Microservices turned debugging into archaeology. One request touches 15 services, fails in the 12th one, and good luck figuring out why. Traditional monitoring tools shit the bed with this complexity.

I've spent years building observability stacks that work in production. Here's what I learned: you need OpenTelemetry for instrumentation (because vendor SDKs are trash), Jaeger for tracing (because following requests across services manually is hell), and Grafana for visualization (because readable dashboards matter).
What This Stack Actually Does
OpenTelemetry collects traces, metrics, and logs from your apps without tying you to any vendor. It's the CNCF's way of saying "fuck proprietary instrumentation." Version 1.0 dropped in 2021 and it's been solid since.
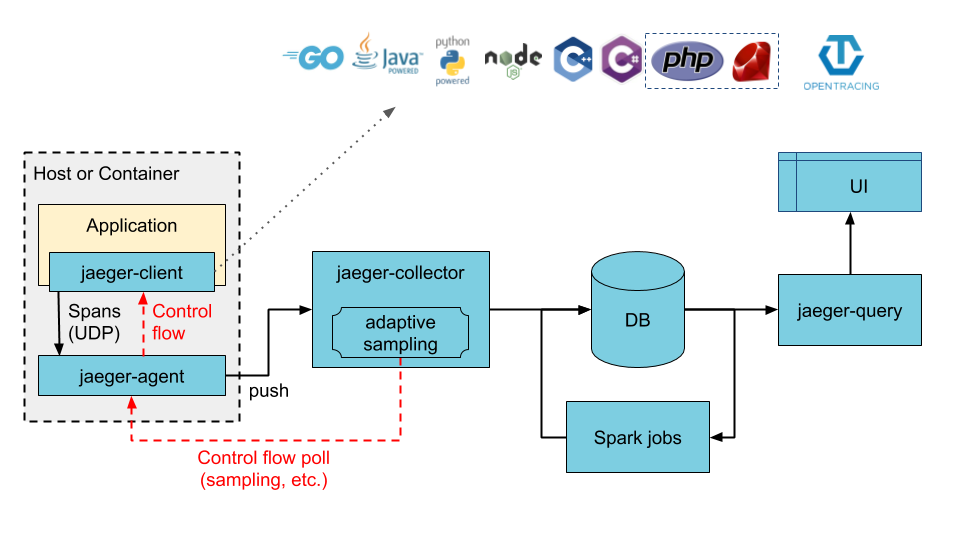
Jaeger stores and searches your traces. V2 just came out (November 2024) and it's built on OpenTelemetry Collector, which means native OTLP support and way less configuration hell. V2 supports ClickHouse, Elasticsearch, and Cassandra as storage backends, with gRPC and HTTP ingestion endpoints that actually work under load.
Grafana turns your data into dashboards people can actually read. Grafana's had trace-to-metrics since 9.1, but 11.0 improved the TraceQL integration, which is crucial when you're debugging cascading failures.
Kubernetes runs it all and provides service discovery that actually works (most of the time).
Why This Integration Doesn't Suck
Unlike most monitoring stacks that make you choose between vendor lock-in or configuration hell, this combination actually works:
OpenTelemetry standardizes everything - traces, metrics, logs all use the same format. No more vendor-specific data formats or proprietary SDKs that break every update.
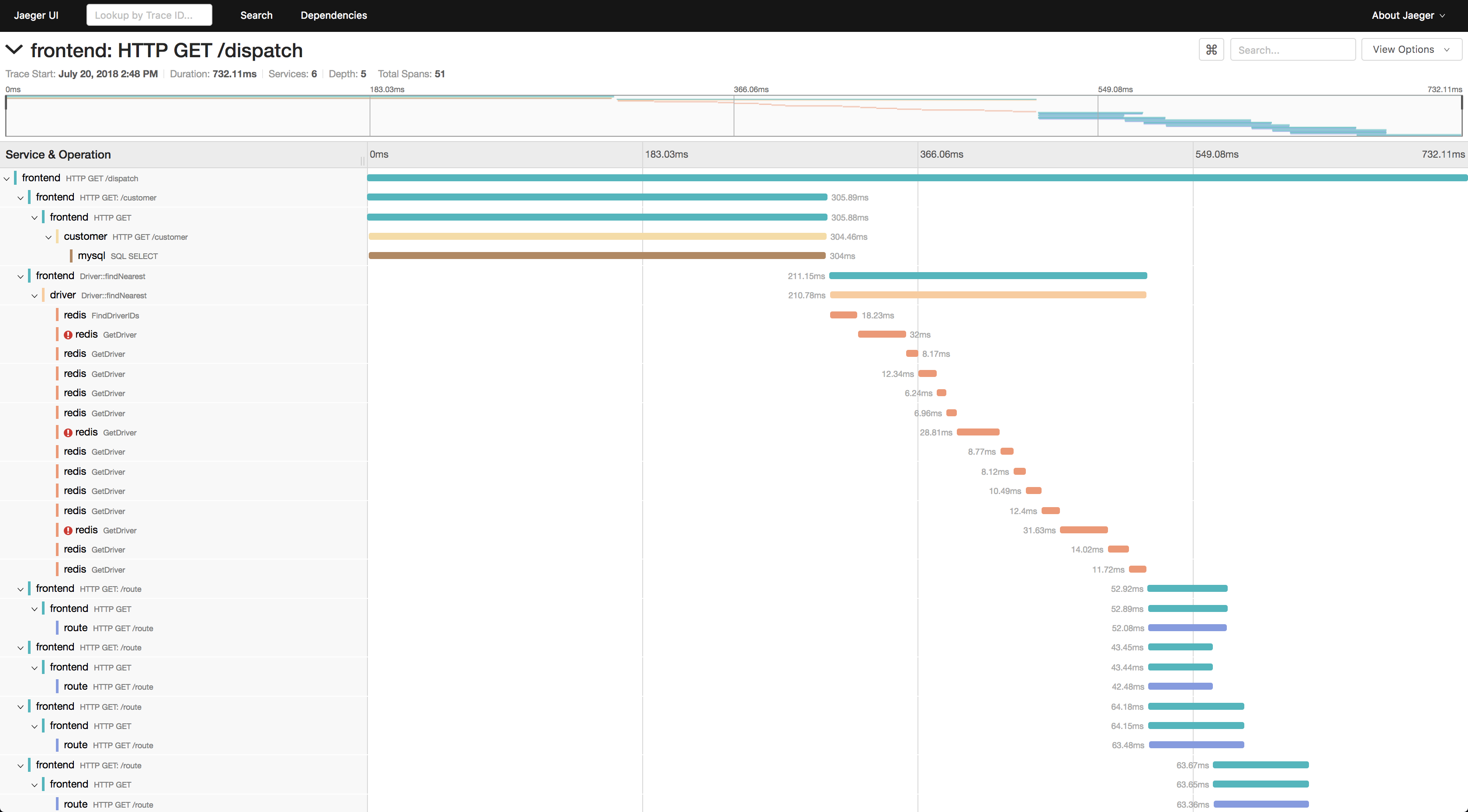
Request tracing that actually works - W3C trace context flows through your entire stack. A request failing in service 12 gets tracked back to the originating API call, with timing for every hop.
Zero-code Kubernetes integration - The OpenTelemetry Operator injects sidecar collectors automatically. Your pods get instrumented without touching application code.
Netflix-scale for free - They process 2+ trillion spans daily using this architecture. That's enterprise scale without the enterprise price tag that makes your CFO cry.


The best part? It's all open source. No surprise licensing fees, no vendor account managers calling you every week, no \"contact sales for pricing\" bullshit.