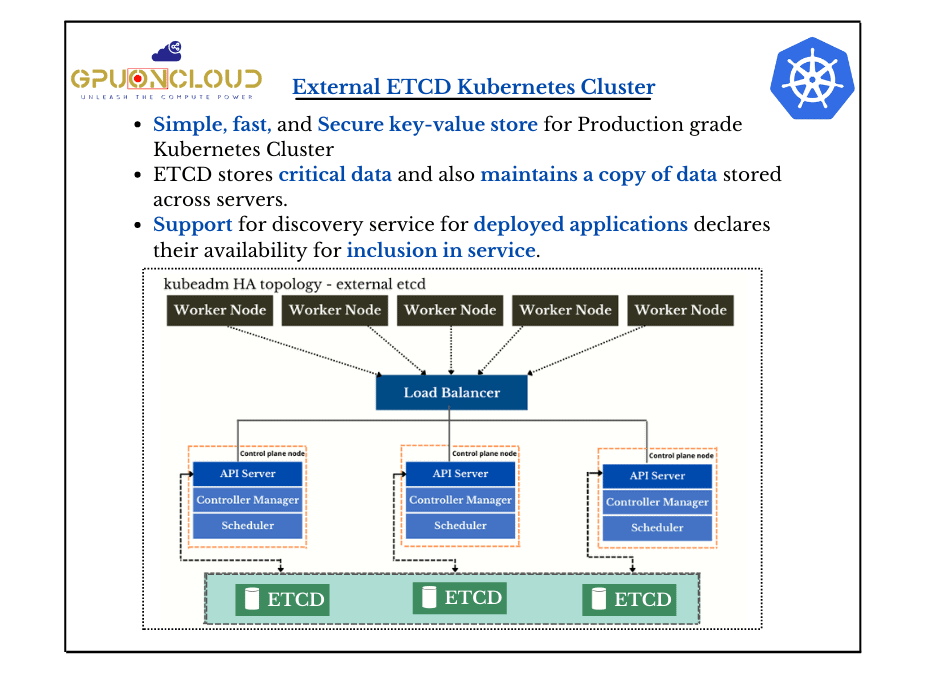
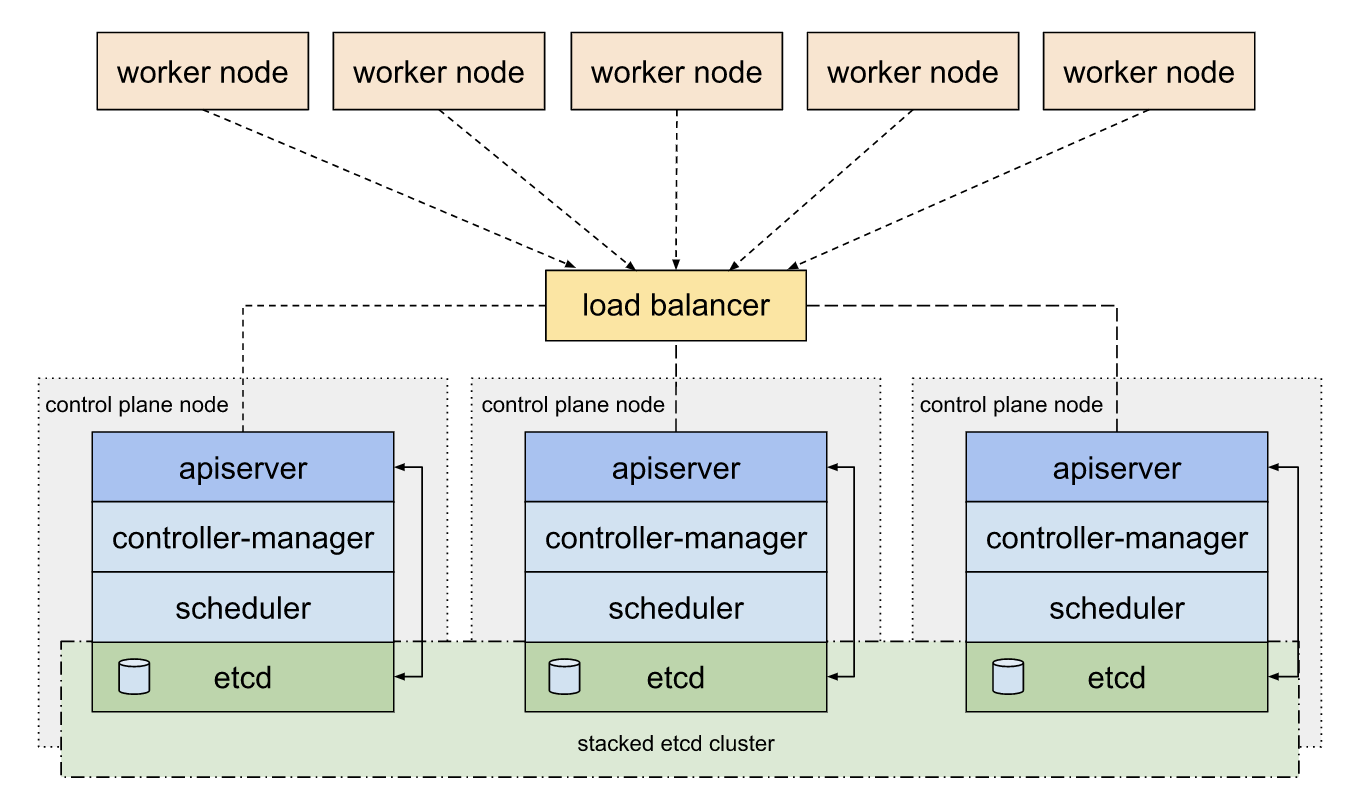
etcd stores the stuff that keeps distributed systems working - think of it as a shared brain for your cluster that occasionally gets amnesia. Originally built by CoreOS before Red Hat ate them, it's now a CNCF project that everyone uses and no one wants to debug.
The name comes from Unix's /etc directory plus "d" for distributed - because someone thought "hey, let's take the folder where all the important config lives and make it work across multiple machines with consensus algorithms." What could go wrong?
Why etcd Exists and Why You Can't Avoid It
etcd uses the Raft consensus algorithm to make sure all your nodes agree on what's true. This sounds great until you realize that "strong consistency" means your writes can completely stop during network hiccups while the cluster has an identity crisis about who's in charge.
The original etcd whitepaper explains why we needed another distributed key-value store, but the real reason is that ZooKeeper's complexity was driving people insane with JVM heap tuning and Jute protocol debugging.
During leader elections, your entire cluster becomes temporarily unavailable for writes while nodes vote on who gets to be in charge next. It's like a distributed democracy, except when there's an election, nobody can get anything done.
Unlike Redis or other eventually-consistent stores, etcd won't lie to you about data freshness. Every read gets you the latest committed write, which is fantastic for cluster state but will bite you in the ass when availability matters more than consistency.
The etcd Guarantee: Your data is either perfectly consistent across all nodes, or your writes are completely fucked until the cluster sorts itself out. No middle ground.
Features That Actually Matter in Production
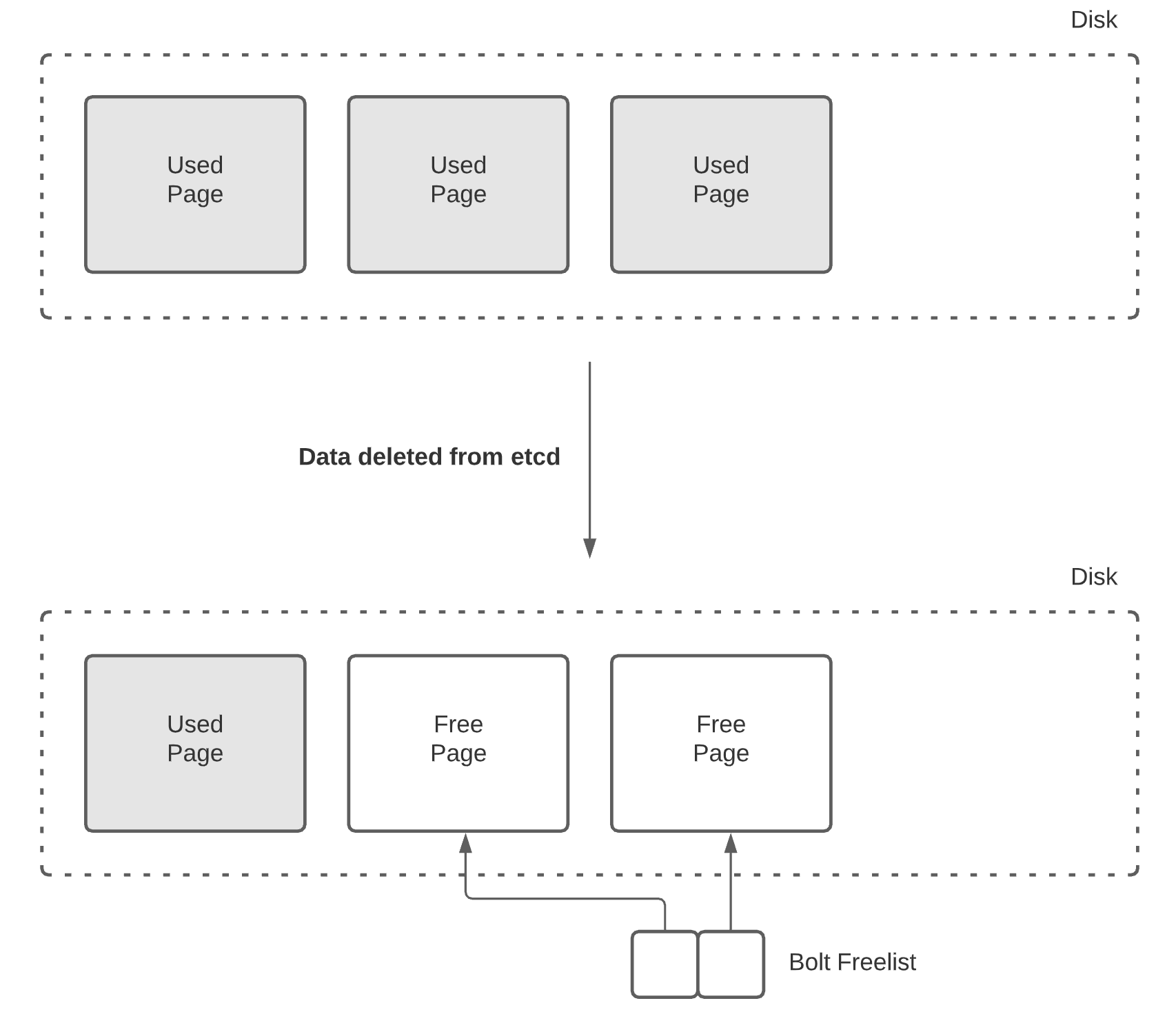
Multi-Version Concurrency Control (MVCC): etcd keeps old versions of your data around so you can see what changed when. This is brilliant for debugging disasters and implementing atomic transactions that don't leave your system in a half-broken state. Unlike MySQL's MVCC that gets confused with long-running transactions, etcd's revision-based approach is actually sane.
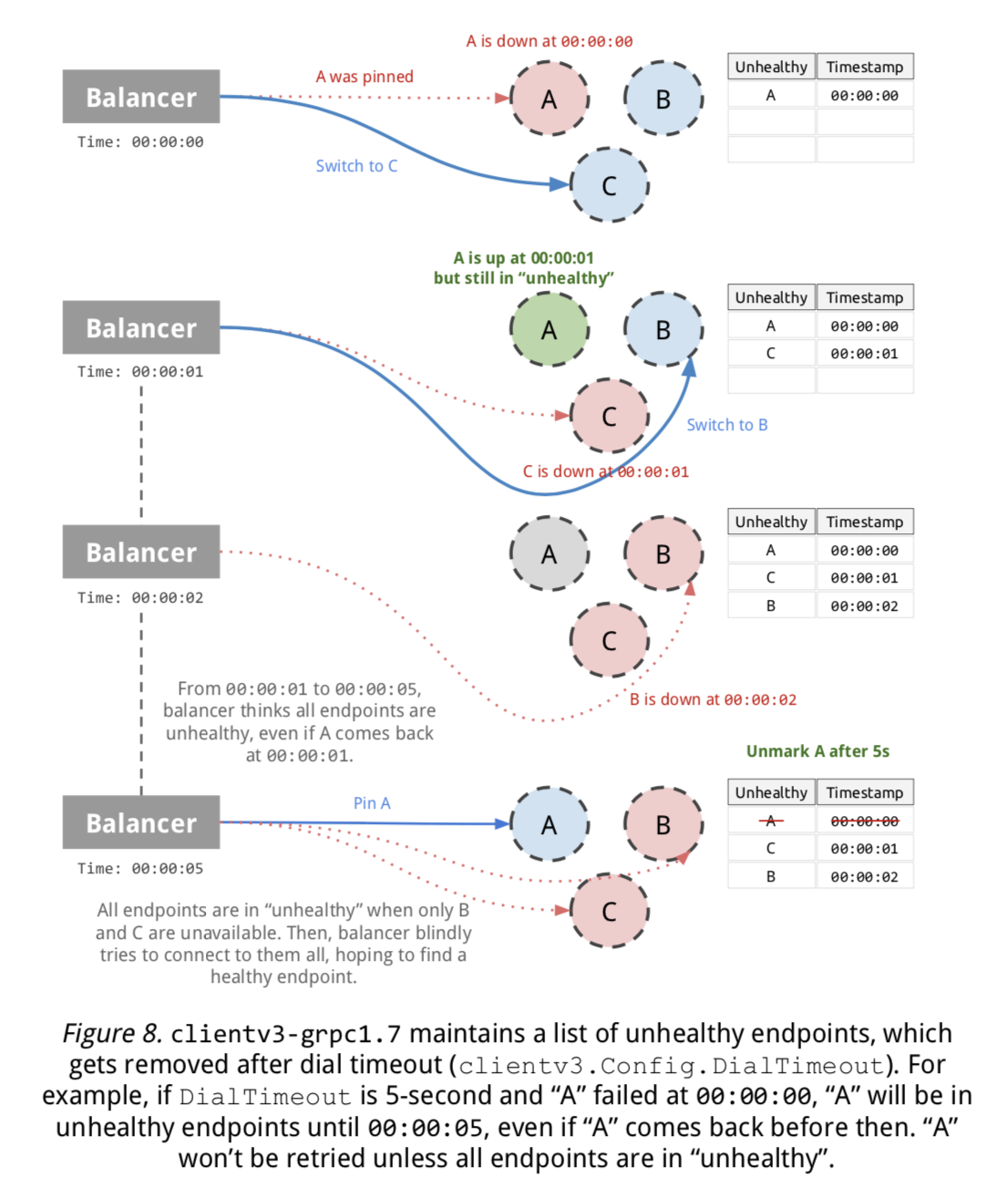
Watch Events: Instead of polling etcd every few seconds like a maniac, you can watch for changes and get real-time notifications. Works great until you have a network partition and miss half the events. The watch implementation uses gRPC streaming, which is infinitely better than WebSocket-based solutions that fall apart under load.
Lease System: Built-in TTL support for distributed locks and leader election. Your services can grab a lock, do their thing, and automatically release it if they crash. Much better than Redis-based locking that leaves you with orphaned locks from dead processes, or DynamoDB's conditional writes that cost you money every time they fail.
etcd v3.6 - Actually Fixed Some Shit
etcd v3.6 fixed some annoying shit that made earlier versions painful:
- Memory leaks mostly gone: v3.5 would slowly eat 2GB+ RAM over weeks. v3.6 doesn't do this as much, though you still need to watch memory usage.
- Better disk handling: Fewer random timeouts when storage gets slow. Still needs fast SSDs though.
- Can actually downgrade: If v3.6 breaks your production, you can roll back to v3.5 without rebuilding the entire cluster.
Real talk: The robustness testing they added uncovered a bunch of edge cases that could cause data inconsistency. These Jepsen-style tests found issues that traditional unit tests completely missed. etcd v3.6 is probably the most stable version they've ever released, which isn't saying much if you've dealt with earlier versions.
The project now has 5,500+ contributors from 873 companies, which means either everyone loves etcd or everyone needs it to work and is contributing fixes for their own survival. The GitHub activity shows this isn't some abandoned project - there are real people fixing real problems.
Anyway, here's where it gets painful. Production etcd will teach you why distributed systems suck.