
Service mesh puts a proxy next to every one of your services that intercepts all network traffic. Think of it as having a bouncer at every microservice's door who handles authentication, load balancing, and metrics collection.
The Two Parts That Matter
Data Plane: The actual proxies doing the work. Istio uses Envoy proxies that eat about 200MB of RAM each. Linkerd built their own proxy in Rust because Envoy is a resource hog. These proxies sit in sidecar containers next to your app and intercept every HTTP request.
Control Plane: The brain that tells all the proxies what to do. It pushes config changes, traffic policies, and security rules to the data plane. When the control plane goes down, your proxies keep working with their last known config, but you can't make changes until it's back up.
Sidecar Reality Check
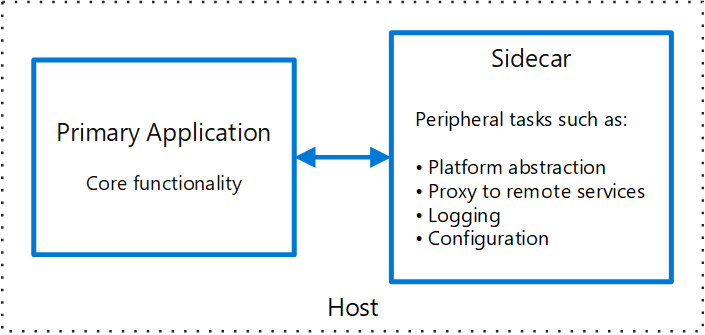
Every pod gets an extra container running a proxy. This means:
- Your memory usage doubles (minimum)
- Local development becomes a pain in the ass
- Debugging requests now involves 4+ proxy hops
- Container startup time increases
The upside is you get mTLS, load balancing, and metrics without changing your app code. Whether that trade-off is worth it depends on how much inter-service communication hell you're already in.
Traffic Interception Magic
Service mesh uses iptables rules to redirect your pod's network traffic through the sidecar proxy. When Service A calls Service B, the flow looks like:
Service A → A's sidecar → Network → B's sidecar → Service B
Each hop adds latency (typically 1-5ms) and gives the proxy a chance to apply policies, collect metrics, or reject the request entirely. This is great for security and observability, terrible for debugging when something goes wrong.
Some newer approaches like Istio's Ambient Mesh are trying to reduce the sidecar overhead by using shared node-level proxies instead. Still experimental, but could fix the resource usage problem if they get it right.