Picture this: your API is randomly slow as hell, users are complaining, and you're staring at a wall of 15 microservices wondering which one is the asshole causing the problem. Welcome to distributed systems debugging without tracing - it's about as fun as debugging a memory leak with print statements.
Jaeger solves the "which service is fucking up" problem that every engineer running microservices deals with. It's a CNCF graduated project that actually works, which is saying something in the cloud-native space.
The Real Problem It Solves
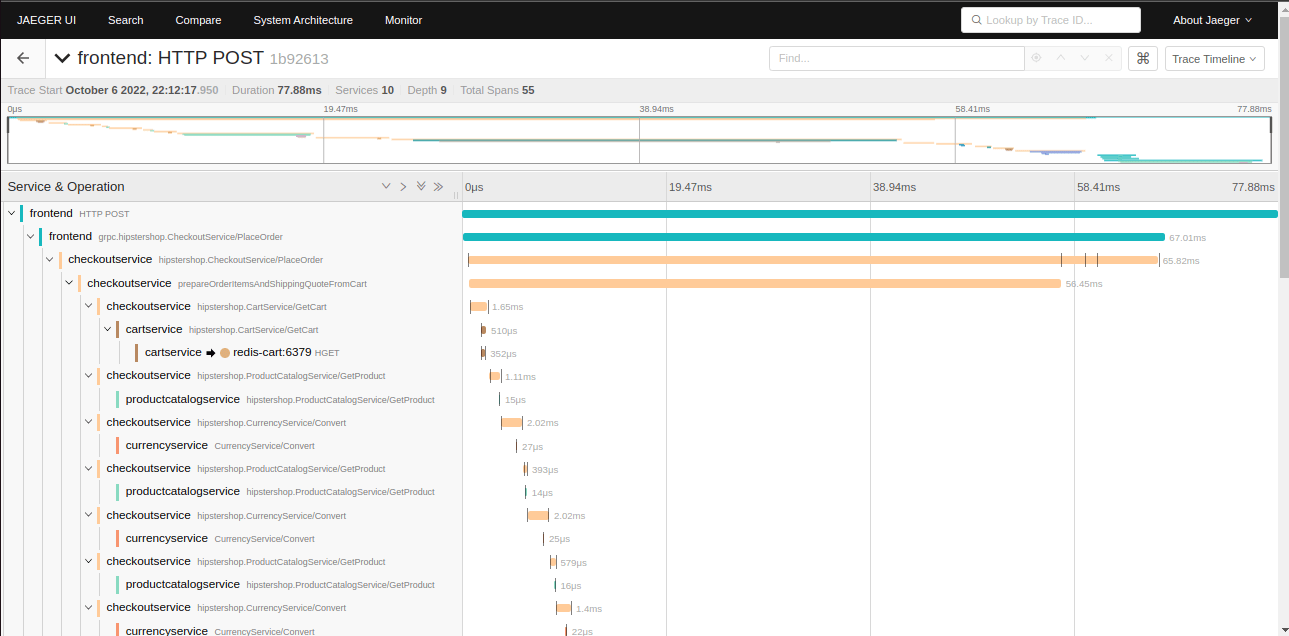
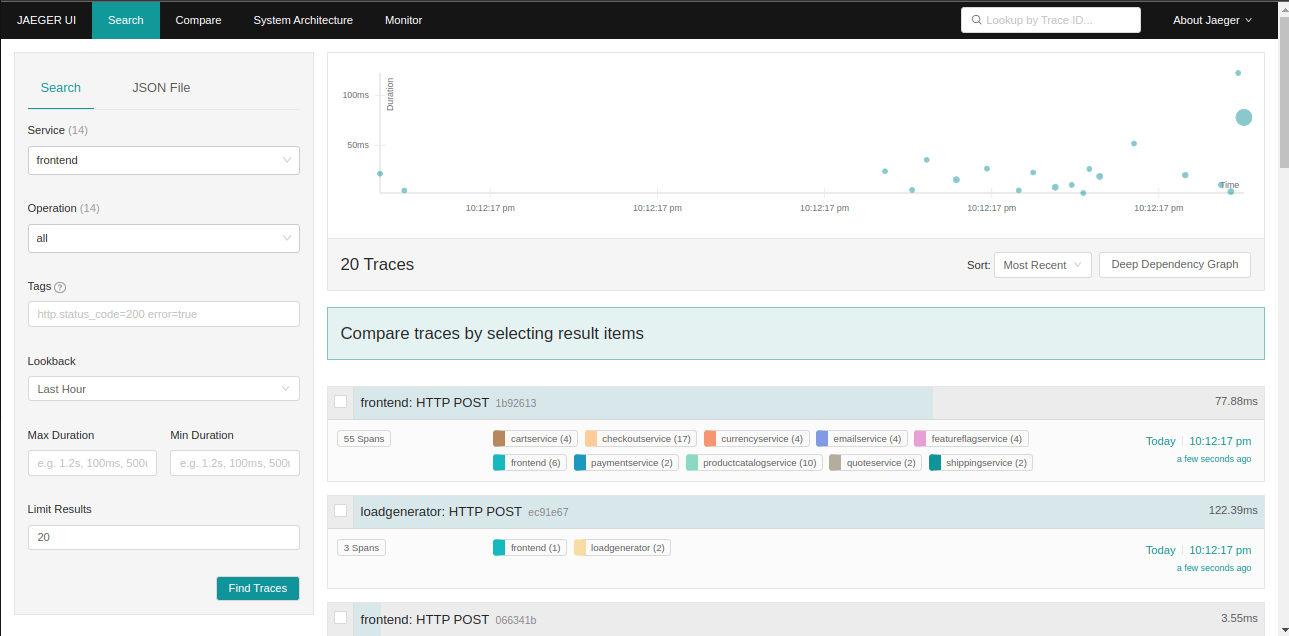
Here's what happens without tracing: A user hits your API, it takes 5 seconds to respond, and you have no clue which of your services is the bottleneck. You start ssh-ing into boxes, checking logs, running htop, and generally losing your sanity. I've spent entire weekends debugging cascading failures across microservices where the root cause was a misconfigured Redis timeout in service #12 of 18, or a database connection pool that was exhausted.
Distributed tracing shows you the complete path of a request through your system. Instead of guessing, you see exactly where the time is being spent. That 5-second API call? Turns out your user service is making 47 database queries because someone forgot to implement proper eager loading. Jaeger shows you this shit in seconds, not hours.
Jaeger v2: Finally Fixed The Annoying Stuff
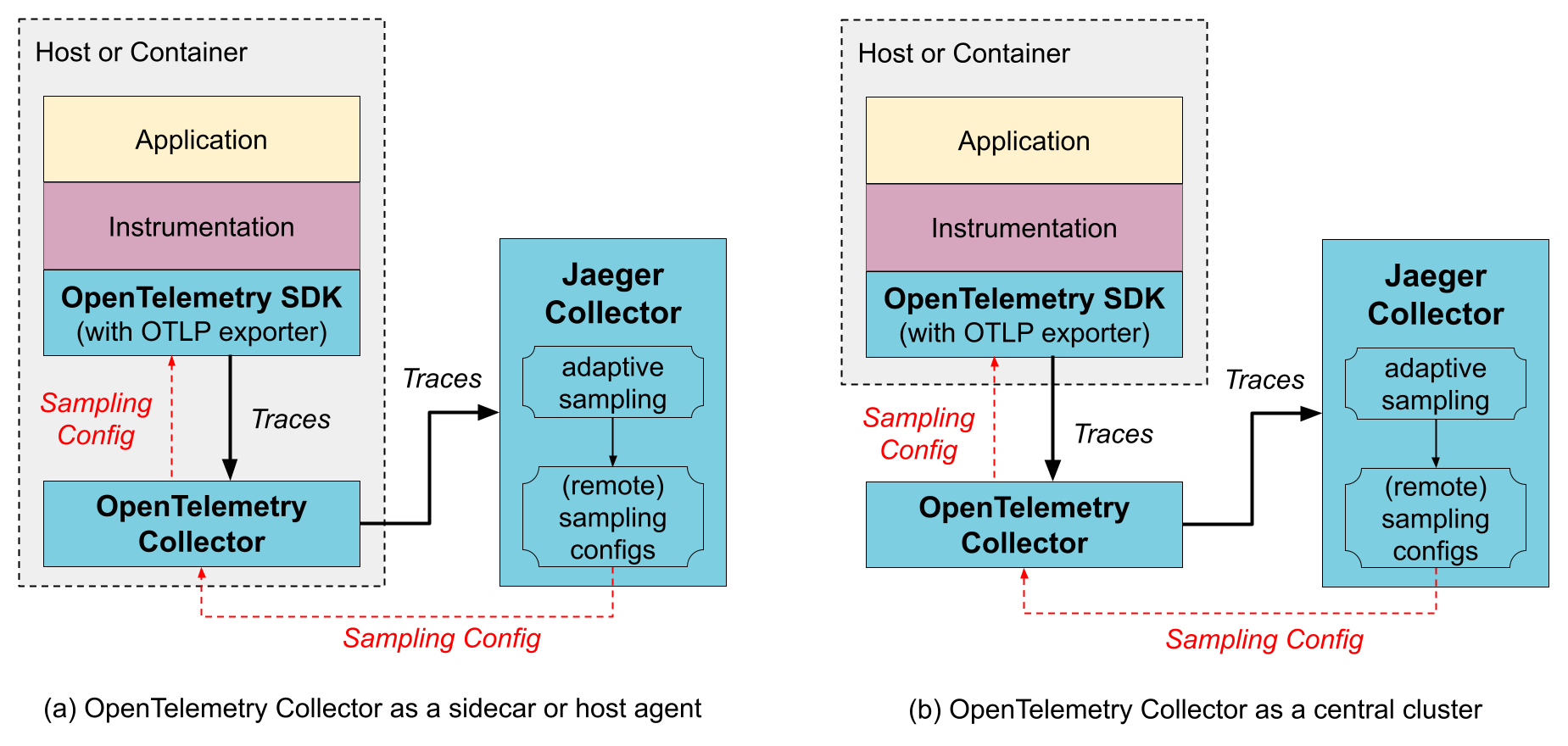
Jaeger v2 shipped in November 2024 and thank fucking god they fixed some major pain points. The old agent architecture was a nightmare to deploy - you had to run agents on every host, manage their configuration, and pray they didn't crash. V2 ditches the agent entirely and goes full OpenTelemetry native.
This matters because OpenTelemetry is the only observability standard that isn't complete garbage. Every other tracing library forces you into vendor lock-in or requires custom instrumentation that breaks when you upgrade. With Jaeger v2 + OpenTelemetry, your instrumentation works everywhere. The OpenTelemetry specification actually makes sense, unlike the proprietary APIs from Datadog or New Relic.
What It Actually Does For You
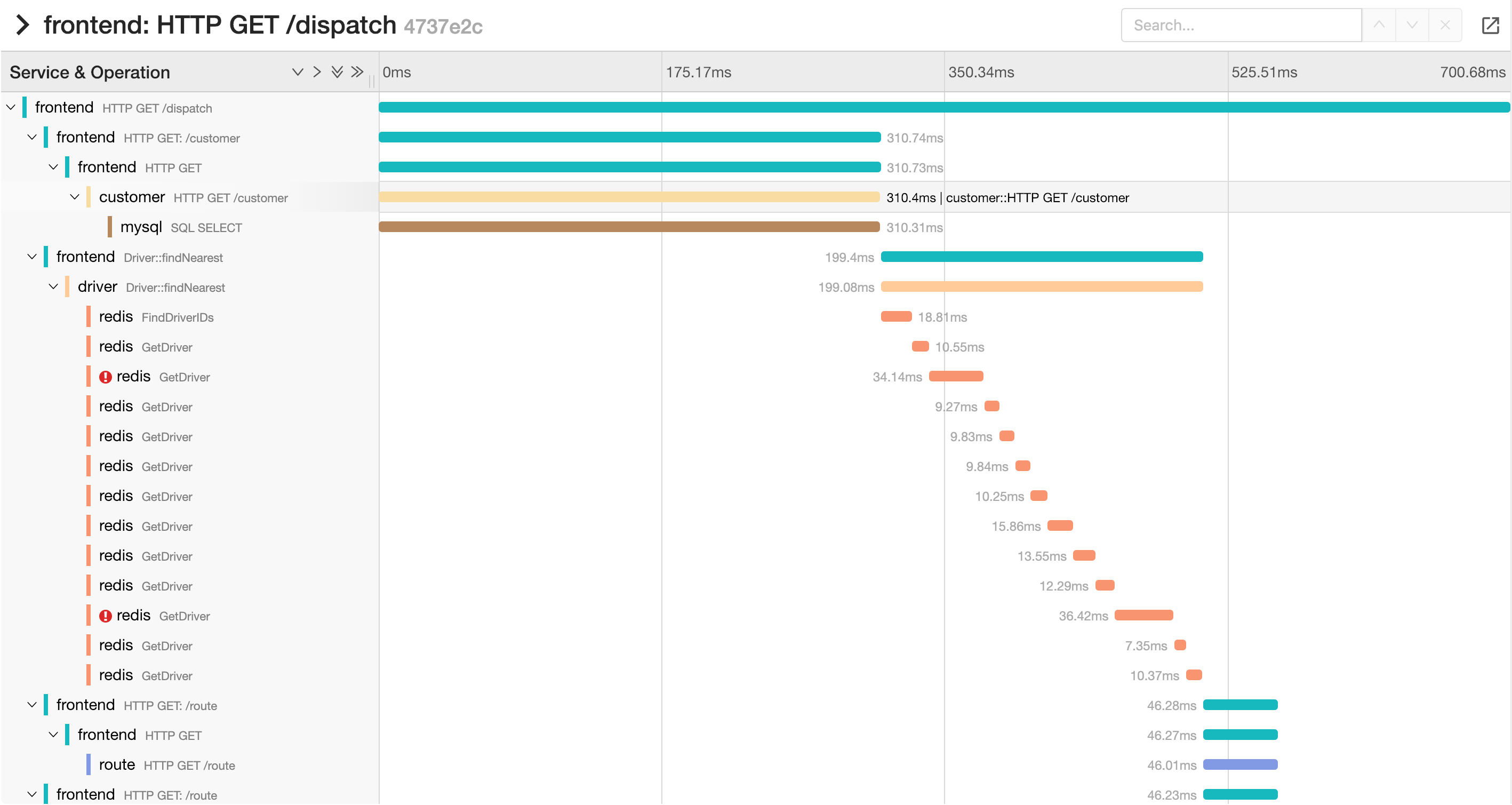
Finds The Slow Service: When your login endpoint suddenly takes 8 seconds, Jaeger shows you it's the auth service making a call to a user service that's hitting a database with a missing index. No more guessing.
Debugs Cascading Failures: That fun moment when one service going down takes out five others? Jaeger's dependency visualization shows you exactly how the failure propagated and which services you need to fix first.
Catches Resource Leaks: See patterns like steadily increasing latency that indicate memory leaks, connection pool exhaustion, or that one service that's slowly dying but hasn't crashed yet.
Performance Optimization: Find the services that are actually slow vs. the ones you think are slow. I've seen teams optimize the wrong service for months because they were guessing instead of measuring. Application performance monitoring becomes data-driven instead of gut-driven.
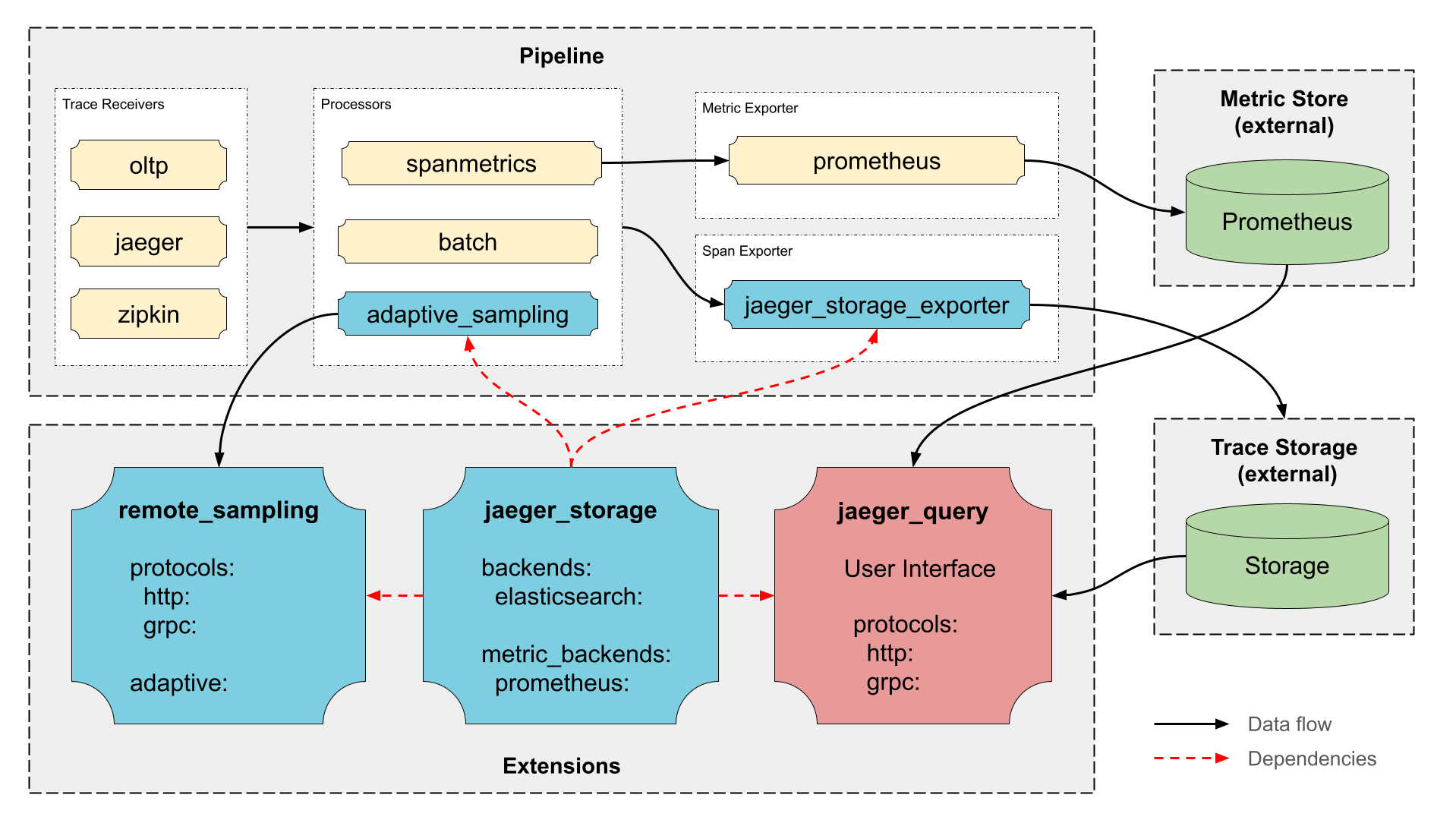
The Architecture That Actually Works
Jaeger's new v2 architecture ditches the complex multi-component approach. Instead of managing collectors, agents, query services, and storage separately, v2 gives you a single binary that handles everything. This matters because the old architecture was a deployment nightmare - five different components, each with their own configuration and failure modes.
Why Not Just Use Logs?
Logs tell you what happened in each service. Traces tell you what happened to each request. When you have 50 services and a request touches 12 of them, correlating logs manually is like trying to debug a race condition by reading print statements. Distributed tracing gives you the causality that logs can't provide.
Plus, setting up proper logging correlation across microservices is harder than setting up Jaeger. Trust me, I've done both.