - and it will - your entire mesh can shit the bed. Plan for this. Monitor cert expiry religiously.
Method-Level Authorization: The Cool Feature You Won't Use
Yeah, you can do fine-grained RBAC at the gRPC method level:
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: payment-service-auth
spec:
selector:
matchLabels:
app: payment-service
rules:
- to:
- operation:
methods: ["ProcessPayment"]
when:
- key: source.labels["app"]
values: ["order-service"]
It's neat in theory. In practice, you'll spend more time maintaining authorization policies than you save in security. Most teams end up with service-level auth and call it a day.
Monitoring That Actually Helps
Forget your HTTP dashboards. gRPC metrics are different and most monitoring setups get this wrong.
What you actually need to track:
- Per-method request rates (not just service-level)
- gRPC status codes (UNAVAILABLE, DEADLINE_EXCEEDED, etc.)
- Connection pool exhaustion
- Certificate expiry times
The grpc-prometheus library is your friend here. But make sure your dashboards understand gRPC semantics - HTTP 200 with gRPC status UNAVAILABLE is still a failure.
The Bottom Line
Service mesh with gRPC isn't a weekend project. It's a months-long commitment to learning new debugging tools, understanding certificate lifecycles, and figuring out why Envoy decided to route all your traffic to one pod.
But once it works? Debugging distributed systems becomes so much easier. Just be prepared for the operational overhead and don't let anyone tell you it's "simple."
Start with basic load balancing. Get that working reliably. Then add mTLS. Then maybe think about advanced traffic management. The feature creep is real and every additional feature is another thing that can break at 3am.
Ready for the production configs? The next section covers the specific settings that'll keep your mesh running when real traffic hits it.
