Grafana went from "just dashboards" to trying to be your entire observability stack with LGTM (Loki, Grafana, Tempo, Mimir). It mostly works, but good luck explaining why you need four different systems to see if your website is up.
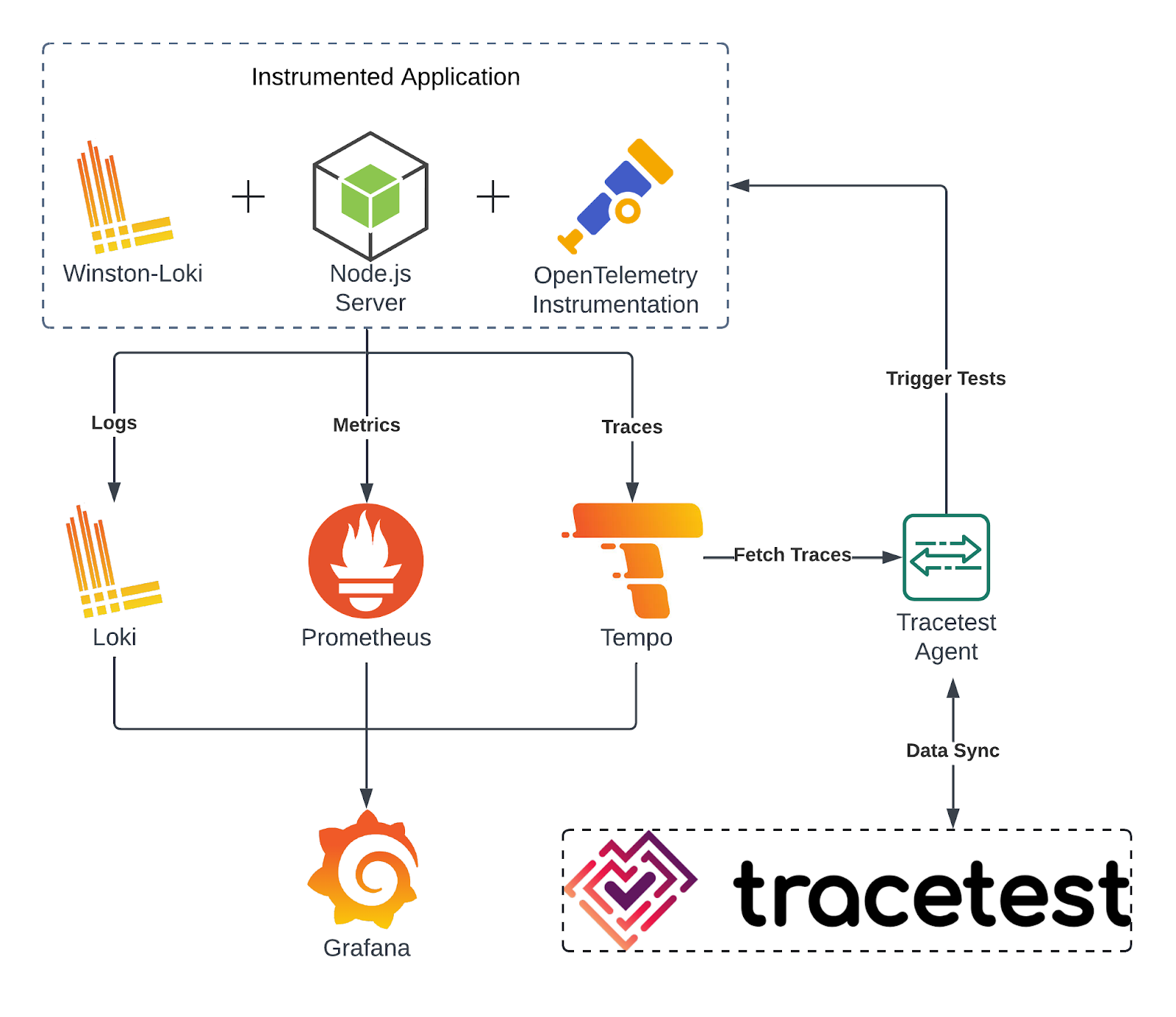
The LGTM Stack Components
Loki is basically "what if Prometheus but for logs?" It's cheaper than Elasticsearch because it doesn't index everything, which is great until you need to search for something specific and realize you should have just used ELK stack. Loki's lack of full-text search will bite you when some manager asks "find all logs containing customer ID 12345" and you realize you need to know the exact timestamp.
Tempo handles distributed tracing so you can figure out which microservice fucked up your request. Supports OpenTelemetry, Jaeger, Zipkin - all the usual suspects. When it works, tracing is magic. When it doesn't, you're debugging the tracing system instead of your actual problem. Tempo is great until you have one service generating 10x more spans than everything else and your storage costs explode.
Mimir is what you use when Prometheus falls over from too much data. Horizontal scaling, multi-tenancy, all that enterprise stuff. Still uses PromQL, so your existing queries work. Assuming you can figure out PromQL in the first place.
Grafana Alloy (formerly Grafana Agent) handles telemetry collection and forwarding. The config is actually readable, unlike most other collectors. Check their docs when you need specific deployment patterns - the community forums are where you'll end up when the docs don't cover your edge case.
Production War Stories (Learn From My Pain)
We had Grafana running for 2 years before realizing our Postgres datasource was timing out every query over 30 seconds. The default MySQL timeout is too short for large queries - bump it to 300 seconds or you'll hate your life.
The disk filled up with Grafana's SQLite database and took down monitoring during a production incident. Because nothing says "professional monitoring setup" like your monitoring dying when you need it most.
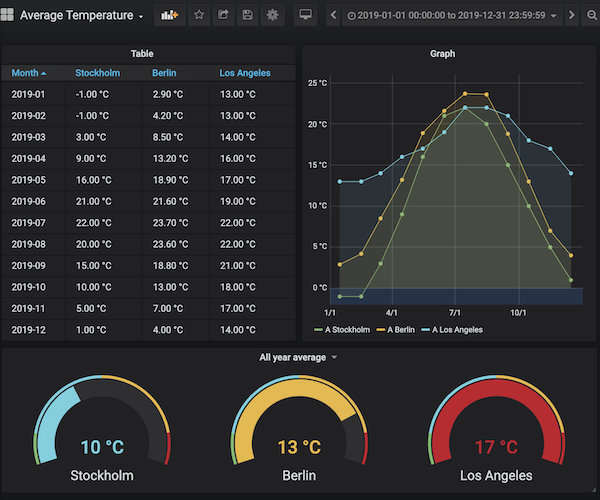
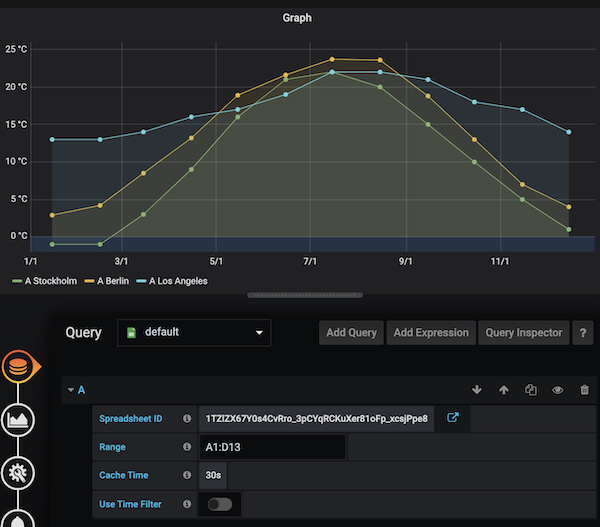
Spent 3 days debugging why dashboards were slow, turned out to be one rogue query scanning 6 months of data. Use the query inspector (that little inspect button) - it's your best friend for seeing why your PromQL is returning weird results.
Undocumented behaviors you'll discover at 3am: Grafana's auto-refresh stops working if you have the tab in the background for more than 10 minutes. Dashboard links break if you change the dashboard name, even though they should use UIDs. The 'Explore' feature is way faster than building test panels for debugging queries - use it.
Business Impact and Adoption
Grafana Labs is doing pretty well - they're not going anywhere, which matters when you're betting your monitoring stack on them. Not bad for a company that started because someone hated Graphite's UI.
Big companies like Salesforce, Bloomberg, and JP Morgan use this stuff because it works and doesn't cost as much as Datadog. Bloomberg probably has a team of 20 people just maintaining their Grafana cluster, but at least they can see all 50,000 metrics in one place.
Open Source vs Enterprise Offerings
Open source Grafana is actually pretty generous - unlimited everything, just no fancy enterprise features. Community support means Stack Overflow and hoping someone on GitHub Issues had your exact problem 3 years ago.
Grafana Cloud has a decent free tier - 10k metrics, 50GB logs/traces/profiles. You'll probably hit the limits faster than you think once you start monitoring real stuff, but it's way better than Datadog's "3 hosts and good luck" free plan.
Grafana Enterprise is what you buy when your compliance team won't shut up about SAML and audit logs. Priority support means they'll actually respond to your tickets in days instead of months, and won't immediately close them as "works on my machine."
Our Loki instance hit 95% disk usage and started dropping logs silently. No error messages, no alerts, just missing logs during our biggest outage of the year. Remember to monitor your monitoring system, because it will fail when you need it most.