OpenTelemetry exists because observability vendors charge enterprise prices for basic functionality. It's a framework that collects traces, metrics, and logs without forcing you to take out a second mortgage to pay Datadog.
You've got microservices spread across God knows how many containers, and when everything crashes at 2am, you need to know which service started the cascade failure. OpenTelemetry gives you three ways to figure this out:
Distributed Tracing (AKA "Follow the Breadcrumbs")
Traces show you exactly where your request went to die. Each span is like a GPS coordinate for your failing API call. Works great until you realize you set sampling to 0.001% and the one error you needed to debug wasn't captured.
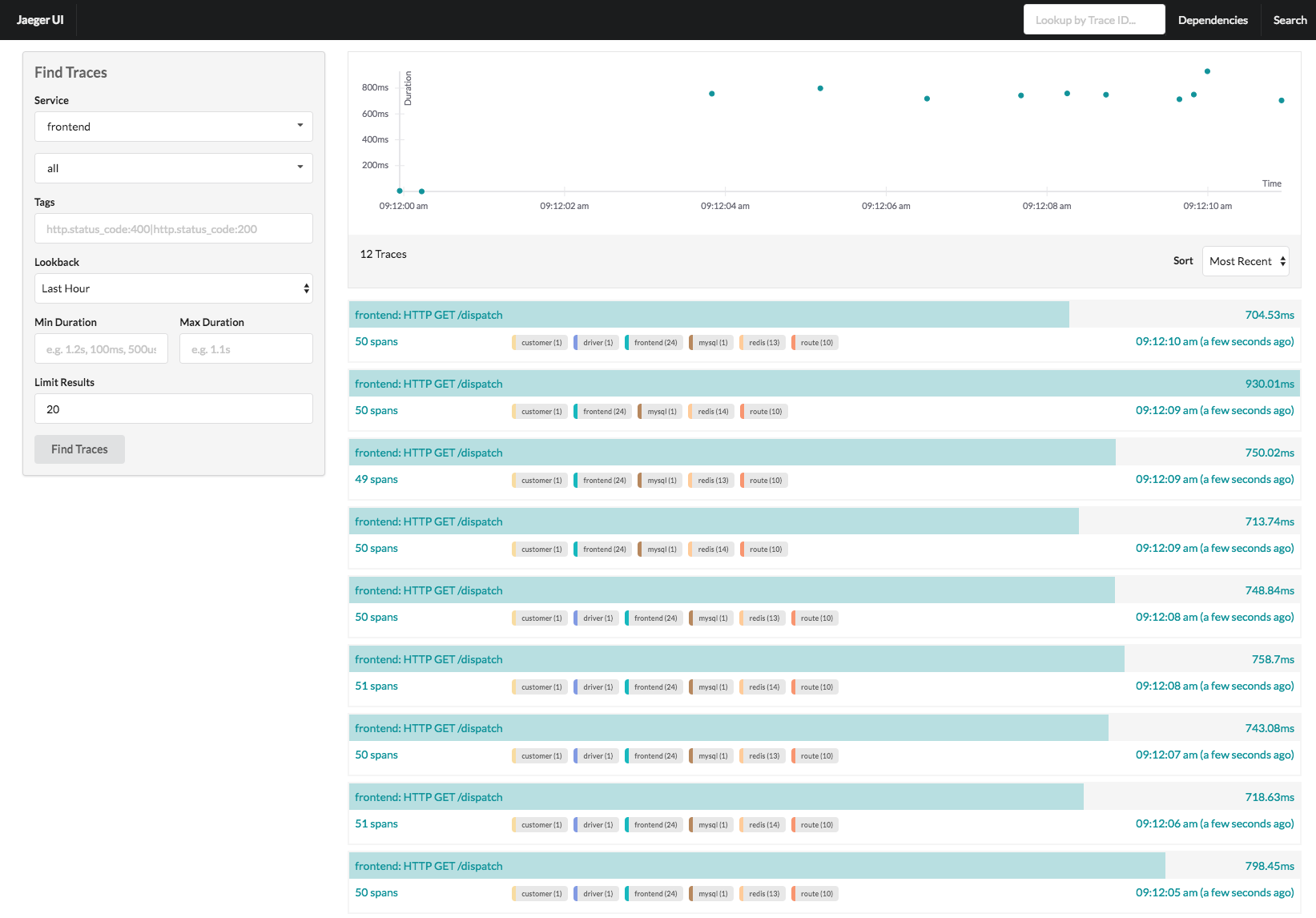
Real talk: Traces are beautiful when they work, but prepare to spend hours debugging why spans randomly disappear into the void. Network timeouts, collector crashes, and misconfigured exporters will make traces vanish faster than your weekend plans.
Metrics (Numbers That Actually Matter)
Metrics tell you your API is slow as molasses before your customers start complaining. Counters, gauges, histograms - the holy trinity of "oh shit, something's wrong."

Pro tip: Start with basic RED metrics (Rate, Errors, Duration) or your Prometheus storage will explode from high cardinality metrics. Yes, user IDs as labels will kill your database.
Dashboard hell is real - you'll spend more time arguing about dashboard colors and layout than fixing the actual performance issues that are killing your app.
Logs (The Backup Plan)
Logs are still logs, but now they're correlated with traces. Sounds fancy until you realize most log correlation requires manual work and proper trace context propagation.
Vendor Neutrality (The $100k Lesson)
This is the real reason OpenTelemetry exists. When observability vendors jack up prices (and they always do), companies that used OpenTelemetry can switch to Grafana Cloud or self-host Jaeger + Prometheus. Companies locked into proprietary agents? They pay the ransom.
The beauty of this approach? OpenTelemetry works across 20+ languages with the same APIs. Your Python Flask app and Go microservice send traces the same way, which is less painful than learning different instrumentation for every service. One standard, infinite backends - that's the promise.




 The other 10%:
The other 10%: