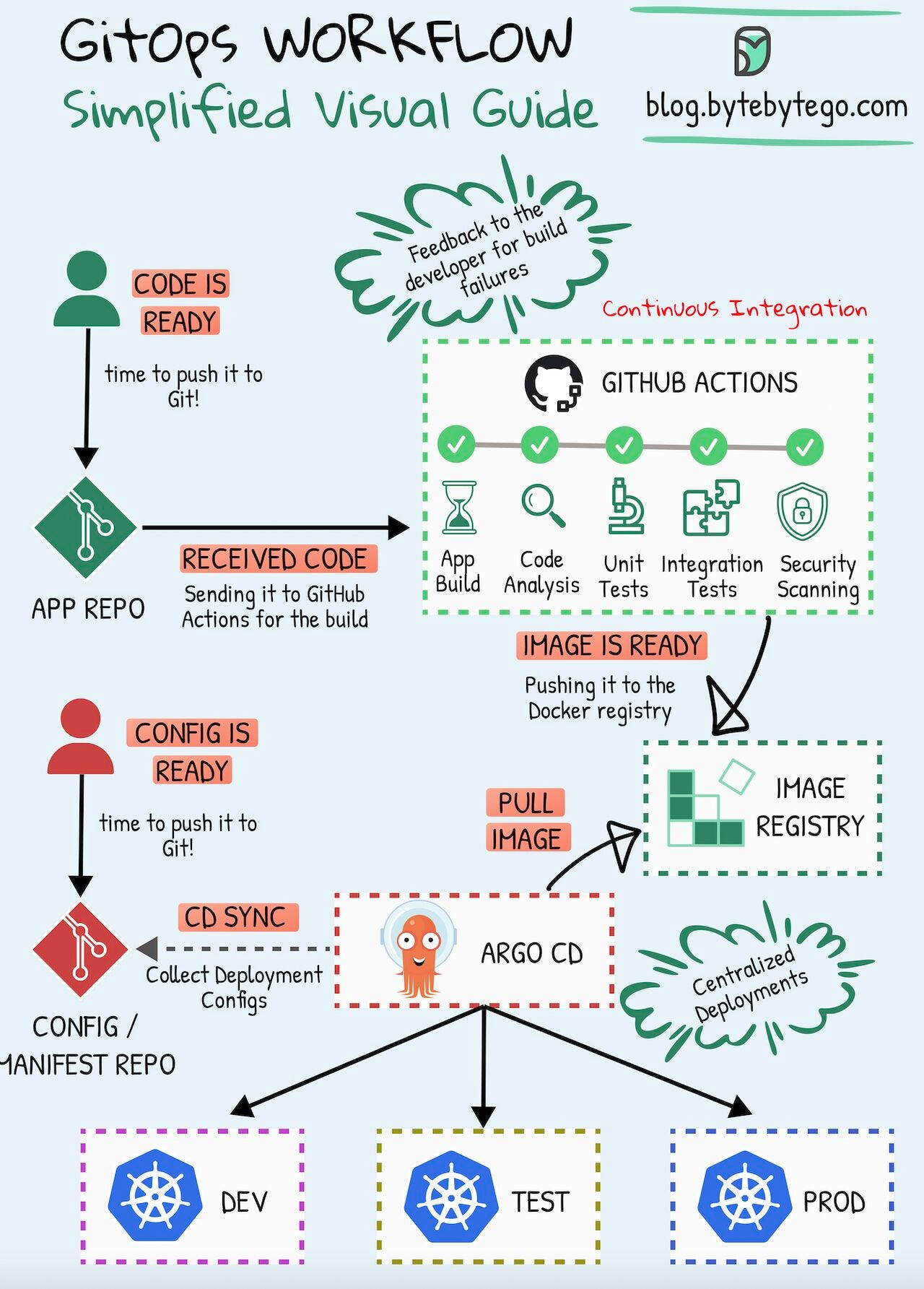
GitOps is what happens when you're tired of production breaking every Friday at 5 PM because someone manually SSH'd into a server and "just changed one little thing." Instead of praying to the deployment gods, you use Git as your single source of truth for everything running in production.
Traditional deployments are basically Russian roulette with infrastructure. Someone commits code, Jenkins (or whatever hot garbage CI/CD tool you're using) pushes it to production, and you hold your breath hoping nothing explodes. GitOps flips this - agents in your cluster pull changes from Git instead of external systems pushing shit in.
The basic idea is simple: declare what you want in Git, and agents make sure that's what's actually running. Weaveworks came up with the term back in 2017 when they got tired of SSH'ing into production Kubernetes clusters.
![]()

How GitOps Actually Works (And Why It'll Still Frustrate You)
GitOps agents are like obsessive-compulsive roommates who constantly check if everything matches what's supposed to be there. They compare your Git repo with what's actually running and fix any drift they find. This happens every few minutes, which is both amazing and terrifying when you realize how often things change without your knowledge.
The Good: When someone manually changes production (and they will, because humans are gonna human), GitOps automatically reverts it back to what Git says it should be.
The Bad: When your GitOps agent breaks, your deployments stop working, and debugging YAML at 3 AM becomes your new hobby.
The Ugly: Secret management is still a fucking nightmare because you can't put passwords in Git, so you end up with External Secrets Operator or Sealed Secrets or some other contraption that may or may not work. Add Vault into the mix and you've got another layer of complexity that will definitely break at 3 AM.
Real GitOps Gotchas Nobody Talks About
Git History Pollution: Every deployment creates a Git commit. Your repo history will look like a disaster because of all the automated commits from image updates. Hope you like scrolling through 500 commits to find that one config change from last week.
Branch Strategy Hell: Do you use branches for environments? Different repos? Overlays with Kustomize? Every approach sucks in its own way. Branch-per-environment seemed great until you're merging hotfixes across three branches at 2 AM and want to throw your laptop out the window.
Circular Dependencies: Your CI builds container images and wants to update deployment YAML, but the GitOps repo is separate from your app repo. Building workflows to update Git from Git gets complicated fast. You'll spend weekends debugging webhook failures.
Resource Limits: GitOps agents store the entire desired state in memory. When you have a bunch of microservices with massive Helm charts, Argo CD starts eating RAM like it's going out of style. Flux is lighter but scale beyond a thousand apps and you'll hit limits.
Why You'll Use GitOps Anyway
Despite all the pain points, GitOps is still better than the alternative. The 2023 CNCF survey shows 91% adoption because:
- Audit Trail: You can actually trace what changed and when, instead of playing detective after production dies
- Rollback Sanity:
git revertbeats "uh, what version were we running before?" - No More SSH: Your ops team stops logging into production servers to "fix things quickly"
- Drift Detection: You find out when someone broke the rules instead of discovering it during the next outage
The learning curve is brutal, the tooling is immature, and you'll question your life choices regularly. But once it's working, you'll never go back to pushing deployments from your laptop.