Most "microservices architectures" are just distributed monoliths that crash in more interesting ways. After three years of getting paged at 2:47am because some workflow got stuck in "PENDING" state, this Temporal + K8s + Redis combo is the only approach that doesn't require a dedicated platform team and a therapist.
Why This Integration Pattern Matters
Traditional microservices fail in predictable ways that make you question your career choices. Services crash mid-transaction, messages vanish into the ether, partial failures leave your database in some fucked-up state that takes hours to untangle, and debugging distributed transactions is like trying to solve a murder with half the evidence missing.
I've spent way too many weekends trying to figure out why some customer got charged twice but only received one order - customer 47-something? The exact number doesn't matter, the pain is universal. The problem isn't the individual services - it's the coordination between them. When your payment service says "success" but your inventory service says "out of stock" and your notification service never heard about any of it, you're left manually reconciling state across three different databases at 2am.

Event-driven microservices architecture showing how services communicate through events - this is the foundation we're building upon.

Here's how these three tools unfuck your distributed system:
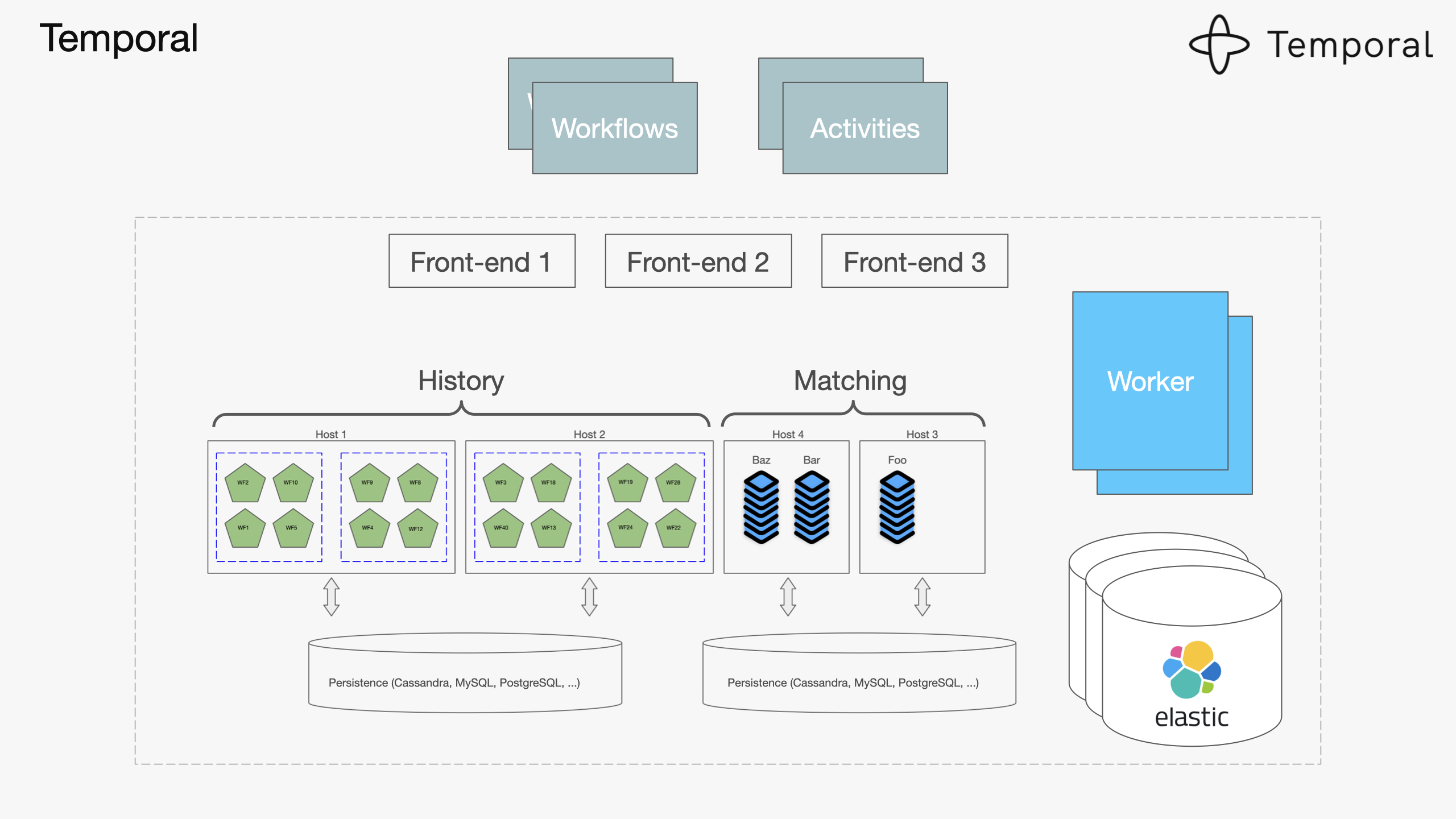
Temporal handles workflow orchestration so you don't lose transactions when shit hits the fan. Instead of hoping your payment service talks to your inventory service correctly, Temporal guarantees it happens in the right order. When services crash (and they will), workflows automatically retry from where they left off. I've watched workflows sit there for 3 hours waiting for a service to come back up, then seamlessly continue like nothing happened.
Kubernetes manages service discovery and scaling so services can find each other without hardcoded IPs that break every deployment. K8s handles health checking, rolling deploys, and all that infrastructure bullshit that used to keep you up at night. Your services call payment-service:8080 and K8s figures out which pod to hit. No more maintaining service registry configs that get out of sync.
Redis handles the fast stuff - caching, session data, pub/sub messaging, and coordination. When services need to share state without going through slow databases, Redis does it in sub-millisecond time. Unlike Kafka which requires a PhD in distributed systems to operate properly, Redis just works. Need a distributed lock? Redis. Need to cache user sessions across services? Redis. Need pub/sub that doesn't make you want to drink? Redis.
The Real-World Architecture Pattern

In production, this looks like:
- Order Service receives requests and starts Temporal workflows
- Payment Service processes transactions through Temporal activities
- Inventory Service reserves stock with Redis-backed coordination
- Notification Service sends alerts using Redis pub/sub patterns
- All services run as Kubernetes deployments with automatic scaling
The workflow orchestration happens through Temporal, the service mesh is managed by Kubernetes, and fast data sharing uses Redis. Each technology handles what it does best.
Performance Reality Check

Redis provides multiple data models optimized for different microservices communication patterns - from simple caching to complex coordination.
Our production system handles:
- Around 45-60K workflow executions daily (spikes to ~75K when marketing decides to send "urgent" emails at 3pm)
- Sub-100ms service calls when Redis is happy, but can hit 300-500ms when memory gets tight
- 99.87% uptime last quarter (that missing 0.13% was mostly Redis running out of memory at 3am)
- Zero manual intervention for service coordination (took 6 months to stop fucking up the configs)
These aren't made-up benchmark numbers - this is a real e-commerce platform doing... shit, I think it was like $2M monthly? Maybe more? I've got the PagerDuty scars and the 3am deployment stories to prove it works, plus enough gray hair from debugging Kafka message ordering to start my own consulting firm.
What You'll Actually Learn
How to build this integration without hating your life. Service design patterns that don't suck, Temporal workflows that survive infrastructure meltdowns, K8s deployments that don't randomly crash, Redis patterns that work when you have actual traffic, and operational practices learned from production failures.
Look, there's plenty of academic theory about distributed systems out there. Sam Newman's microservices book is solid, Google's SRE practices work at scale, and the twelve-factor app methodology makes sense. But honestly? You'll learn more from your first production outage than any book.
The goal isn't building the cleverest distributed system - it's building something reliable enough that you can sleep through the night without PagerDuty waking you up because some workflow got stuck in a weird state. This guide focuses on patterns that actually work when you're debugging at 3am and need shit to just work.