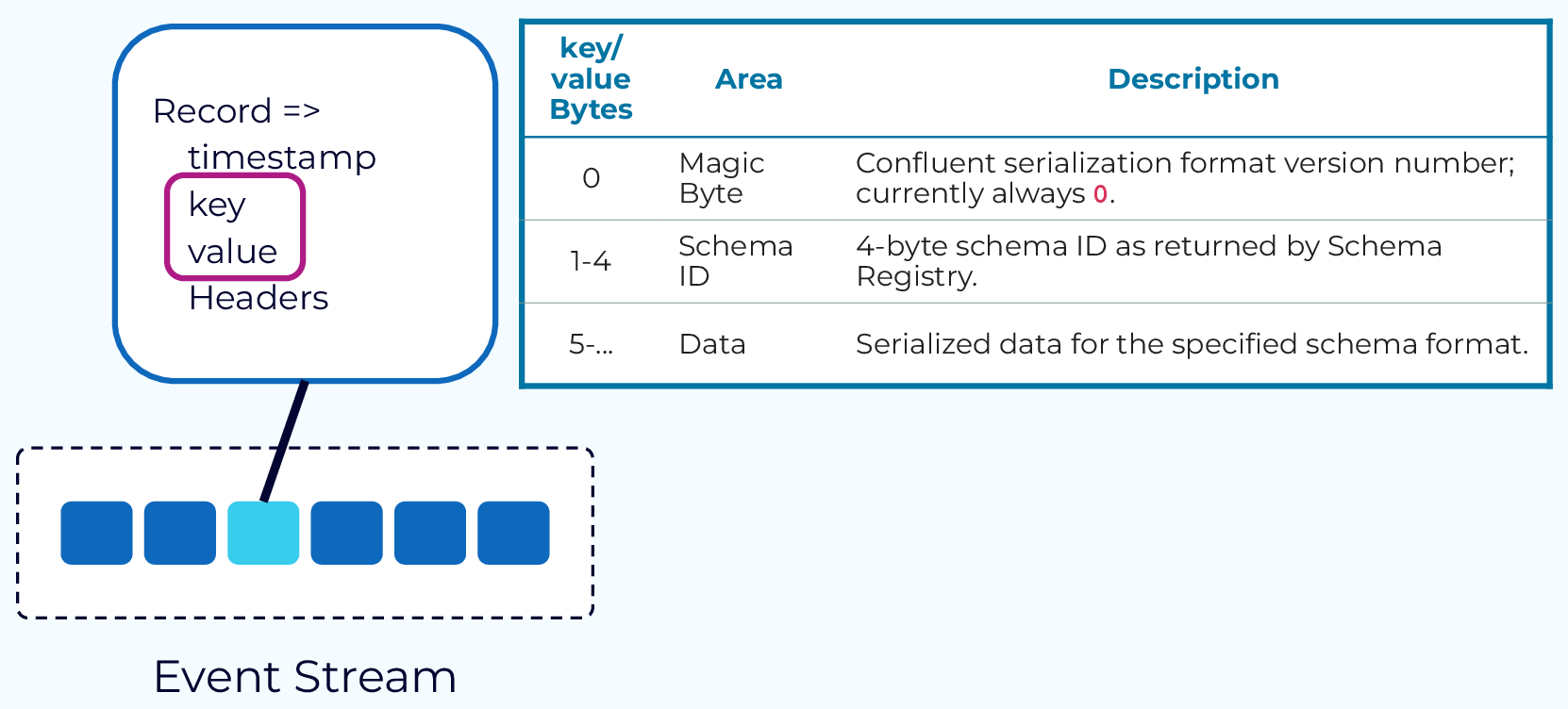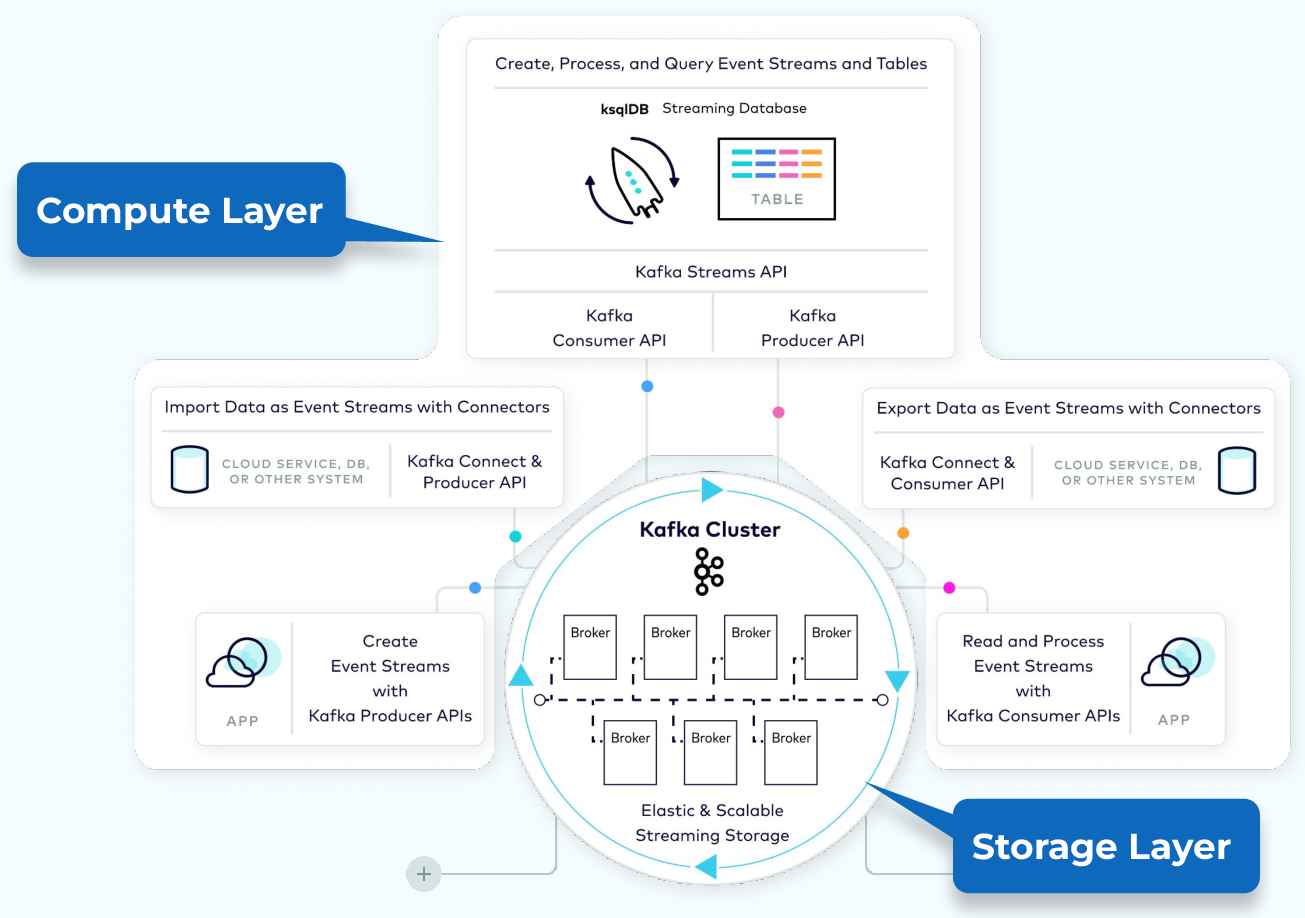
Basically, Kafka is a distributed log that LinkedIn built to handle their massive data firehose. They open-sourced it in 2011 because even they couldn't handle maintaining it alone. Kafka 4.0 dropped in March 2025 and finally killed ZooKeeper - thank fucking god, because ZooKeeper was a nightmare to debug.
The new KRaft mode (Kafka Raft) eliminates the ZooKeeper dependency that's been causing split-brain scenarios for over a decade. Plus there's a next-gen consumer rebalance protocol (KIP-848) that supposedly fixes the "stop-the-world" rebalances that have ruined our weekends.
Here's the thing about Kafka: it's incredibly fast and can handle ridiculous amounts of data, but the operational complexity will make you question your life choices. I've seen senior engineers with 10+ years of experience spend weeks trying to figure out why consumer groups are rebalancing randomly.
How This Thing Actually Works
Brokers are just servers that store your data. You need at least 3 in production (learned this the hard way when our 2-broker cluster ate shit and lost a day's worth of events). Each broker can theoretically handle thousands of partition reads/writes per second, but good luck achieving that with your network setup. Read the broker configuration guide to understand the dozens of settings you'll need to tune.
Topics are where you dump your data. Think of them as really big logs that never get deleted (until retention kicks in). The catch? You can't just throw data at a topic - you need to think about partitioning strategy or you'll hate yourself later.
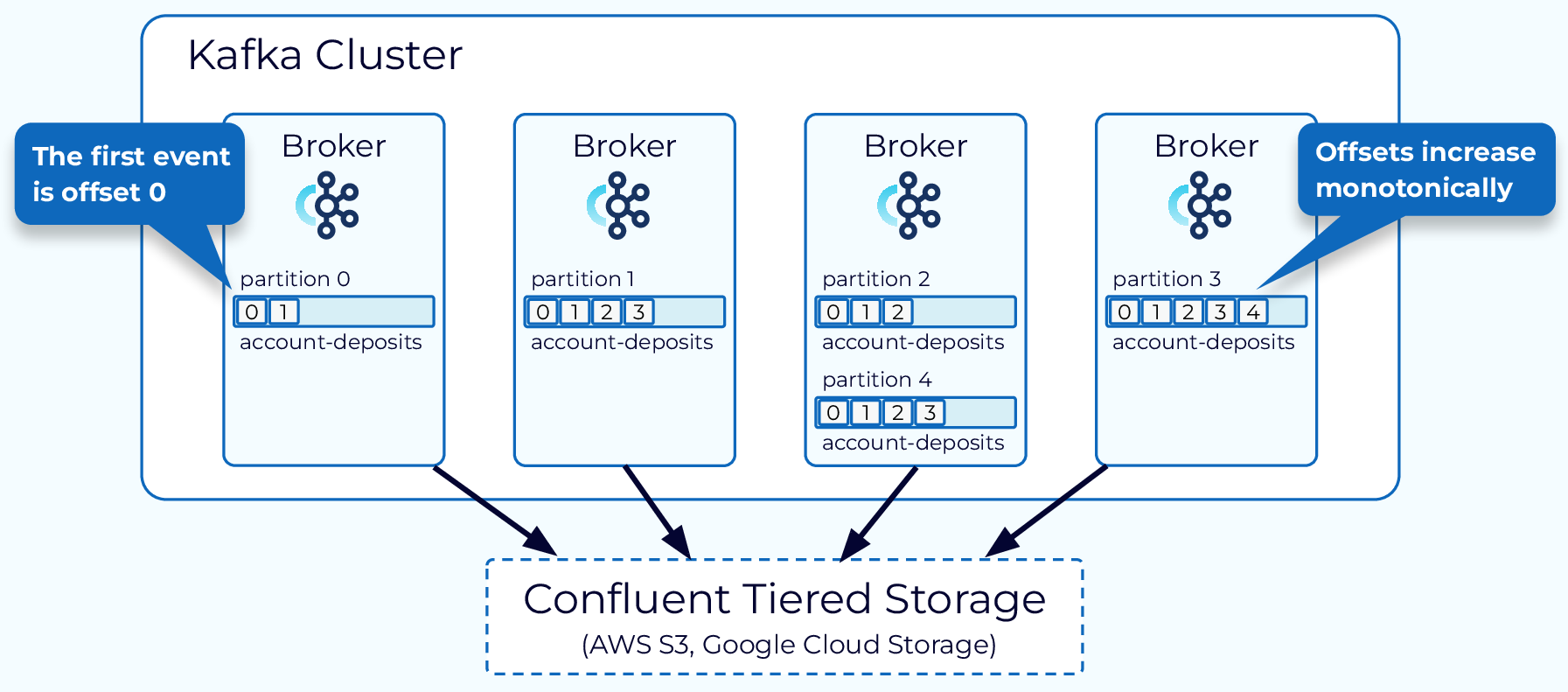
Partitions are how Kafka scales, and they're also how it'll fuck you over. More partitions = more parallelism, but also more complexity. I've seen clusters with thousands of partitions become unmanageable during rebalancing. One team I worked with had 500+ partitions per topic and spent 3 days debugging why consumers were taking 10 minutes to rebalance. Check out this partition sizing guide to avoid making the same mistakes.
Producers send data to Kafka. Sounds simple until you realize you need to configure acks, retries, idempotency, compression, batching, and a dozen other settings. Default configs are designed to fail in production - they prioritize throughput over reliability. Here's a producer tuning guide that will save you weeks of debugging.
Consumers read data from Kafka. This is where the fun begins. Consumer groups, offset management, rebalancing, lag monitoring - it's a full-time job. Our monitoring alerts go crazy every time a consumer restarts because the rebalancing triggers a cascade of false alarms.
The Reality Check
Yeah, benchmarks show Kafka hitting 605 MB/s peak throughput with 5ms p99 latency at 200 MB/s load, but those tests run on perfect lab setups with infinite money and no network issues. In the real world with shitty networks and misconfigured brokers, expect something more reasonable. Still faster than everything else, but not magic.
The "sub-millisecond latency" marketing bullshit? That performance requires perfect network conditions and unlimited budget. In practice, expect 5-50ms latency and be happy if you get it consistently.
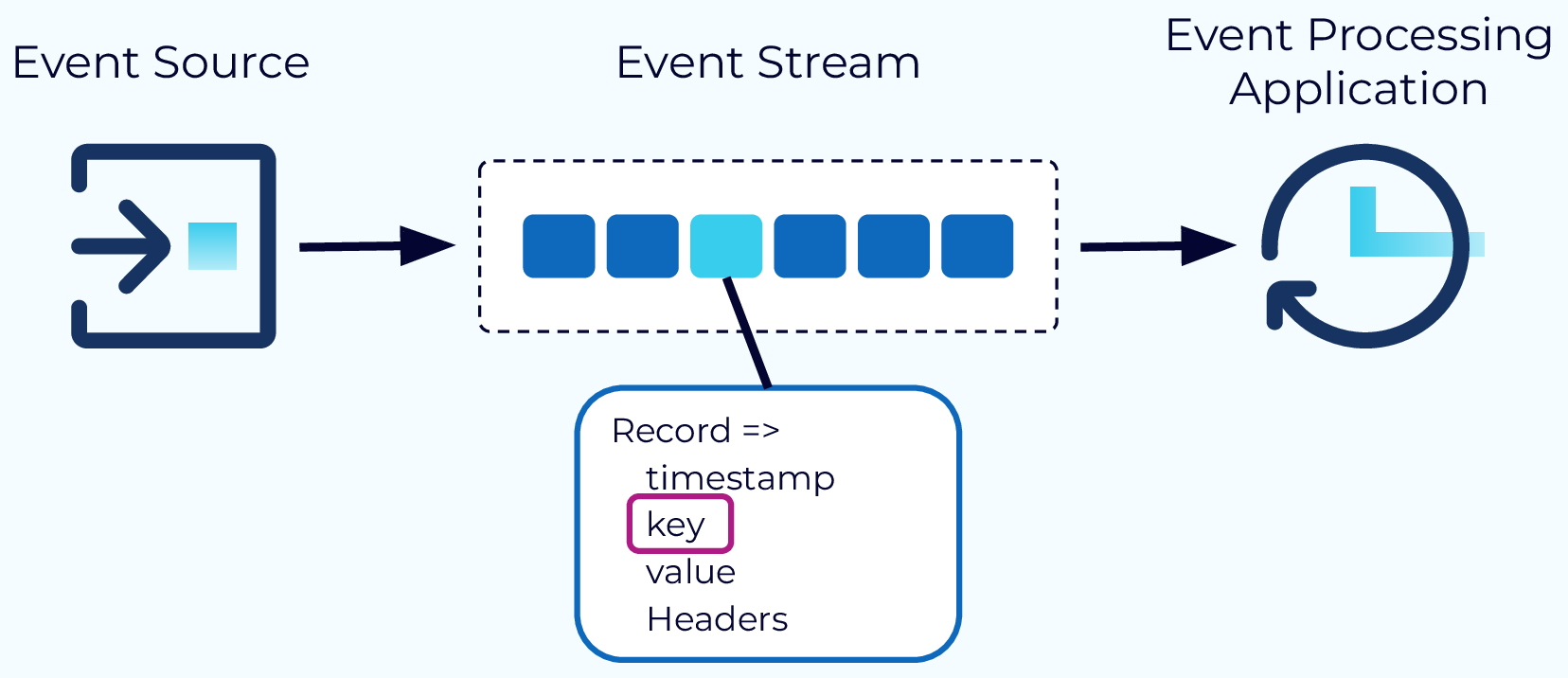
Real Talk: Unless you're processing terabytes per day, Kafka is probably overkill. I've seen too many teams adopt Kafka for a simple pub/sub use case and then spend 6 months learning how to operate it. Redis Streams or even RabbitMQ might be what you actually need. Check out this comprehensive comparison to understand the architectural differences.