
KEDA (Kubernetes Event-driven Autoscaler) is a CNCF graduated project originally created by Microsoft and Red Hat. The latest version is v2.17.2, released in June 2024, and it fixes Kubernetes' biggest autoscaling fuckup: scaling based on metrics that actually matter.
The Problem: CPU Metrics Are Bullshit
Traditional Kubernetes Horizontal Pod Autoscaler (HPA) only looks at CPU and memory. That's like judging a restaurant's popularity by how hot the kitchen gets. Your message queue could have 10,000 pending jobs, but if your workers aren't pegging CPU, HPA doesn't give a shit.
I learned this the hard way when our Redis queue went completely nuts - had to be 40-something thousand messages, maybe 50k? Hard to say exactly - and HPA just sat there like a useless brick while our response times turned to absolute shit. CPU was fine, so why scale?
How KEDA Actually Works
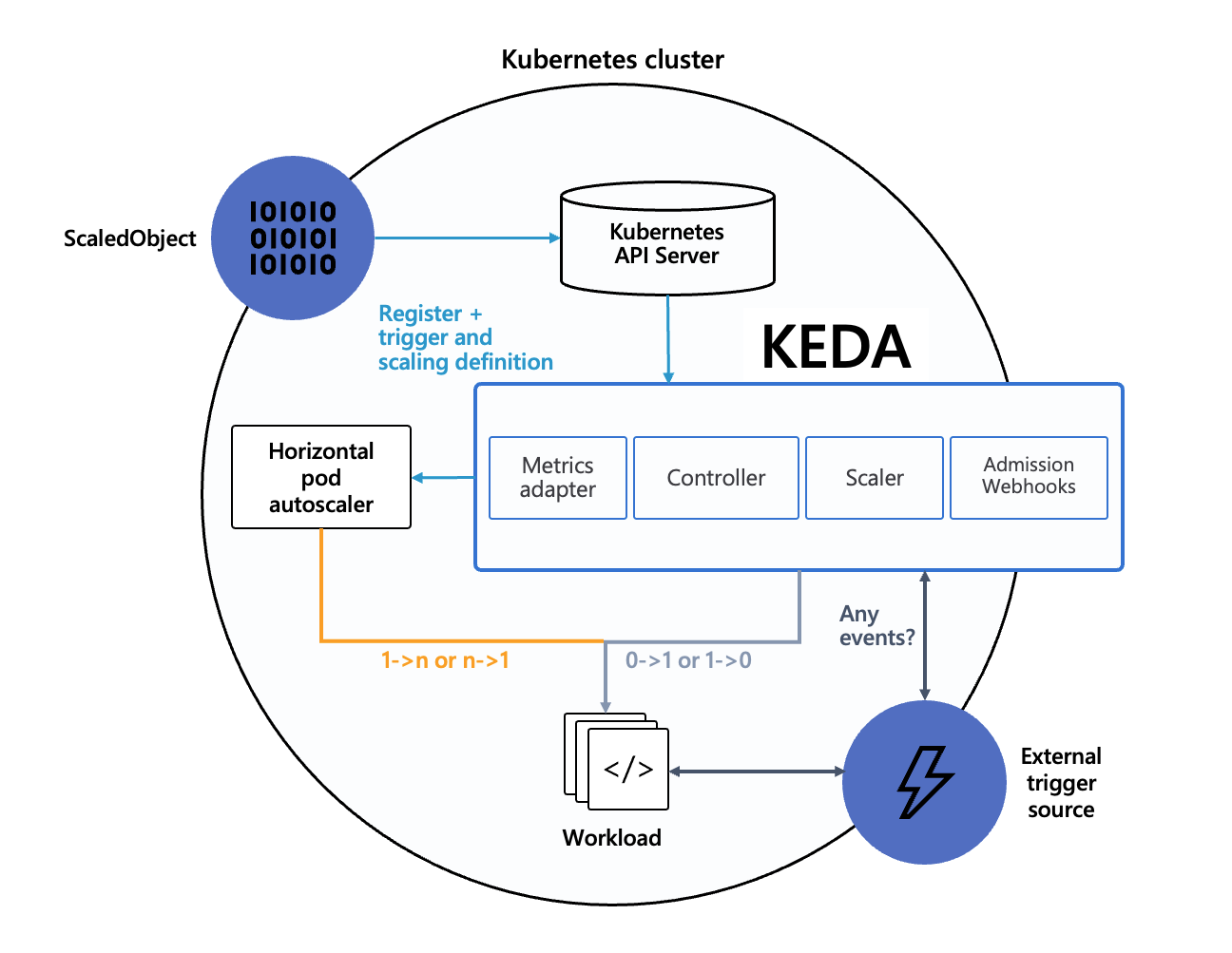
KEDA has three components that don't suck:
KEDA Operator monitors external stuff - your message queues, databases, whatever. It creates ScaledObjects and ScaledJobs that actually make sense for your workload.
Metrics Server translates external metrics into something Kubernetes HPA can understand. It's basically the middleware that makes KEDA play nice with existing K8s autoscaling.
Scalers connect to 60+ external services including Apache Kafka, Redis, RabbitMQ, AWS SQS, Azure Service Bus, Prometheus, and tons more.
Scale-to-Zero: Actually Useful
KEDA can scale your pods to zero when there's no work. Not "minimum 1 replica" - actual zero. When messages show up in your queue, it spins up pods in about 30 seconds (don't believe the "within seconds" marketing BS).
This saved us maybe 60% on our staging environment costs, hard to say exactly. Production? That's where you learn the hard way that your startup time is actually like 45 seconds on a bad day, not the 5 seconds you thought, and users start bitching about timeouts.
Real Production Gotchas Nobody Tells You
KEDA operator resource usage: The docs say 200MB RAM but that's bullshit. Plan for at least 400-500MB RAM, probably more if your cluster decides to be an asshole. Each scaler hammers your APIs every 30 seconds - hope you like those sweet, sweet cloud provider API bills.
Scale-to-zero timing: That "within seconds" claim? Complete bullshit. Expect like 30-60 seconds for the first pod, maybe longer if your image is huge. If you need sub-5-second response times, scale-to-zero will piss off your users.
Event source failures: If your Redis/Kafka/whatever goes down, KEDA keeps your app at current scale. It doesn't freak out and scale to zero, which is actually pretty smart.
Authentication debugging: TriggerAuthentication fails silently like a passive-aggressive coworker who leaves you Post-it notes about your failures instead of just telling you. You'll spend 6 hours debugging why your ScaledObject sits there doing absolutely nothing, only to discover you fat-fingered the secret name. Again. Always check kubectl logs -l app=keda-operator -n keda first, not after you've already questioned your career choices.
When KEDA Actually Makes Sense
- Event-driven workloads (message queues, batch processing)
- Variable traffic patterns where CPU scaling is useless
- Cost-sensitive environments where scale-to-zero matters
- Integration with cloud services that HPA can't see
KEDA works with Deployments, StatefulSets, and Jobs, plus any custom resource that implements the /scale sub-resource. It plays nice with existing VPA and other Kubernetes tools.
Anyway, here's how KEDA compares to the other autoscaling options that probably aren't working for you either.