API was running like garbage. Spent 4 hours debugging just to find out one customer had some fucked up edge case data. That's exactly the shit that Charity Majors and her team at Honeycomb got tired of dealing with. They built something that actually helps you debug instead of just pretty dashboards that tell you everything's broken.
The Real Problem With Traditional Monitoring
Traditional monitoring tools make you predict what you'll need to monitor, which is complete bullshit. You set up dashboards for CPU, memory, response time - the usual suspects. Then at 3am when production melts down, you're frantically switching between Grafana, ELK stack, and Jaeger wondering what the fuck happened while your users are tweeting about how your app is garbage.
The problem isn't that these tools suck - they don't. The problem is they force you to pre-aggregate data. So when something weird happens (and weird shit ALWAYS happens in production), you don't have the context you need. You're basically debugging blindfolded.
Had this weird memory leak. Only happened weekends, took us forever to figure out why. Turns out our Saturday batch job was doing something stupid with active user sessions that nobody expected. Traditional metrics would have never caught that correlation.
How Honeycomb's Events Actually Work
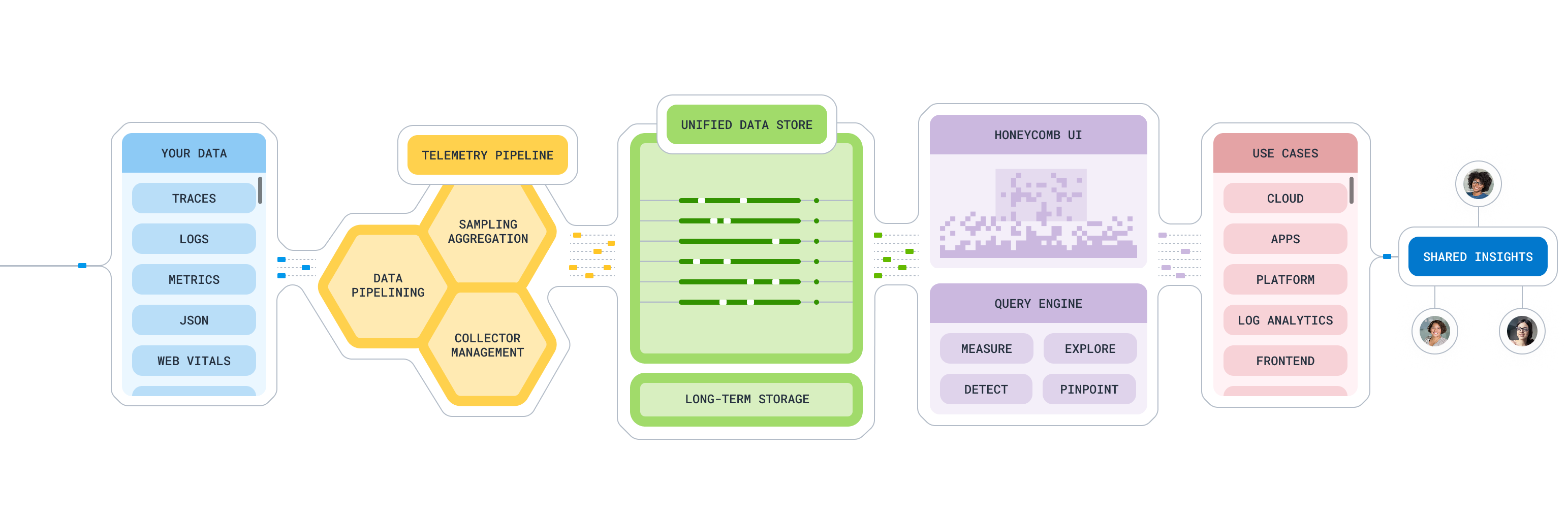
Instead of forcing you to choose between logs, metrics, or traces, Honeycomb stores everything as structured "wide events" that can contain hundreds or thousands of attributes. Think of it like this: instead of having separate time series for CPU, memory, request duration, user ID, feature flag state, etc., you get one event with ALL that context.
This means you can:
- Query billions of events in under 3 seconds (no, seriously)
- Ask questions you didn't think to ask beforehand
- Correlate anything with anything else without joins or complex queries
- Actually find the needle in the haystack instead of guessing
The first time I queried a billion events and got results instantly, I thought it was cached. Nope, that's just how their storage engine works.
Features That Don't Suck
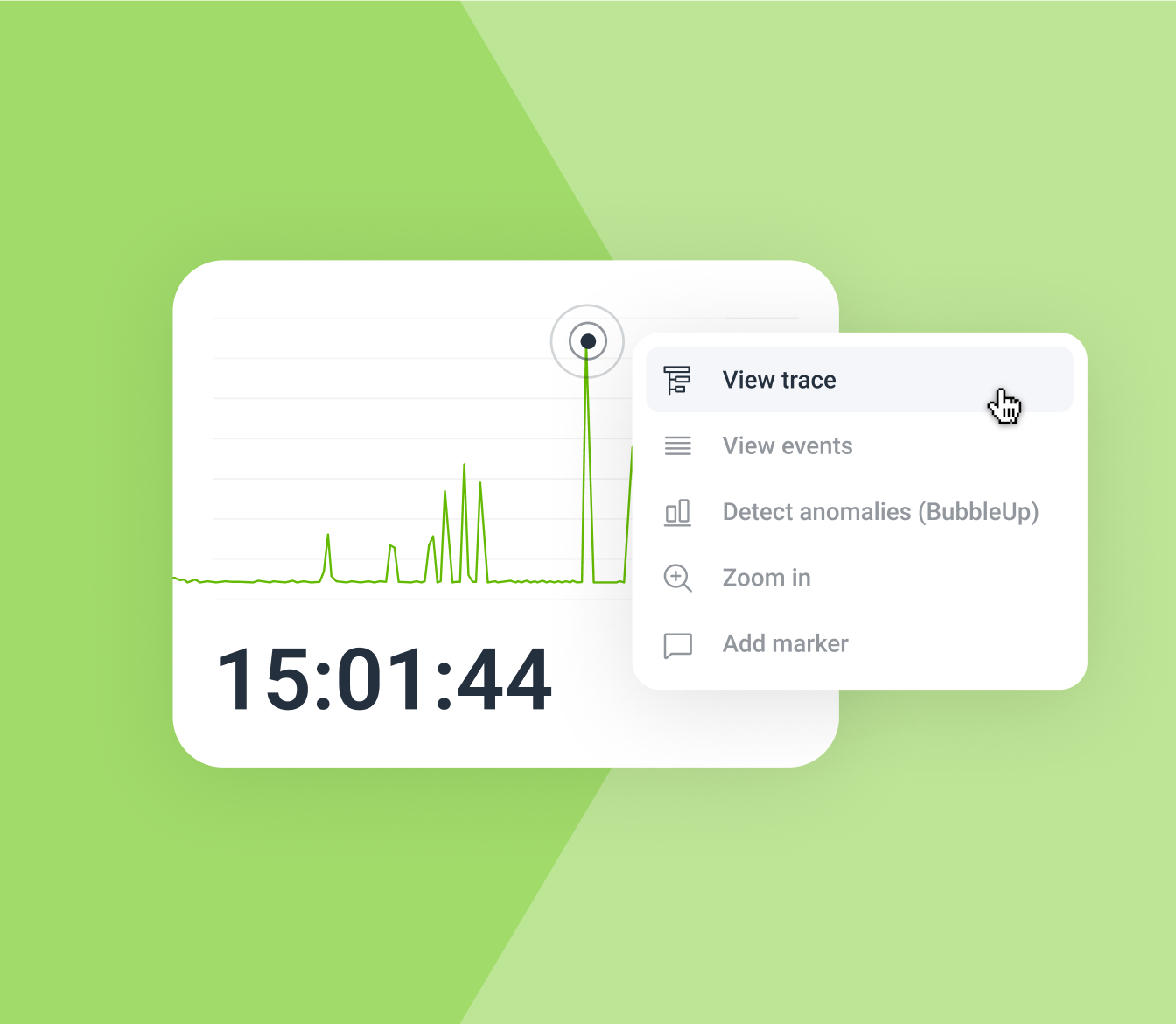
BubbleUp - The Thing That Finds Weird Shit
BubbleUp automatically finds unusual patterns in your data. Not "CPU is high" but "CPU is high specifically for requests from mobile users in the EU using feature flag X." It shows you exactly which combinations of attributes are behaving abnormally.
I've used it to find everything from a memory leak caused by a specific browser version to performance issues that only affected users with names starting with 'Q' (don't ask, long story involving a really dumb caching bug).
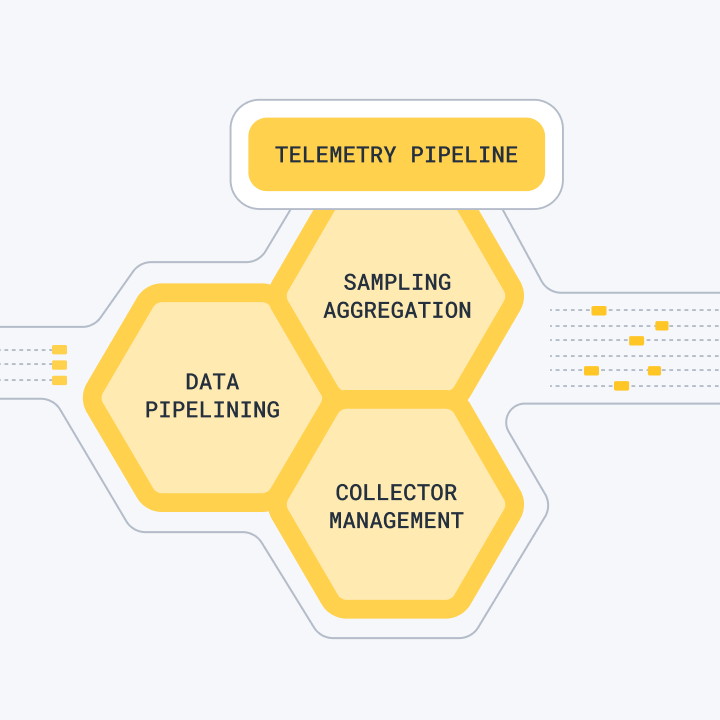
OpenTelemetry Integration That Actually Works
As a native OpenTelemetry platform, Honeycomb supports 40+ languages without the usual configuration nightmare. Unlike other tools that claim OTel support but make you jump through hoops, Honeycomb was literally built for it.
Setup takes 10 minutes instead of the usual 3-day configuration nightmare. The automatic instrumentation actually works, which is more than I can say for most APM tools.
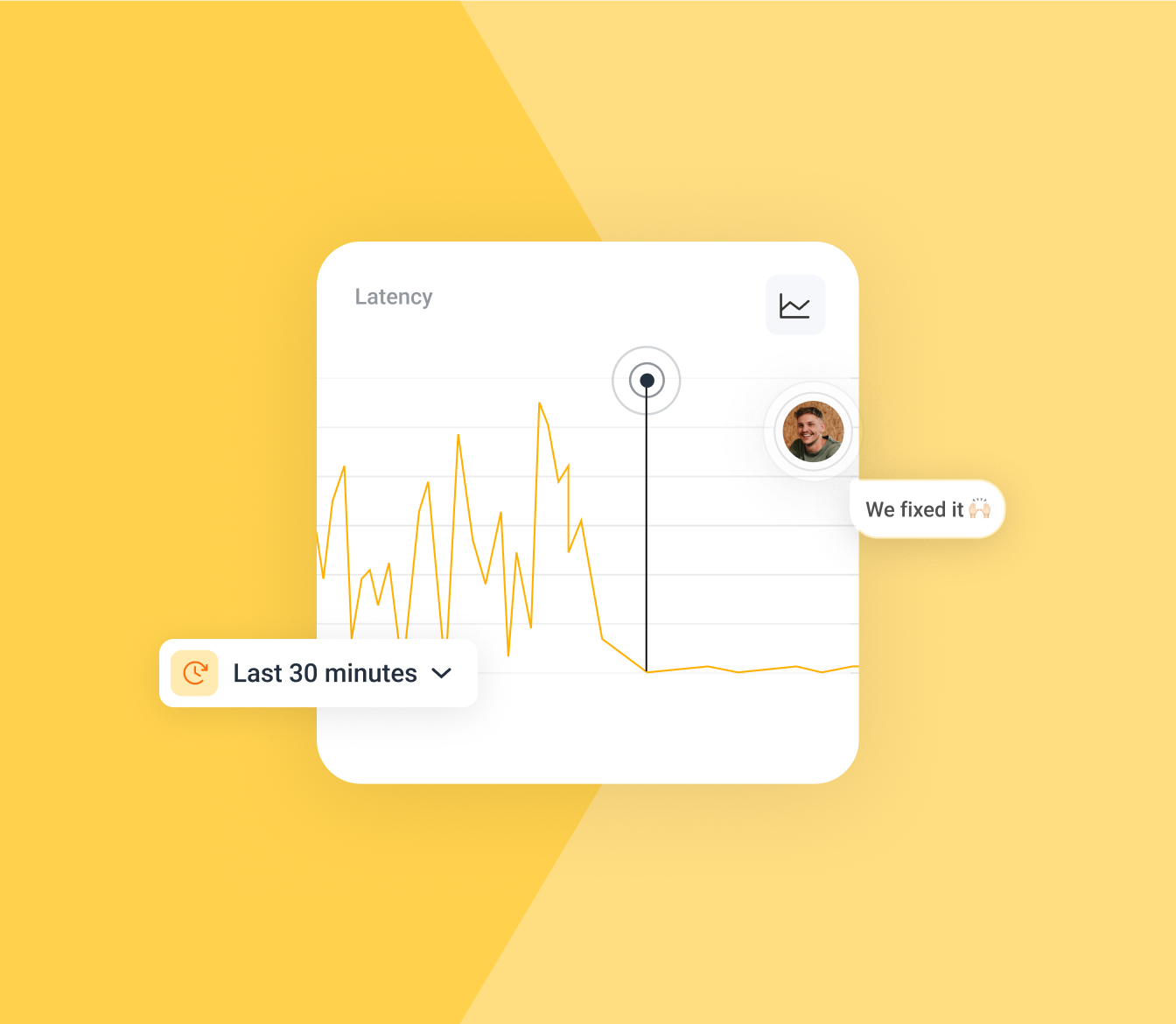
SLOs That You Can Actually Debug
Their SLO functionality isn't just pretty charts. When your error rate spikes, you can click through and see exactly why. Is it a specific endpoint? Certain user cohort? Database timeout? You get answers, not more questions.
Who Actually Uses This
Companies like Dropbox use Honeycomb because their engineers got tired of debugging production with multiple tools that don't talk to each other. These aren't companies with unlimited budgets throwing money at problems - they're engineering-first organizations that need shit that actually works when production is burning down and users are pissed.
If you've ever been woken up at 3am by a production issue and spent 2 hours switching between different monitoring tools trying to figure out what broke, Honeycomb is for you.
Current Status: Gartner Recognition
As of September 2025, Honeycomb has been recognized as a Visionary in the 2025 Gartner Magic Quadrant for Observability Platforms. What this really means is that even the Gartner analyst crowd is starting to realize that maybe storing pre-aggregated metrics isn't the best approach for debugging modern distributed systems. About fucking time.
 Yeah, it's actually that fast. I keep expecting it to timeout like every other tool, but it just... works. Faster than Splunk will ever be. The first time I did a complex aggregation across 100GB of data and got instant results, I thought it was cached. It wasn't
Yeah, it's actually that fast. I keep expecting it to timeout like every other tool, but it just... works. Faster than Splunk will ever be. The first time I did a complex aggregation across 100GB of data and got instant results, I thought it was cached. It wasn't  Honeycomb has
Honeycomb has