GitOps means Git controls your deployments - no more logging into servers to run random kubectl commands at 2am when shit breaks. The core stack is Docker + Kubernetes + ArgoCD + Prometheus. When it works, it's actually pretty sweet. When it doesn't, you'll burn 6 hours debugging why ArgoCD is stuck syncing.
The Stack That'll Make You Question Your Life Choices
![]()
Look, here's the deal with GitOps: Git is your source of truth, which sounds great until ArgoCD decides it wants to take a coffee break and stops syncing for no fucking reason. I've spent more 3am nights debugging "why isn't this deploying" than I care to admit.
![]()
Docker: Containers are supposed to solve "works on my machine" but they just move the problem to "works in my container but not in prod." You'll spend hours debugging why your Alpine Linux container breaks when you need glibc libraries, or why your multi-stage builds work fine locally but fail in CI/CD pipelines.
![]()
Kubernetes: K8s is like that friend who's really smart but explains things in the most complicated way possible. Sure, it orchestrates everything beautifully, but try debugging why your pods are stuck in Pending state at 2am. The official troubleshooting guide won't help when you're dealing with resource quotas that somebody forgot to configure properly.
ArgoCD: The GitOps controller that's supposed to watch your Git repos and deploy changes automatically. Works great until it doesn't sync, shows "OutOfSync" for no reason, or gets stuck on that one namespace deletion that's been running for 3 hours. The ArgoCD troubleshooting docs are helpful until you hit edge cases that require diving into application resource management or understanding sync phases.

Prometheus: The monitoring stack that'll consume more RAM than your actual applications. Great for metrics until you realize you're storing high-cardinality data and your storage costs just doubled.
When It Actually Works (Sometimes)
GitOps automates deployments so you don't have to SSH into production servers and manually run kubectl commands like some kind of caveman. Until ArgoCD breaks, then you're back to manual debugging anyway.
Drift Detection: ArgoCD is supposed to keep your cluster in sync with Git. In theory, this prevents the clusterfuck of "who changed what in production." In practice, ArgoCD sometimes thinks your ServiceMonitor is out of sync even when it's not. Understanding drift detection mechanisms and sync policies becomes essential when dealing with server-side apply conflicts.
Monitoring Integration: Prometheus scrapes metrics from everything, including ArgoCD itself. Cool until you realize your monitoring stack is using more resources than the apps you're monitoring.
Multi-Cluster Pain: Sure, you can manage multiple clusters with one ArgoCD instance. Just be prepared for network timeouts, authentication issues, and that one cluster that randomly loses connection during your demo. The cluster management docs won't prepare you for debugging RBAC permissions across environments.
Real-World Implementation (AKA Where Dreams Die)
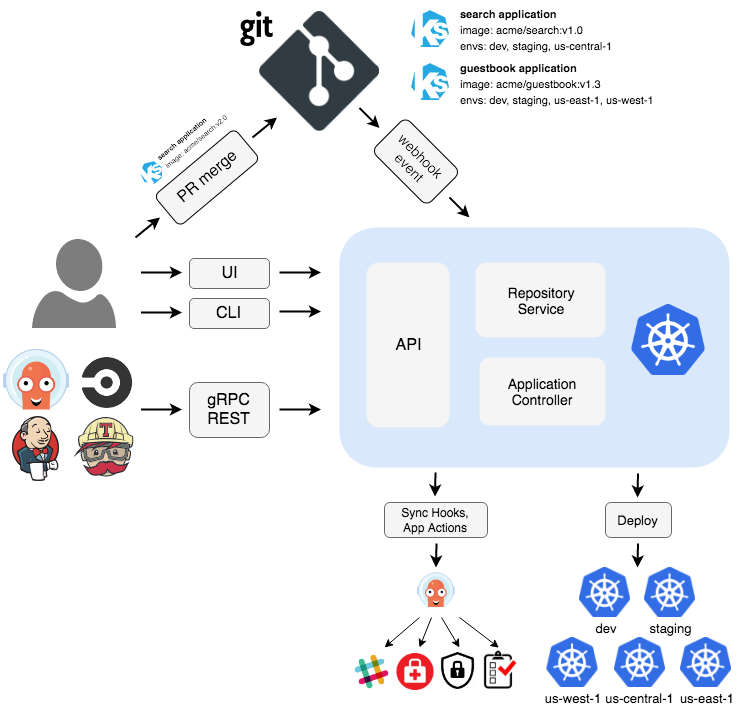
Most teams start with the app-of-apps pattern because it looks clean in diagrams. Then you realize managing 50+ applications through a single ArgoCD UI is like trying to herd cats through molasses.
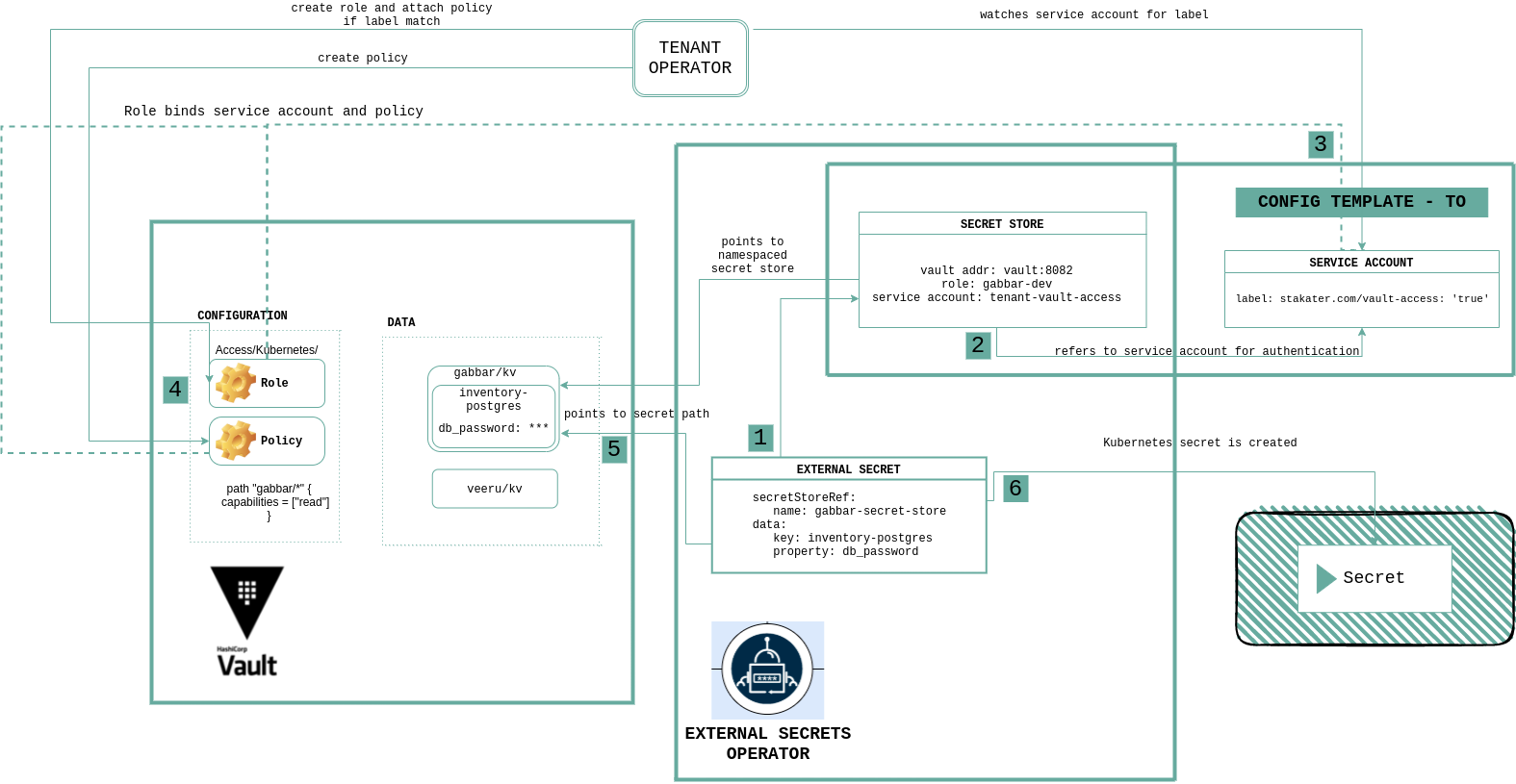
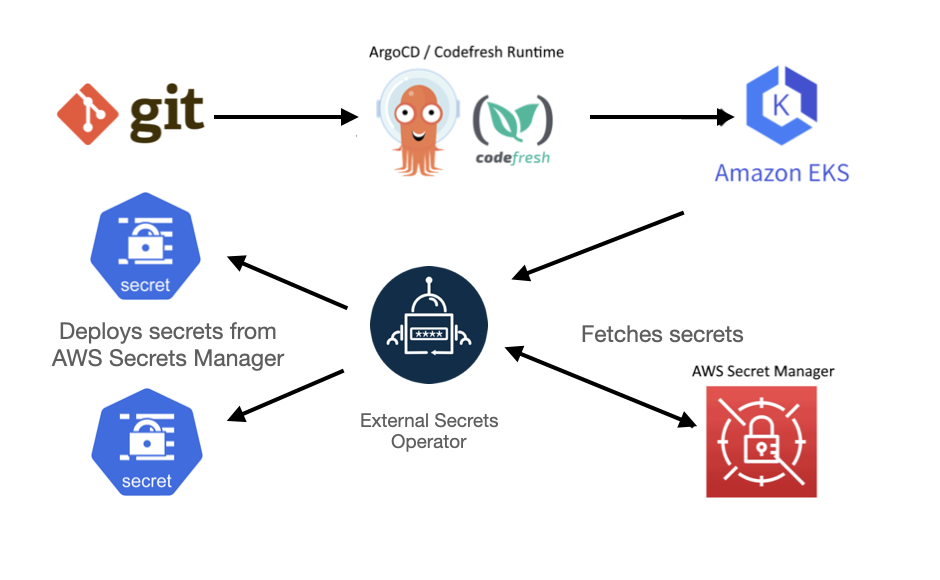
Secret Management: Never put secrets in Git. Use External Secrets Operator to pull from Vault or AWS Secrets Manager. This works great until your vault is down and nothing can start. Pro tip: your monitoring won't help because the monitoring needs secrets too. Learn about Kubernetes secrets and secret management best practices before you fuck up production.
Repository Structure: Separate your app configs from ArgoCD configs. Sounds obvious until you're 6 months in and your monorepo has become an unmaintainable mess of YAML files that nobody wants to touch.
Advanced Deployments: Argo Rollouts gives you canary deployments and blue-green releases. It's actually pretty sweet when it works. Just don't expect the rollback to work perfectly when your canary deployment takes down production.
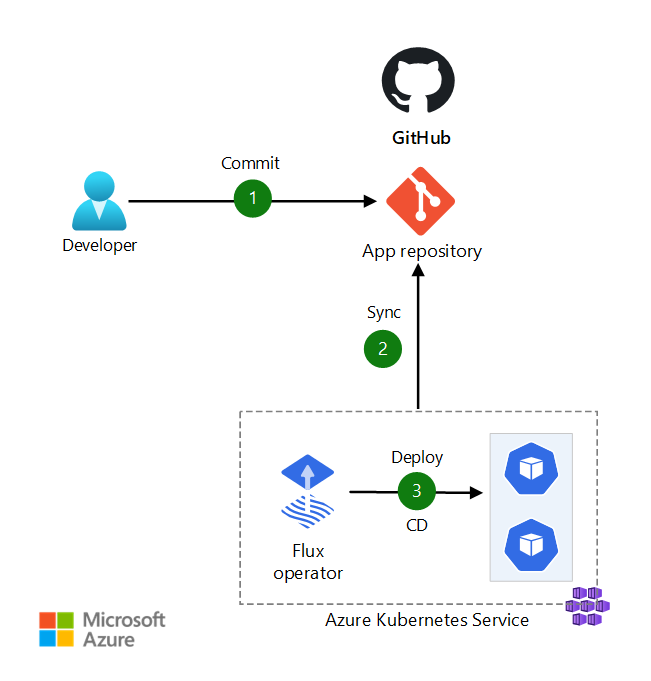
Bottom line: GitOps is better than manually deploying shit, but it's not magic. You'll still spend weekends debugging why your app won't start, except now you get to debug Kubernetes, ArgoCD, AND your application.
The real question isn't whether you should adopt GitOps - it's how to implement it without losing your sanity. Before you jump in, you need to understand the different approaches and what actually works in production environments where uptime matters and stakeholders are watching.