Your LangChain prototype works fine on your laptop with 10 requests per day. Production with 1000 concurrent users? That's where things get interesting.
Rate limits hit differently at scale. Your dev environment with 10 requests works fine, but production with 1000 concurrent users will hit OpenAI's rate limits fast. LinkedIn uses LangGraph in production for their AI-powered recruiter, but they had to architect around these constraints.
Memory usage explodes with long conversations. LangChain keeps conversation history in memory by default. After a few hours of user sessions, your containers will eat all available RAM. I've seen teams debug mysterious OOM kills only to realize their chat history was consuming 16GB per instance.
What Companies Actually Deploy
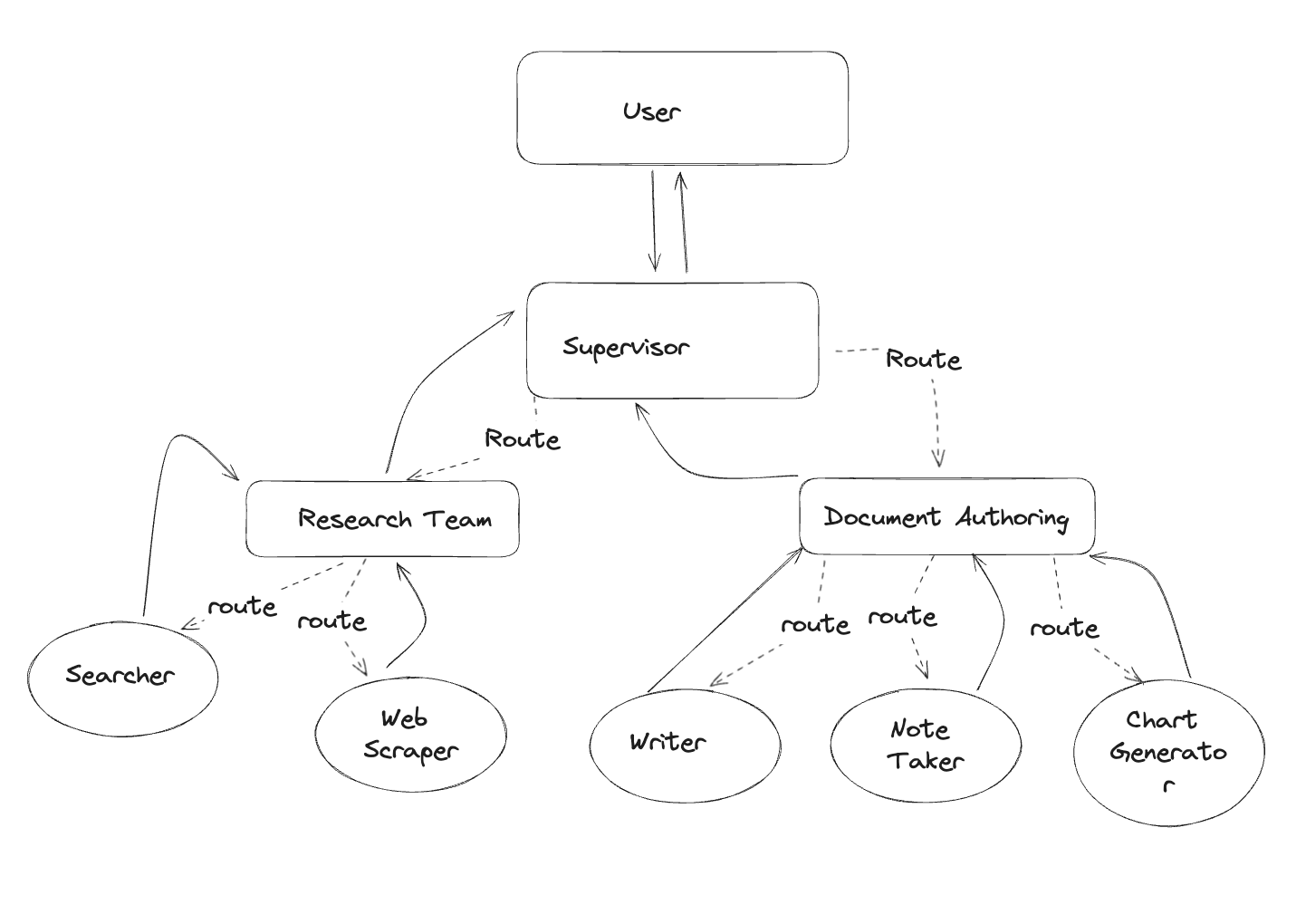
Uber integrated LangGraph to streamline large-scale code migrations within their developer platform. They didn't just plug in the examples - they carefully structured a network of specialized agents so that each step of their unit test generation was handled with precision.
Replit's AI agent acts as a copilot for building software from scratch. With LangGraph under the hood, they've architected a multi-agent system with human-in-the-loop capabilities. Users can see their agent actions, from package installations to file creation.
The pattern here? These companies built custom orchestration around LangChain components rather than using the framework as-is.
Version Migration Horror Stories
LangChain 0.3 (September 2024) broke everything. Version 0.3 dropped Python 3.8 support and switched to Pydantic 2, which broke things if you weren't careful. If you see errors like ImportError: cannot import name 'BaseModel' from 'pydantic.v1', you're hitting the Pydantic v1 to v2 migration issues.
The 0.1 to 0.2 migration was painful for a lot of teams. Router Chains completely changed their API within a week during the 0.2 development cycle. Code that worked on Monday would break by Friday with no migration guide.
Pro tip: Pin your versions. LangChain moves fast and breaking changes happen. Always use exact version pins in production:
langchain-core==0.3.0
langchain-openai==0.2.0
Not this:
langchain-core>=0.3.0
The Real Production Costs
LangChain itself is free, but LangSmith monitoring starts at $39/month per developer seat. For a team of 5 engineers with 100k traces per month, you're looking at $200+ monthly just for observability.
But that's the least of your costs. The real money goes to:
- OpenAI API calls (varies, but can hit $1000s/month)
- Vector database hosting (Pinecone starts at $70/month)
- Infrastructure costs (container orchestration, databases, monitoring)
One team I know went from $50/month to $5000 overnight because their agent got stuck calling embeddings on their entire Slack history. Set billing limits and implement circuit breakers.