![]()
The Distributed System From Hell I Actually Lived Through
Last company I worked at decided to "modernize" our Rails monolith by splitting it into 17 Node.js services. What could possibly go wrong?
Everything. Fucking everything.
Service A called Service B called Service C to render a single user profile. One timeout anywhere meant the whole page failed. Deployment required coordinating 17 different repos. When something broke in production (and it always broke), finding the root cause meant tailing logs from 17 different containers.
The kicker? Our "distributed" system was more coupled than the monolith we replaced. Every feature still required changes across 8+ services. We had all the complexity of microservices with none of the benefits.
When to Actually Consider Microservices (Spoiler: Probably Never)
After that clusterfuck, I learned when microservices actually make sense:
- Your monolith deploy takes over an hour and breaks production weekly
- You have 15+ developers stepping on each other's commits daily
- Different parts of your system have completely different scaling needs
- Your main database is the bottleneck and you've exhausted vertical scaling
Netflix evolved to microservices because their monolith couldn't handle streaming video to millions of users simultaneously. Amazon did it because coordinating teams became impossible at their scale.
Node.js: The Good, Bad, and Why It Actually Works for Services
The Event Loop Advantage (When It Doesn't Bite You)
Node.js handles I/O-heavy workloads better than most languages. While Java spawns 200 threads that fight over database connections, Node.js handles thousands of concurrent requests on a single thread.
This works great until someone blocks the event loop with a synchronous operation and your entire service locks up. Learned this the hard way when a junior dev added fs.readFileSync() in production and brought down our user service for 20 minutes.
Actual Production Numbers (From My Last Job That Almost Fired Me):
- Express.js service: around 8k concurrent connections, RAM was about 45MB depending on load
- Connection pooling: 10 database connections handled roughly 500 req/sec when things were working
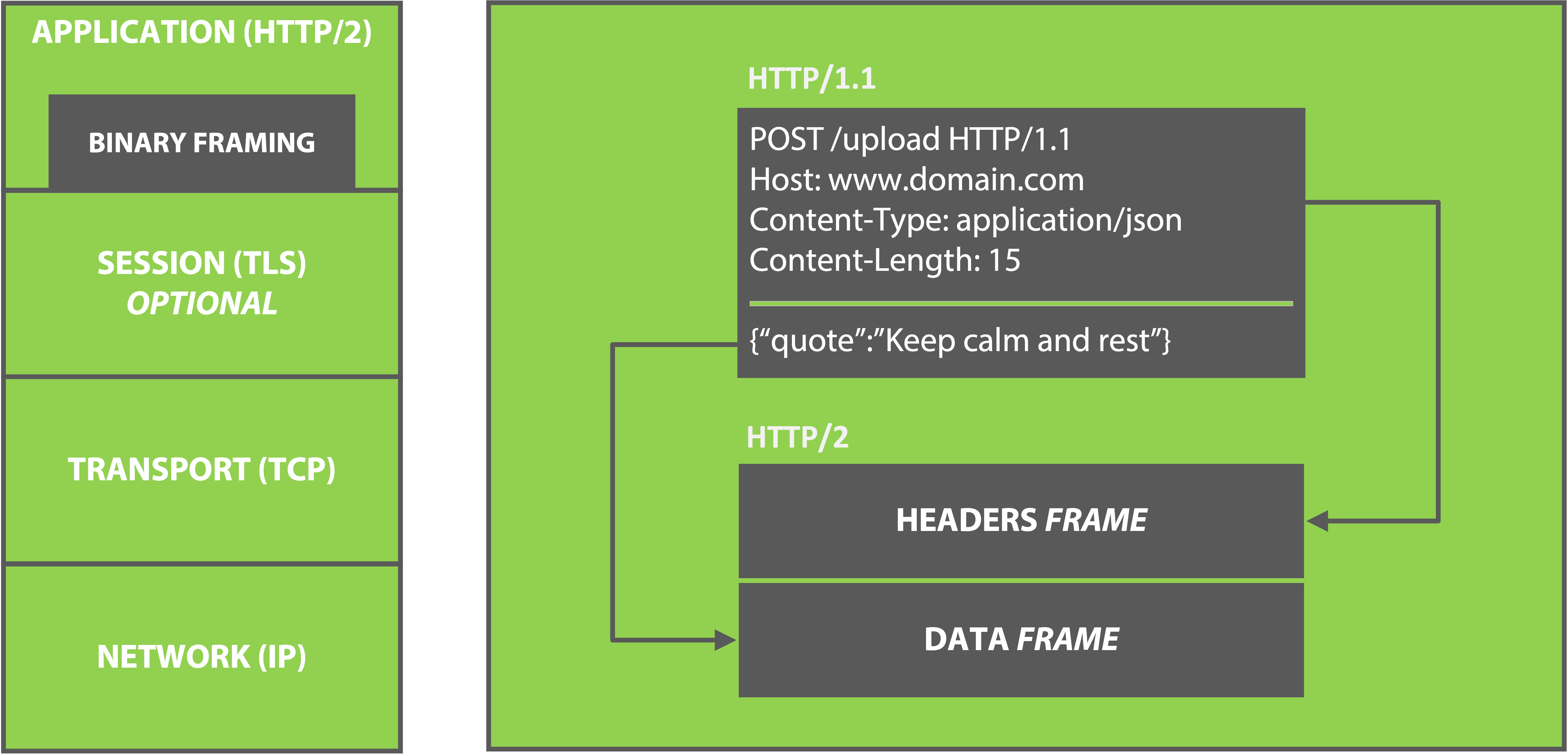
- HTTP/2 between services: maybe 30-40% latency improvement over HTTP/1.1, hard to measure consistently
JavaScript Everywhere (Until You Need Performance)
Using JavaScript across your entire stack means:
- Developers can work on any service without learning new languages
- Shared type definitions between frontend and backend (when TypeScript doesn't shit the bed)
- Same tooling everywhere: ESLint, Prettier, Jest
- Common async patterns (until you forget to await something and spend 2 hours debugging)
Downside: Try doing CPU-intensive work in Node.js and watch your event loop die. We ended up writing our image processing service in Go because Node.js couldn't handle resizing 1000 images without blocking every other request.
npm: A Blessing and a Curse (Mostly Curse)
npm has packages for everything microservices-related. The problem? Half of them are abandoned by maintainers who got real jobs, a quarter have security vulnerabilities that make your CISO cry, and the rest conflict with each other in ways that violate the laws of physics.
We spent 3 days debugging why our services randomly crashed until we found that bull (job queue) and opossum (circuit breaker) both tried to monkey-patch the same Promise implementation. Fun times.
Libraries that actually work in production:
- kafkajs: Rock solid Kafka client that doesn't randomly break
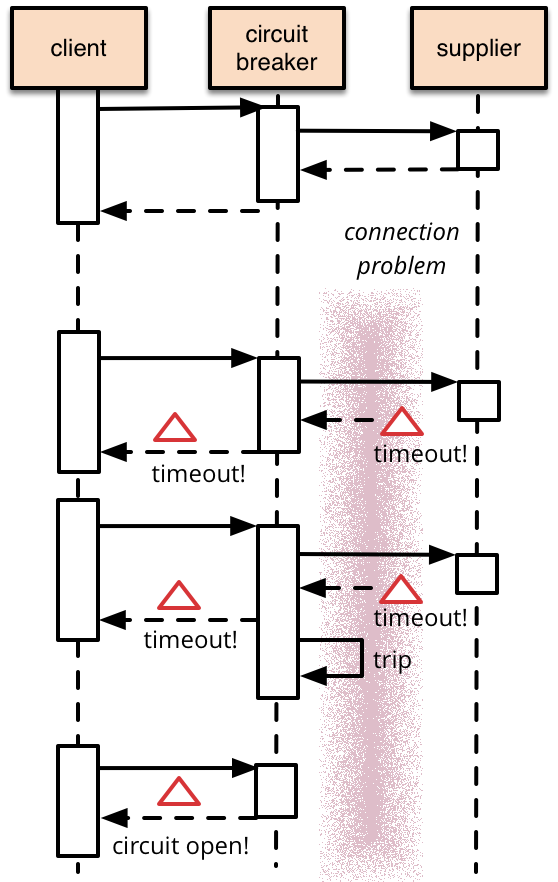
- opossum: Circuit breaker that saved our ass when the payment service started timing out
- prom-client: Prometheus metrics for Node.js monitoring
- fastify: High-performance framework that beats Express for microservices
- helmet.js: Security middleware that you should just add and forget about
- joi: Input validation that prevents the injection attacks you forgot to check for
- winston: Structured logging for when you need to debug distributed failures
- node-config: Environment-based configuration that doesn't leak secrets
- amqplib: RabbitMQ client for message queuing

Node.js Version Reality Check: What Actually Works in 2025
The Current State (September 2025):
- Node.js 18 LTS - supported until April 2026, still getting security patches
- Node.js 20 LTS - current LTS version, rock solid for production
- Node.js 22 LTS - became LTS in October 2024, latest stable if you like living dangerously
Node.js 22 actually has some useful stuff:
- Built-in fetch(): Finally, no more
node-fetchdependency hell - V8 improvements: Startup time is faster, memory usage slightly better
- Stable test runner: Built-in testing so you don't need Jest for simple stuff
Version gotcha that bit me in the ass: Node 18.2.0 through 18.7.0 had memory leaks that would slowly kill services after 6-8 hours of runtime. I spent 3 days debugging "ghost crashes" until I found the GitHub issue. Always update to 18.17.0+ or you'll want to switch careers.
Worker Threads: The Theory vs Reality
Worker threads are great in theory. In practice, they're a pain in the ass.
// This looks clean but hides the complexity
if (isMainThread) {
app.post('/analyze', async (req, res) => {
const worker = new Worker(__filename, {
workerData: req.body.data
});
// What happens when this worker crashes?
// How do you handle timeouts?
// What about memory leaks in worker threads?
worker.on('message', (result) => {
res.json(result);
});
});
} else {
// Worker dies silently if this throws
const analysis = performComplexAnalysis(workerData);
parentPort.postMessage(analysis);
}
Reality check: We tried this pattern for image processing. Workers would randomly die with exit code 0 (thanks Node), leak memory until the container OOMKilled, or get stuck in infinite loops. Ended up just using a separate Go service. Sometimes admitting defeat is the smart choice.
Service Communication Patterns That Actually Work
HTTP/REST: Boring But Reliable
Everyone wants to use gRPC because it's "faster." You know what's faster? Not spending 3 days debugging why your ALB returns 502s with gRPC but works fine with curl. Turns out nginx doesn't handle HTTP/2 upstream connections the way gRPC expects. Who knew?
HTTP/REST works because:
- You can debug it with curl or Postman instead of specialized gRPC tools
- Every proxy, load balancer, and CDN since 2005 understands it
- HTTP status codes actually mean something to everyone
- Your frontend team doesn't hate you (OpenAPI specs help too)
- HTTP caching works out of the box without extra configuration
- CORS is a known problem with known solutions
- Rate limiting patterns are well-established
- Authentication can use standard JWT tokens
- API versioning has established patterns everyone understands
- Swagger UI provides automatic documentation
// This actually works in production
const fastify = require('fastify')({ logger: true });
fastify.post('/users', async (request, reply) => {
try {
// Validate input (because users lie)
if (!request.body.email || !request.body.email.includes('@')) {
return reply.code(400).send({ error: 'Invalid email' });
}
const user = await UserService.create(request.body);
reply.code(201).send(user);
} catch (error) {
// Log the actual error for debugging
console.error('User creation failed:', error);
reply.code(500).send({ error: 'Internal server error' });
}
});
Event-Driven Architecture with Message Queues
For async stuff, message queues let services not give a shit about each other:
- Apache Kafka: Best for high-throughput event streaming and complex event processing
- RabbitMQ: Excellent for work queues and RPC patterns
- AWS SQS/SNS: Managed queuing with built-in DLQ and scaling
- Redis Streams: Lightweight event streaming for simple use cases
// Event-driven order processing
const kafka = require('kafkajs').kafka({
clientId: 'order-service',
brokers: ['kafka:9092']
});
const producer = kafka.producer();
// Order service publishes events
async function createOrder(orderData) {
const order = await Order.create(orderData);
// Notify other services asynchronously
await producer.send({
topic: 'order-events',
messages: [{
key: order.id,
value: JSON.stringify({
type: 'ORDER_CREATED',
orderId: order.id,
customerId: order.customerId,
items: order.items
})
}]
});
return order;
}
// Inventory service consumes events
const consumer = kafka.consumer({ groupId: 'inventory-service' });
await consumer.subscribe({ topic: 'order-events' });
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
const event = JSON.parse(message.value.toString());
if (event.type === 'ORDER_CREATED') {
await updateInventory(event.items);
}
}
});
Data Management: The Make-or-Break Decision
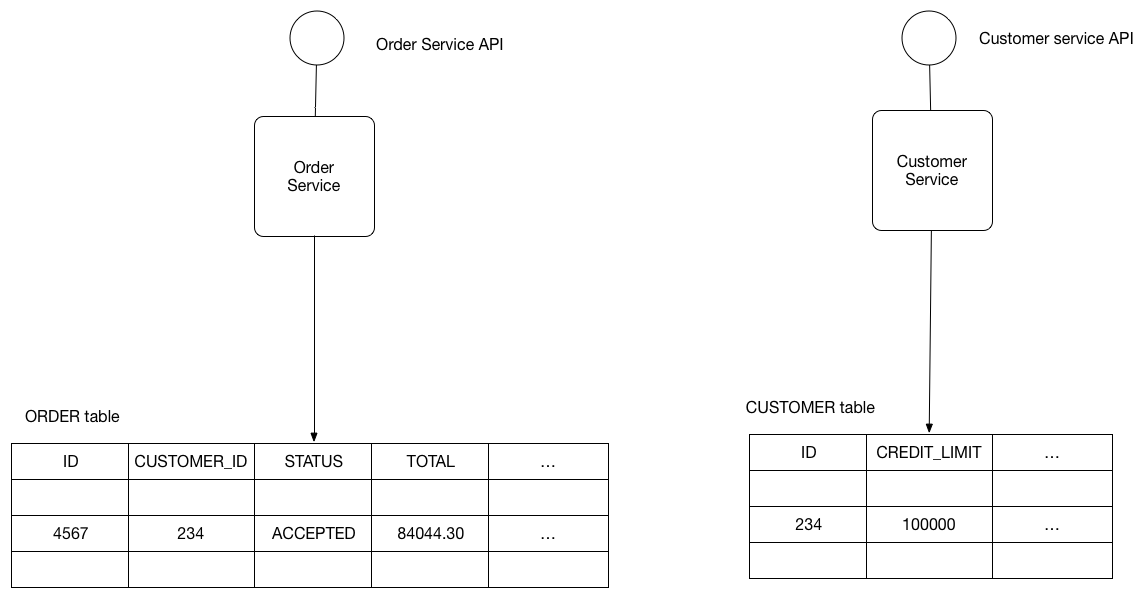
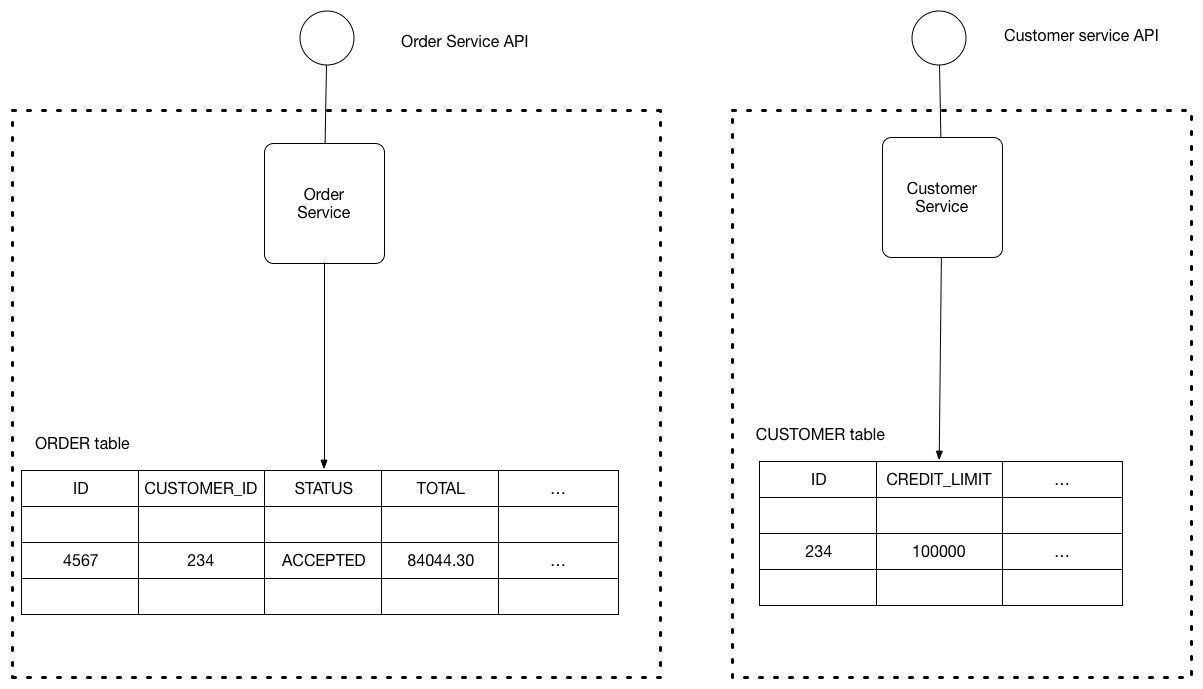
Database-Per-Service Pattern (Good Luck With Joins)
Each microservice owns its data and database. This sounds great until you need to join data across 3 different systems:
- Polyglot persistence: Use PostgreSQL for transactional data, MongoDB for document storage, Redis for caching
- Data consistency: Implement Saga patterns for distributed transactions (good luck)
- Data synchronization: Use event-driven replication and pray nothing gets out of sync
Avoiding the Distributed Monolith Trap
The biggest way to fuck up microservices is creating a distributed monolith—services that are technically separate but still coupled tighter than a junior dev's error handling:
// BAD: Distributed monolith pattern
class OrderService {
async createOrder(orderData) {
// Synchronous calls to multiple services
const customer = await CustomerService.getCustomer(orderData.customerId);
const inventory = await InventoryService.checkAvailability(orderData.items);
const pricing = await PricingService.calculatePrice(orderData.items);
// If any service is down, order creation fails
return Order.create({ ...orderData, customer, inventory, pricing });
}
}
// GOOD: Event-driven decoupling
class OrderService {
async createOrder(orderData) {
// Create order with minimal required data
const order = await Order.create({
customerId: orderData.customerId,
items: orderData.items,
status: 'PENDING'
});
// Notify other services asynchronously
await EventBus.publish('ORDER_CREATED', {
orderId: order.id,
customerId: order.customerId,
items: order.items
});
return order;
}
}
Development and Deployment Workflow
Service Development Best Practices
- API-first development: Define OpenAPI contracts before implementation
- Contract testing: Use Pact.js to ensure service compatibility
- Local development: Docker Compose for realistic testing environment
- Testing strategy: Unit tests for business logic, integration tests for service boundaries
Deployment and Operations
- Containerization: Docker with multi-stage builds for smaller images
- Orchestration: Kubernetes for production, Docker Swarm for simpler setups
- Service mesh: Istio or Linkerd for traffic management (if you hate yourself)
- Monitoring: Prometheus + Grafana + Jaeger for when shit breaks
![]()
Here's the thing: microservices work when they solve real problems you actually have, not because some $500/hour consultant told you Conway's Law applies to your 3-person startup. Node.js is decent for building them, but most teams would be better off with a boring monolith that deploys in 30 seconds instead of 15 services that take 2 hours to coordinate and pray they don't break.
Start simple. Add complexity only when the pain of not having it exceeds the pain of maintaining it. And remember - if you can't debug your system at 3am while hungover and getting paged, it's too fucking complicated.