Here's the thing about RHACS architecture - get it wrong early and you'll spend the next two years fixing it while security violations pile up and executives ask why their fancy security platform can't tell them if they're actually secure.
I've seen teams waste six months trying to retrofit their architecture because they didn't think through multi-cluster networking. Don't be those teams. At my last job, we had to rebuild everything because someone decided to ignore the networking design and just "figure it out later." Spoiler: later sucked.
Hub-and-Spoke vs. Federated Central Models
RHACS uses a distributed architecture where Central services manage multiple secured clusters through Sensor agents. For enterprise deployments, you have two primary architectural approaches that will make or break your deployment:
Single Central Hub (Works Until It Doesn't)
- One Central trying to babysit all your clusters
- Looks simple until Central dies at 3am and nobody can deploy anything
- You need serious hardware: 16+ cores, 32+ GB RAM, 1TB+ storage (budget 2x what Red Hat's sizing guide says because it's always wrong)
- Every cluster needs to phone home on port 443 (good luck with your corporate firewall team)
- Perfect for teams that like single points of failure and 3am pages
Regional Central Federation (The Adult Option)
- Multiple Central instances that don't all die simultaneously
- Each one handles 50-150 clusters before choking (tested this the hard way with 200+ clusters)
- Actually works when your European data center loses internet connectivity
- More shit to manage but you won't get fired when one region implodes
- Mandatory if you have air-gapped clusters or compliance people who actually read frameworks
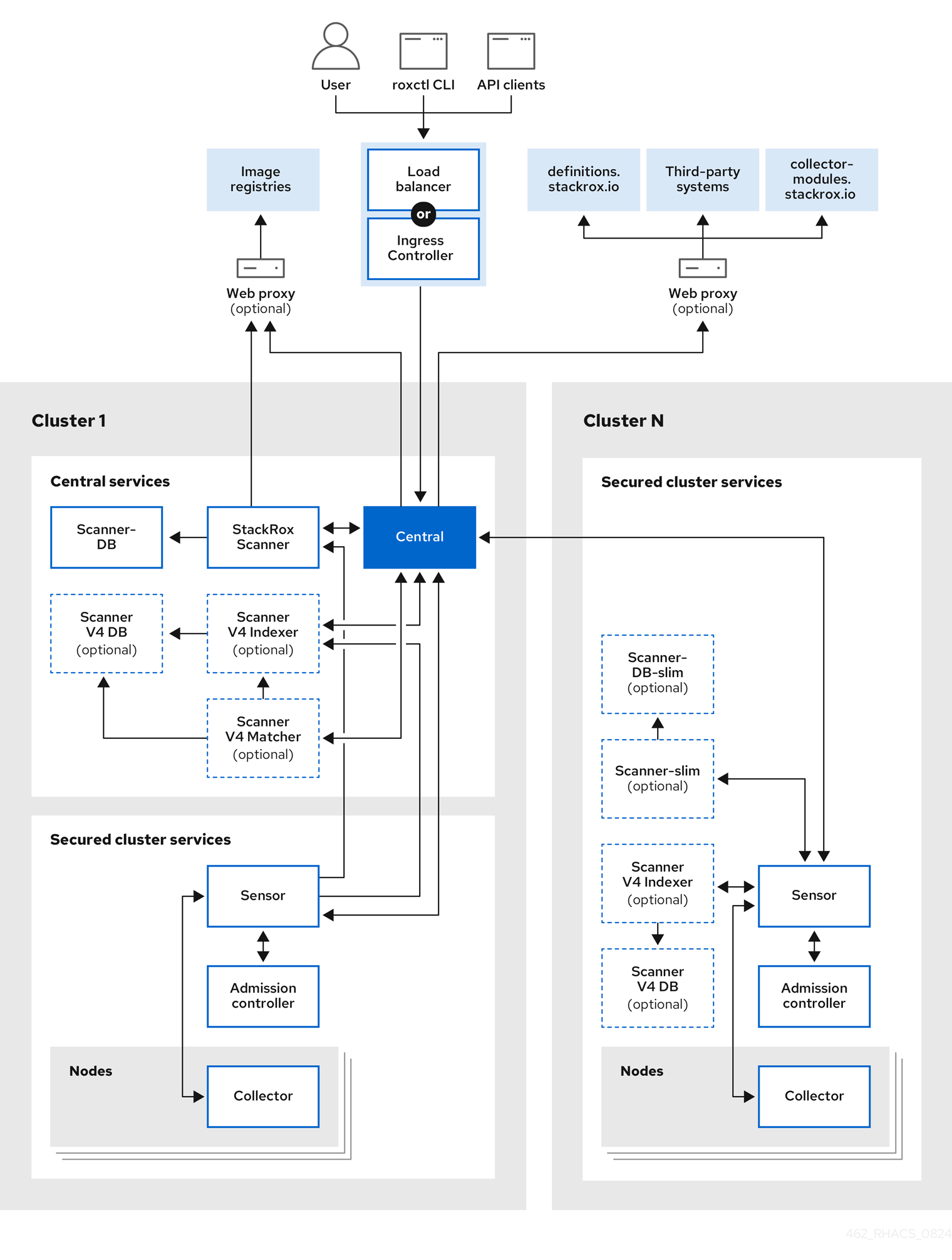
Central Placement Strategy
Dedicated Security Cluster (Do This)
- Put Central on its own cluster so app deployments can't kill your security monitoring
- When devs break production, your security tools still work
- Easier to explain to auditors why your security platform is actually secure
- Size it properly: 3 nodes minimum, 16 vCPU/32GB RAM each (or watch it die under load like mine did last month)
- Storage will eat your budget: 2TB+ for Central DB, 1TB+ for Scanner (and growing fast - we're at 3TB now)
Shared Management Cluster (The Cheap Option)
- Cram RHACS onto the same cluster as RHACM to save money
- Works fine until both tools fight for resources during a security incident
- Perfect for when your CFO cares more about costs than uptime
- Requires constant babysitting and resource tuning
Network Architecture (AKA Firewall Hell)
Here's where your network team will hate you. RHACS needs specific ports open and your enterprise firewall rules probably block half of them.
Central to Secured Clusters (The Fun Part):
- Port 443: Sensors phone home constantly (prepare for "why is there so much traffic?" questions)
- Port 8443: API access for roxctl and CI/CD (don't forget to document this or your automation will break)
Within Central Cluster (The Easy Part):
- PostgreSQL: Keep internal (obviously - exposing your security database to the internet is a resume-generating event)
- Scanner: Keep internal (unless you want vulnerability data leaking to places it shouldn't)
- Central UI: External access required (good luck with your load balancer configuration and certificate bullshit)
Air-Gapped Deployments (Maximum Pain Mode):
- Scanner needs to sync vulnerability databases offline (50-100GB of fun)
- Internal CA certificates that expire at the worst possible moment (usually during vacation)
- Scanner V4 database mirroring will eat storage like crazy - I've seen it go from 50GB to 200GB in a month
- Plan for certificate hell and prepare to become best friends with your security team
High Availability Design
Central High Availability:
- Central StatefulSet with persistent storage (not yet clustered)
- Database backup strategy: PostgreSQL dumps every 6 hours minimum
- Recovery time objective: Target 1-4 hours with proper backup/restore procedures
- Single point of failure: Central DB cannot be clustered yet
Sensor High Availability:
- Sensors automatically reconnect to Central after network outages
- Policy cache enables limited offline operation (24-48 hours)
- Multiple Sensor replicas for large clusters (1000+ nodes)
- Node affinity to spread Sensors across availability zones
Scanner Architecture at Scale
Scanner V4 vs StackRox Scanner:
Look, Scanner V4 is finally stable enough for production (took them long enough). It's way better than the old scanner, though it'll still peg your CPU when scanning those 2GB images that developers somehow think are reasonable. SBOM generation is required for compliance frameworks - auditors fucking love this feature. Language-specific vulnerability detection covers Go, Java, Node.js, Python, Ruby - basically everything your devs are throwing at production these days.
Delegated Scanning Strategy:
- Enable Scanner on secured clusters for registry-local images
- Central Scanner for shared/external registries
- Reduces network traffic and scanning latency
- Each secured cluster needs 2-4 CPU cores, 4-8GB RAM for Scanner
Registry Integration Patterns:

- Quay integration: Webhook-based scanning
- Harbor, Artifactory: API-based integration
- Air-gapped registries: Manual certificate and credential management
This architectural foundation determines your operational model, scalability limits, and disaster recovery capabilities. With your architecture decided, the next critical question becomes: how much hardware do you actually need to support your deployment scale? The sizing decisions you make now will directly impact your monthly cloud bills and operational complexity.