After 6 months of pain, here's the real implementation guide. Not the sanitized documentation version, but what actually happens when you try to make these tools work together.
Prerequisites (AKA: The Stuff That Costs Money)
Required Accounts and Credentials:
Local Development Hell:
## Install Pulumi CLI - version 3.90.x as of late 2024
## Check https://www.pulumi.com/docs/install/ for latest versions
## Don't trust their \"latest\" claims in docs
## Review installation troubleshooting: https://www.pulumi.com/docs/troubleshooting/
curl -fsSL https://get.pulumi.com | sh
## Install AWS CLI v2 - v1 is deprecated and will break randomly
## Follow https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
## See migration guide: https://docs.aws.amazon.com/cli/latest/userguide/cliv2-migration.html
curl \"https://awscli.amazonaws.com/AWSCLIV2.pkg\" -o \"AWSCLIV2.pkg\"
## kubectl - get the exact version matching your cluster or suffer
## See https://kubernetes.io/docs/tasks/tools/install-kubectl/
## Version compatibility matrix: https://kubernetes.io/docs/setup/release/version-skew-policy/
curl -LO \"https://dl.k8s.io/release/v1.28.0/bin/darwin/amd64/kubectl\"
## Helm 3.x - anything before 3.10 has security vulnerabilities
## Check https://github.com/helm/helm/releases for latest secure version
## Security best practices: https://helm.sh/docs/chart_best_practices/
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
AWS Configuration Nightmare:
aws configure
## Enter your access key (rotate these monthly or get pwned)
## Default region: us-west-2 (Oregon is cheapest)
## Output format: json (yaml breaks half the Pulumi scripts)
## Security guide: https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html
## Regional pricing comparison: https://aws.amazon.com/ec2/pricing/
## Test it works
aws sts get-caller-identity
## If this fails, nothing else will work
## Troubleshooting auth: https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-troubleshooting.html
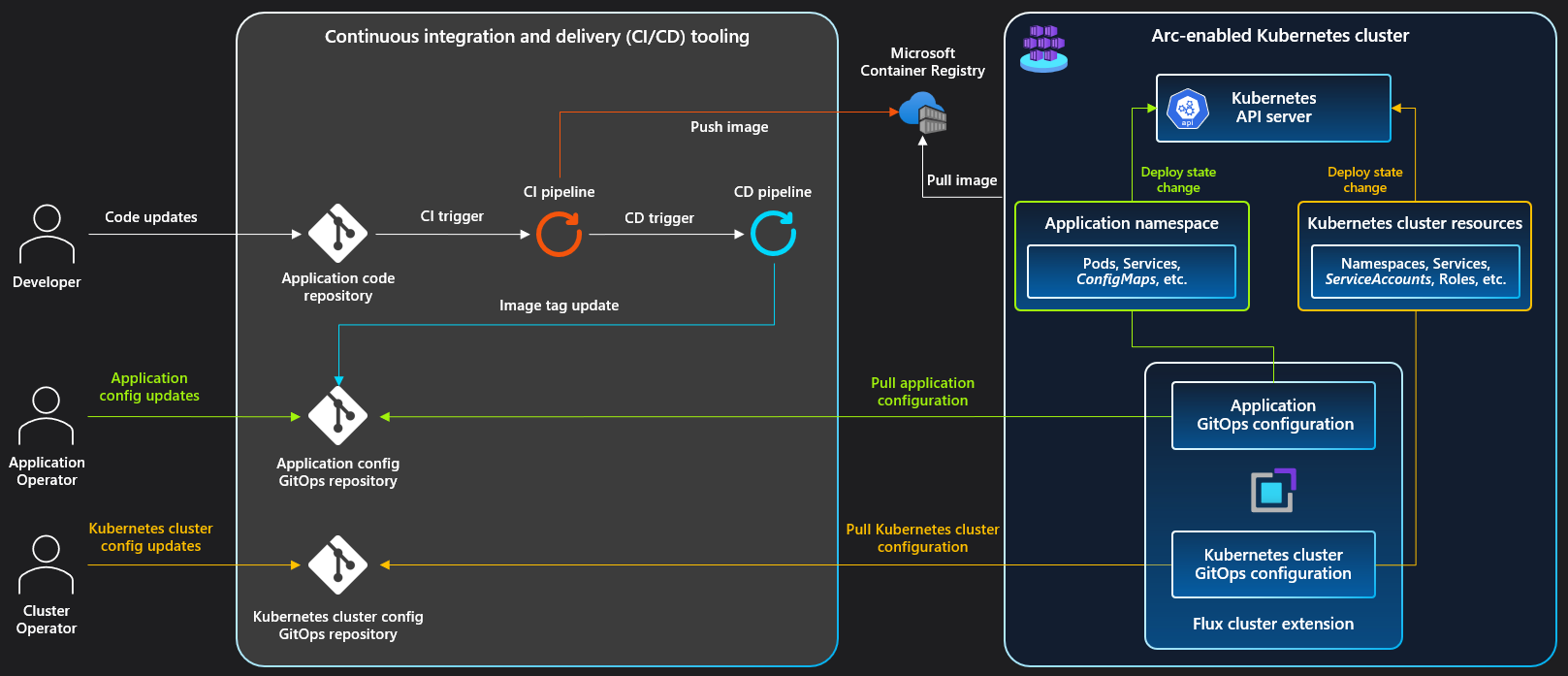
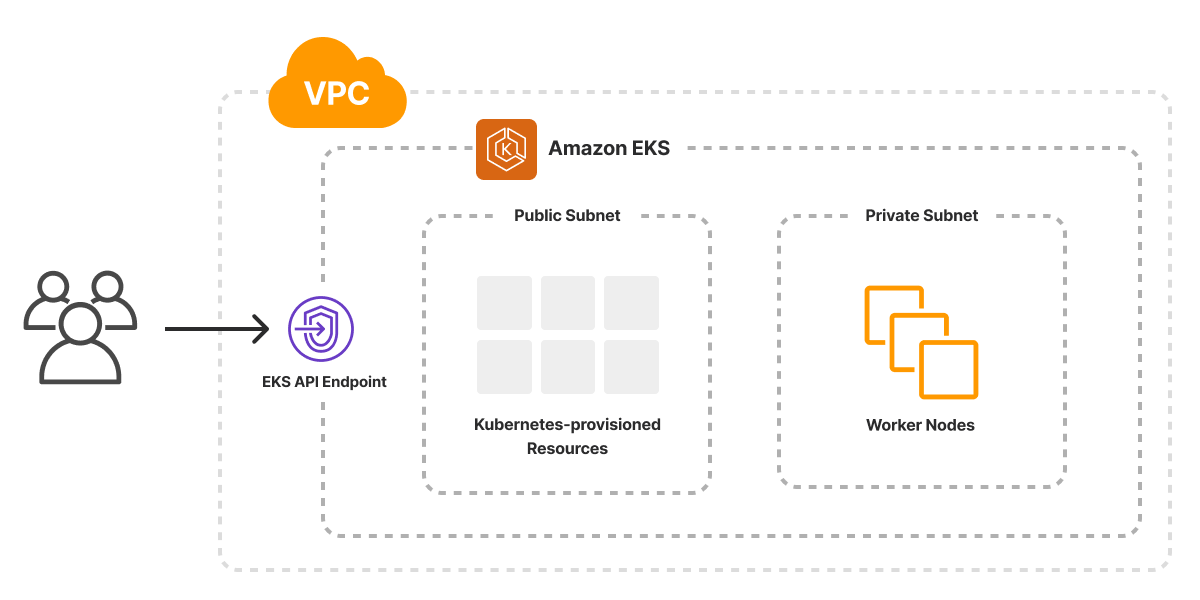
Phase 1: Creating the EKS Cluster (12-15 Minutes of Anxiety)
Initialize Pulumi Project:
mkdir pulumi-k8s-gitops && cd pulumi-k8s-gitops
pulumi new typescript
## Choose a stack name like \"dev\" - you'll regret complex names later
## Stack management guide: https://www.pulumi.com/docs/intro/concepts/stack/
## Project structure: https://www.pulumi.com/docs/intro/concepts/project/
The Infrastructure Code That Actually Works:
import * as aws from \"@pulumi/aws\";
import * as eks from \"@pulumi/eks\";
const config = new pulumi.Config();
// VPC - AWS's networking is complicated for no reason
const vpc = new aws.ec2.Vpc(\"main\", {
cidrBlock: \"10.0.0.0/16\",
enableDnsHostnames: true,
enableDnsSupport: true,
});
// Don't fucking touch the CIDR blocks - these work
const publicSubnet1 = new aws.ec2.Subnet(\"public-1\", {
vpcId: vpc.id,
cidrBlock: \"10.0.1.0/24\",
availabilityZone: \"us-west-2a\",
mapPublicIpOnLaunch: true,
});
const publicSubnet2 = new aws.ec2.Subnet(\"public-2\", {
vpcId: vpc.id,
cidrBlock: \"10.0.2.0/24\",
availabilityZone: \"us-west-2b\", // Different AZ or EKS throws a tantrum
mapPublicIpOnLaunch: true,
});
// Internet gateway - required for outbound traffic
const igw = new aws.ec2.InternetGateway(\"main\", {
vpcId: vpc.id,
});
// Route table - this is where networking gets fucky
const publicRouteTable = new aws.ec2.RouteTable(\"public\", {
vpcId: vpc.id,
routes: [{
cidrBlock: \"0.0.0.0/0\",
gatewayId: igw.id,
}],
});
// Associate subnets with route table
const publicRta1 = new aws.ec2.RouteTableAssociation(\"public-1\", {
subnetId: publicSubnet1.id,
routeTableId: publicRouteTable.id,
});
const publicRta2 = new aws.ec2.RouteTableAssociation(\"public-2\", {
subnetId: publicSubnet2.id,
routeTableId: publicRouteTable.id,
});
// EKS Cluster - this is where your credit card starts crying
const cluster = new eks.Cluster(\"gitops-cluster\", {
vpcId: vpc.id,
publicSubnetIds: [publicSubnet1.id, publicSubnet2.id],
instanceTypes: [\"t3.medium\"], // Don't go smaller, ArgoCD needs resources
desiredCapacity: 2,
minSize: 2,
maxSize: 4,
nodeAssociatePublicIpAddress: false, // Security best practice
version: \"1.28\", // Pin the version or auto-updates will break you
});
export const kubeconfig = cluster.kubeconfig;
export const clusterName = cluster.eksCluster.name;
Deploy It (And Cross Your Fingers):
pulumi up
## This takes 12-15 minutes if you're lucky
## 25+ minutes if AWS is having a bad day
## $73/month for the control plane starts billing immediately
## EKS pricing breakdown: https://aws.amazon.com/eks/pricing/
## Set up kubectl
pulumi stack output kubeconfig --show-secrets > ~/.kube/config-gitops
export KUBECONFIG=~/.kube/config-gitops
## kubectl configuration guide: https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig/
## Test it works
kubectl get nodes
## If you see 2 nodes in \"Ready\" state, celebrate briefly
## Node troubleshooting: https://kubernetes.io/docs/tasks/debug-application-cluster/debug-cluster/
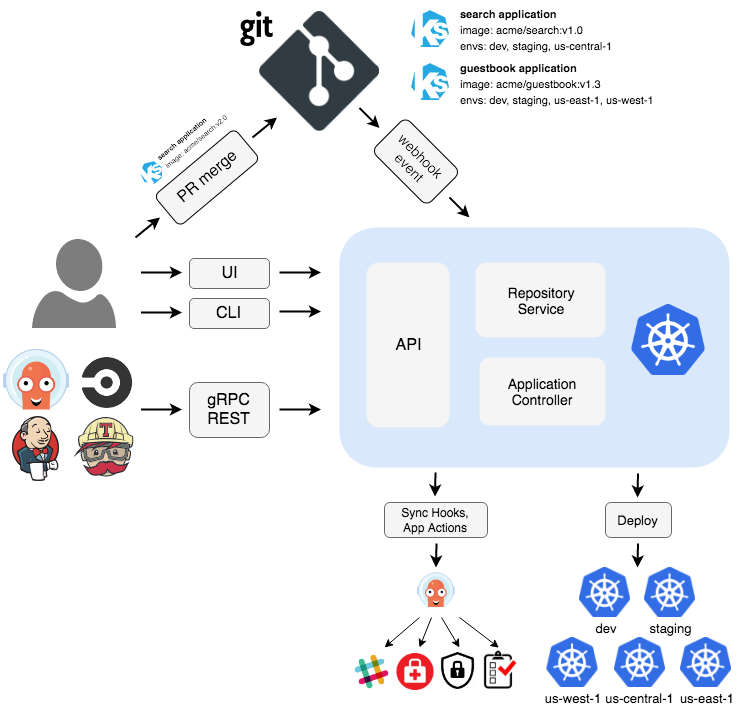
Phase 2: Installing ArgoCD (The UI That Lies to You)
Install ArgoCD via Helm (Because kubectl apply is for masochists):
kubectl create namespace argocd
## Namespace best practices: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
## Add the ArgoCD Helm repository
helm repo add argo https://argoproj.github.io/argo-helm
helm repo update
## ArgoCD Helm chart documentation: https://artifacthub.io/packages/helm/argo/argo-cd
## Install ArgoCD with sane resource limits
helm install argocd argo/argo-cd \
--namespace argocd \
--set server.service.type=LoadBalancer \
--set server.insecure=true \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.memory=2Gi \
--set server.resources.requests.memory=256Mi \
--set server.resources.limits.memory=512Mi
## Production deployment guide: https://argo-cd.readthedocs.io/en/stable/operator-manual/installation/
## Wait for the LoadBalancer to get an IP (3-8 minutes)
kubectl get svc -n argocd argocd-server --watch
## When EXTERNAL-IP shows up, you can access the UI
## LoadBalancer troubleshooting: https://kubernetes.io/docs/tasks/access-application-cluster/create-external-load-balancer/
Get ArgoCD Credentials (They Hide This):
## Get the admin password - it's auto-generated and cryptic
kubectl -n argocd get secret argocd-initial-admin-secret \
-o jsonpath=\"{\.data\.password}\" | base64 -d
## Username is always \"admin\"
## Password is some random string like \"xKz9bW2nQ8\"
Access ArgoCD UI:
## Get the LoadBalancer URL
kubectl get svc -n argocd argocd-server \
-o jsonpath='{\.status\.loadBalancer\.ingress[0]\.hostname}'
## Open it in a browser
## Login: admin / <password from above>
## The UI is slow as molasses - this is normal
Phase 3: Setting Up GitOps Repository Structure
Create Git Repository Structure:
mkdir gitops-config && cd gitops-config
git init
## Replace with your actual Git repository URL - example structure at:
## https://github.com/argoproj/argocd-example-apps
git remote add origin https://github.com/argoproj/argocd-example-apps.git
## Directory structure that doesn't suck
mkdir -p {applications,infrastructure,charts}
Application Configuration (ArgoCD Application):
## applications/webapp-dev.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: webapp-dev
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/your-org/webapp-charts
targetRevision: main
path: charts/webapp
helm:
valueFiles:
- values-dev.yaml
destination:
server: https://kubernetes.default.svc
namespace: webapp-dev
syncPolicy:
automated:
prune: true
selfHeal: true # This breaks more than it helps, but everyone enables it
syncOptions:
- CreateNamespace=true
Helm Chart for Your Application:
cd charts
helm create webapp
## Edit the generated templates - they're garbage by default
## values-dev.yaml - this is where environment-specific config goes
cat > webapp/values-dev.yaml << EOF
image:
repository: your-app
tag: \"v1.0.0\"
resources:
requests:
memory: \"256Mi\"
cpu: \"100m\"
limits:
memory: \"512Mi\"
cpu: \"500m\"
service:
type: LoadBalancer # Costs $18/month per service
## Don't set replicas to 1 in dev - you'll never catch scaling bugs
replicaCount: 2
EOF
What Goes Wrong (And How to Fix It)
ArgoCD Sync Stuck Forever:
The UI shows "Progressing" for hours. 99% of the time it's an RBAC issue.
## Check ArgoCD controller logs
kubectl logs -n argocd -l app.kubernetes.io/name=argocd-application-controller
## Common error: \"unable to create resource\" = RBAC problem
## Fix: Give ArgoCD more permissions (bad practice but works)
kubectl create clusterrolebinding argocd-admin \
--clusterrole=cluster-admin \
--serviceaccount=argocd:argocd-application-controller
Helm Release Fails:
## Check what Helm is actually doing
helm list -n webapp-dev
helm history webapp -n webapp-dev
## 90% of failures are image pull errors
kubectl describe pod -n webapp-dev
## Look for \"ErrImagePull\" or \"ImagePullBackOff\"
## Fix: Update your image tag or fix your registry credentials
ArgoCD Application Stuck "OutOfSync":
The diff view shows no differences but won't sync. This is an ArgoCD bug.
## Nuclear option: delete and recreate the application
kubectl delete application webapp-dev -n argocd
## Wait 2 minutes, then recreate it
kubectl apply -f applications/webapp-dev.yaml
Resource Quotas Exceeded:
Your pods won't schedule because you're out of CPU/memory.
kubectl describe nodes
## Look for \"Allocated resources\" section
## If you're >80% on CPU or memory, you need bigger nodes
## Quick fix: Scale down other apps or add more nodes
kubectl scale deployment unnecessary-service --replicas=0 -n some-namespace
The Monthly AWS Bill Reality Check
After running this for 30 days, expect:
- EKS Control Plane: $73
- 3x t3.medium nodes: $67
- LoadBalancers: $54 (3 services × $18 each)
- NAT Gateway: $45 (if you add private subnets)
- Data transfer: $20-40
- EBS volumes: $15-30
Total: $274-309/month for a basic setup.
Production with monitoring, logging, and backups? Easily $800+/month.
Why You'll Keep Using It Anyway
Despite all the bullshit, when this stack works:
- Push code to Git → everything deploys automatically
- Rollbacks are just
git revert followed by ArgoCD sync
- Infrastructure and applications are versioned together
- Complete audit trail of who changed what and when
- No more "works on my machine" because everything is declarative
The setup is painful, but the operational benefits are incredible. Just budget for the therapy sessions when ArgoCD randomly decides your production app is "degraded" for no reason.