Pulsar is what happens when you decide Kafka's architecture is fundamentally broken and rebuild everything from scratch. Yahoo created it around 2013 because they needed something that could scale beyond Kafka's limitations. The current version is 4.1.0 released September 8, 2025, and it actually works - if you can handle the operational complexity.
The Architecture That Makes Your Life Complicated
Pulsar's layered architecture separates compute from storage, which is brilliant in theory. In practice, you're now running two distributed systems instead of one.
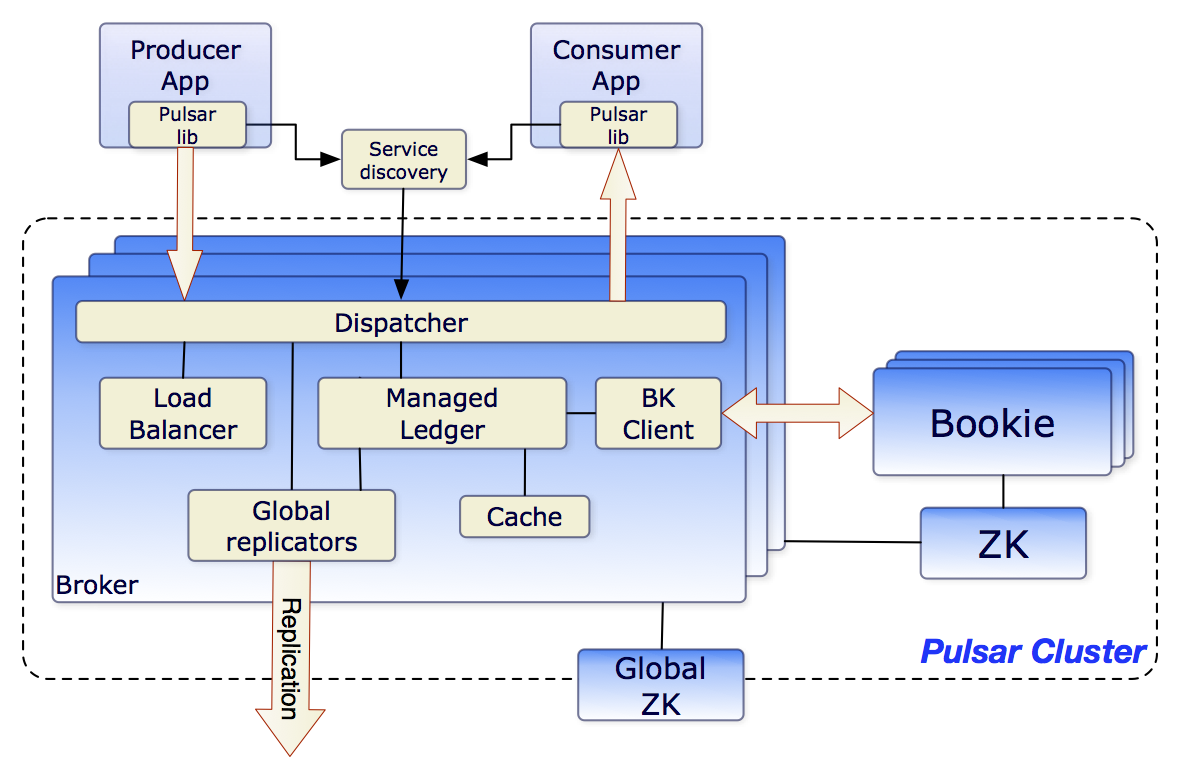
You've got four moving parts to worry about:
- Pulsar Brokers: These handle routing but don't store data. When they crash, your topics just migrate to other brokers. Sounds nice until you realize that the migration can take 30+ seconds and your clients start timing out.
- Apache BookKeeper: This is where your data actually lives. When BookKeeper has issues, you're in for a long night. And trust me, you'll see errors like
BKNotEnoughBookiesExceptionat 3am and wonder why you didn't just use Kafka. - Apache ZooKeeper: Because every distributed system needs ZooKeeper to make your life miserable. It'll work fine until you hit ~500K topics, then ZK becomes your bottleneck and you'll be optimizing JVM heap sizes.
- Pulsar Functions: Serverless stream processing that works great in demos, terrible for debugging in production. When a function fails, good luck figuring out which K8s pod it was running in.
The Multi-Tenancy Promise
Pulsar's multi-tenancy is actually pretty good. You get tenant isolation without running separate clusters, which saves on ops overhead. But good luck debugging cross-tenant issues when they happen.
Scale Reality Check
Can Pulsar handle millions of topics? Probably. Should you do that? Probably not unless you have a dedicated platform team. The theoretical limits are impressive, but the operational reality is that most people run into ZooKeeper bottlenecks long before they hit Pulsar's actual limits.
Yahoo runs this thing at massive scale, and it works for them. Whether it'll work for your use case depends entirely on whether you're willing to invest in understanding BookKeeper and ZooKeeper operational patterns.

