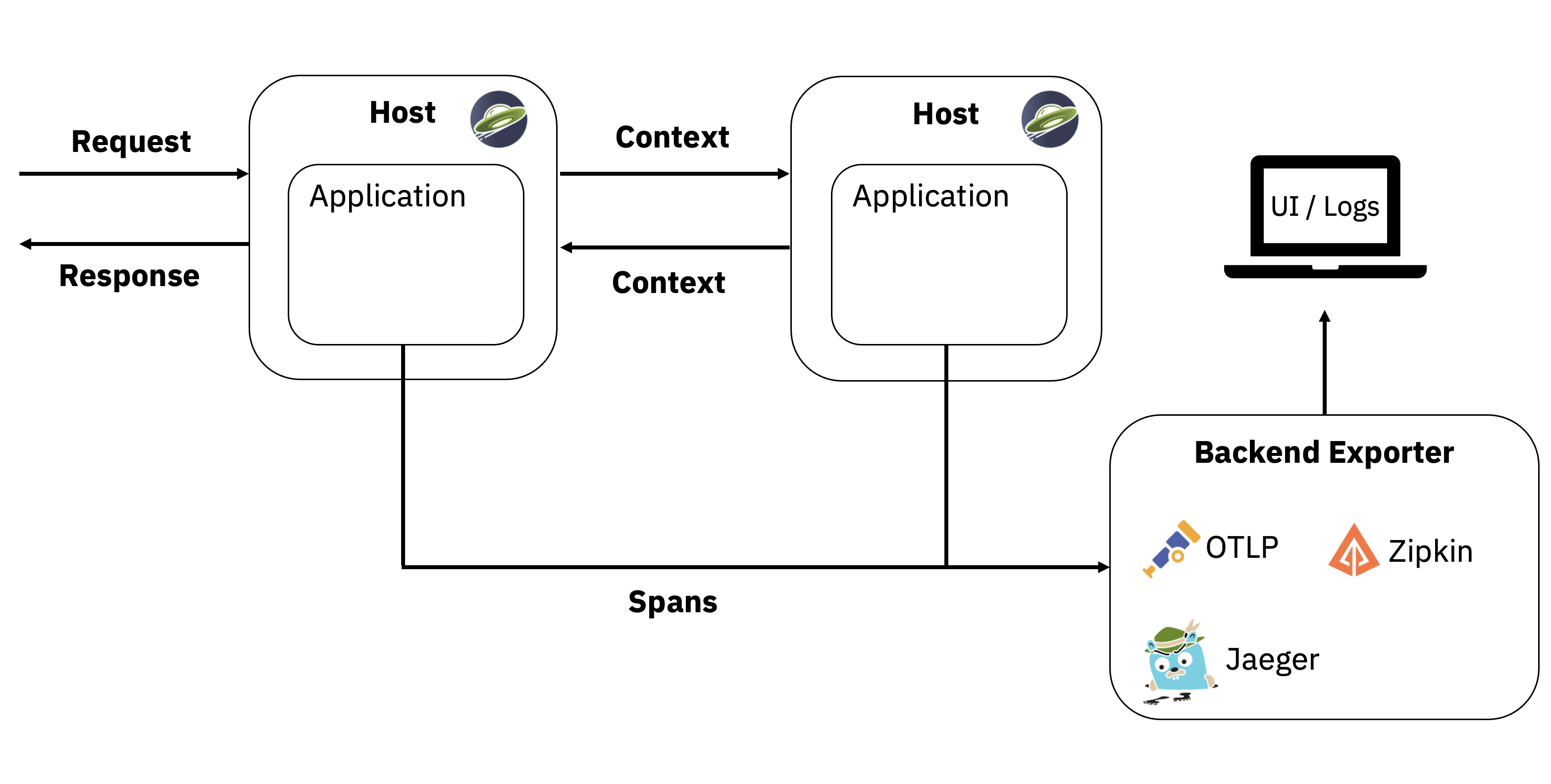
Got your monitoring stack running? Cool. Now for the part that'll make you question your career choices - getting your applications to send data that doesn't suck. Most people either instrument everything and tank their performance, or instrument nothing and wonder why their traces are empty. I went full idiot on my first attempt and instrumented every database call - ended up with 50,000 spans per request and a trace that looked like a Christmas tree.
Adding Telemetry Without Breaking Everything
The OpenTelemetry documentation is your friend here, especially the semantic conventions that define what attributes you should actually be tracking. Also worth reading: the Spring Boot starter guide and OpenTelemetry troubleshooting for Node.js for platform-specific gotchas.
Java/Spring Boot Applications
Add OpenTelemetry dependencies to your pom.xml (check the OpenTelemetry Java instrumentation repo for latest versions):
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-api</artifactId>
<version>1.30.0</version>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-sdk</artifactId>
<version>1.30.0</version>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-exporter-otlp</artifactId>
<version>1.30.0</version>
</dependency>
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-spring-boot-starter</artifactId>
<version>1.32.0</version>
</dependency>
Configure in application.yml:
management:
otlp:
metrics:
export:
enabled: true
url: http://otel-collector:4318/v1/metrics
tracing:
export:
enabled: true
url: http://otel-collector:4318/v1/traces
spring:
application:
name: user-service
otel:
exporter:
otlp:
endpoint: http://otel-collector:4318
service:
name: ${spring.application.name}
resource:
attributes:
service.version: 1.0.0
Node.js Applications
Install these packages (and pray npm doesn't break something else):
npm install @opentelemetry/api \
@opentelemetry/sdk-node \
@opentelemetry/exporter-otlp-http \
@opentelemetry/instrumentation-http \
@opentelemetry/instrumentation-express
Warning: Node.js instrumentation seems to break hot reload - at least it did for me. Spent a whole afternoon convinced my Express app was fucked before realizing the OpenTelemetry HTTP instrumentation was making nodemon have a seizure every time I saved a file. The tracing library hooks into HTTP requests and apparently that confuses the hell out of nodemon's file watching. The Node.js instrumentation docs mention this gotcha, and there's a GitHub issue about performance slowdown that affects development too.
Create tracing.js:
const { NodeSDK } = require('@opentelemetry/sdk-node');
const { OTLPTraceExporter } = require('@opentelemetry/exporter-otlp-http');
const { OTLPMetricExporter } = require('@opentelemetry/exporter-otlp-http');
const { HttpInstrumentation } = require('@opentelemetry/instrumentation-http');
const { ExpressInstrumentation } = require('@opentelemetry/instrumentation-express');
const traceExporter = new OTLPTraceExporter({
url: 'http://otel-collector:4318/v1/traces',
});
const metricExporter = new OTLPMetricExporter({
url: 'http://otel-collector:4318/v1/metrics',
});
const sdk = new NodeSDK({
traceExporter,
metricExporter,
instrumentations: [
new HttpInstrumentation(),
new ExpressInstrumentation(),
],
serviceName: 'order-service',
serviceVersion: '1.0.0',
});
sdk.start();
Import this file at the top of your main application file:
require('./tracing');
const express = require('express');
const app = express();
Python Applications
Install OpenTelemetry packages:
pip install opentelemetry-api \
opentelemetry-sdk \
opentelemetry-exporter-otlp \
opentelemetry-instrumentation-flask \
opentelemetry-instrumentation-requests
Gotcha: Python Flask auto-instrumentation works until you use async views, then it gets confused. FlaskInstrumentor doesn't handle async def route handlers well - at least in my experience. Burned 3 hours wondering why my async endpoints were invisible in traces - turns out you need manual span management for anything touching asyncio. Check the OpenTelemetry Python docs and instrumentation libraries guide for the latest async support.
Create instrumentation setup:
from opentelemetry import trace, metrics
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.exporter.otlp.proto.http.metric_exporter import OTLPMetricExporter
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.instrumentation.flask import FlaskInstrumentor
from opentelemetry.instrumentation.requests import RequestsInstrumentor
## Configure tracing
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
otlp_exporter = OTLPSpanExporter(
endpoint="http://otel-collector:4318/v1/traces"
)
span_processor = BatchSpanProcessor(otlp_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
## Configure metrics
metrics.set_meter_provider(MeterProvider())
meter = metrics.get_meter(__name__)
## Instrument Flask and requests
FlaskInstrumentor().instrument()
RequestsInstrumentor().instrument()
Custom Metrics and Traces
Adding Business Metrics
Java example with custom metrics:
@RestController
public class OrderController {
private final Counter orderCounter;
private final Timer orderProcessingTime;
public OrderController(MeterRegistry meterRegistry) {
this.orderCounter = Counter.builder("orders.created")
.description("Number of orders created")
.tag("service", "order-service")
.register(meterRegistry);
this.orderProcessingTime = Timer.builder("order.processing.time")
.description("Time taken to process orders")
.register(meterRegistry);
}
@PostMapping("/orders")
public ResponseEntity<Order> createOrder(@RequestBody Order order) {
return orderProcessingTime.recordCallable(() -> {
Order savedOrder = orderService.save(order);
orderCounter.increment();
return ResponseEntity.ok(savedOrder);
});
}
}
Adding Custom Spans
@Service
public class PaymentService {
private final Tracer tracer;
public PaymentService() {
this.tracer = GlobalOpenTelemetry.getTracer("payment-service");
}
public PaymentResult processPayment(PaymentRequest request) {
Span span = tracer.spanBuilder("payment.process")
.setAttribute("payment.amount", request.getAmount())
.setAttribute("payment.currency", request.getCurrency())
.startSpan();
try (Scope scope = span.makeCurrent()) {
// Payment processing logic
PaymentResult result = doPaymentProcessing(request);
span.setStatus(StatusCode.OK);
span.setAttribute("payment.result", result.getStatus());
return result;
} catch (Exception e) {
span.recordException(e);
span.setStatus(StatusCode.ERROR, "Payment processing failed");
throw e;
} finally {
span.end();
}
}
}
Environment Configuration
Docker Environment Variables
services:
user-service:
environment:
- OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4318
- OTEL_SERVICE_NAME=user-service
- OTEL_SERVICE_VERSION=1.0.0
- OTEL_RESOURCE_ATTRIBUTES=service.name=user-service,service.version=1.0.0
order-service:
environment:
- OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4318
- OTEL_SERVICE_NAME=order-service
- OTEL_SERVICE_VERSION=1.0.0
Kubernetes ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: otel-config
data:
OTEL_EXPORTER_OTLP_ENDPOINT: "http://otel-collector:4318"
OTEL_SERVICE_VERSION: "1.0.0"
OTEL_RESOURCE_ATTRIBUTES: "cluster=production,environment=prod"
Auto-instrumentation reality check:
- Java Spring Boot starter works but tacks on 200ms to startup. Still worth it for not manually instrumenting everything.
- Node.js auto-instrumentation grabs most HTTP calls but murders hot reload (cost me 4 hours of debugging)
- Python Flask instrumentation is fine until you need custom spans or async views, then you're on your own
- All of them vomit massive amounts of data in prod - set sampling rates or watch your AWS bill go insane (we generated crazy amounts of trace data - had to be 50TB or more the first month)
Production tips I wish someone told me earlier:
- Use environment variables for config - hard-coding collector URLs is some junior-level bullshit
- Set OTEL_SERVICE_NAME or all your traces show up as "unknown_service" and you'll want to delete everything
- Set sampling rates or go bankrupt (1% for busy apps, 100% only for dev - bills jumped to like 3K or something before I figured this out)
- Watch instrumentation overhead - this shit adds 50-100ms to every request (yes, monitoring makes your app slower)
Key references: OpenTelemetry Java SDK for implementation, sampling strategies to avoid bankruptcy, Baeldung's Spring Boot setup guide, the Aspecto troubleshooting checklist, and SigNoz instrumentation guide for production examples.



