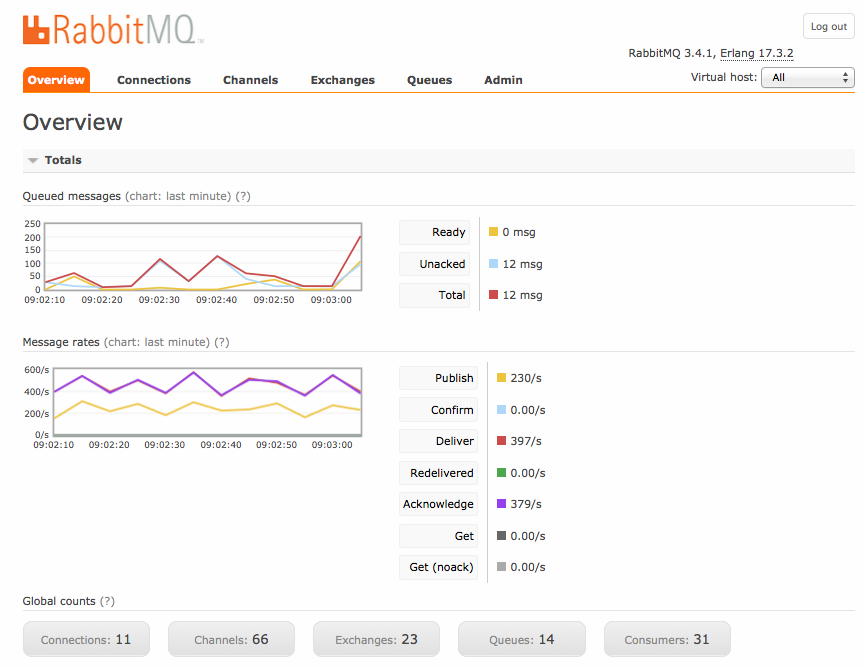
We've been running RabbitMQ 4.x for a year and change across a shitload of deployments - stopped counting after the K8s migration went sideways. Running whatever's the latest 4.1.x version right now. Those 50k msg/sec benchmarks? Yeah, good fucking luck with that.
Single Queue Bottlenecks Hit Hard
The problem: Single queues are single-threaded in RabbitMQ. We keep hitting walls around 25k-35k msg/sec in production - way lower than their pretty benchmarks. Community threads and Stack Overflow posts confirm others see the same shit.
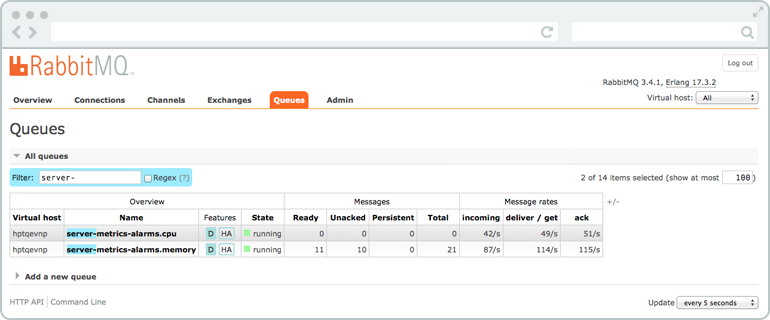
Our biggest deployment handles IoT telemetry from a fuckton of devices - maybe 50k? Had to shard across like 12 queues just to handle the peak load without everything falling over. It works, but now we're babysitting queue distribution logic instead of building actual features. Seriously, I've spent more time debugging load balancing between queues than I have implementing new business logic. Every team underestimates how much of a pain this becomes.
Memory Consumption: The Silent Production Killer
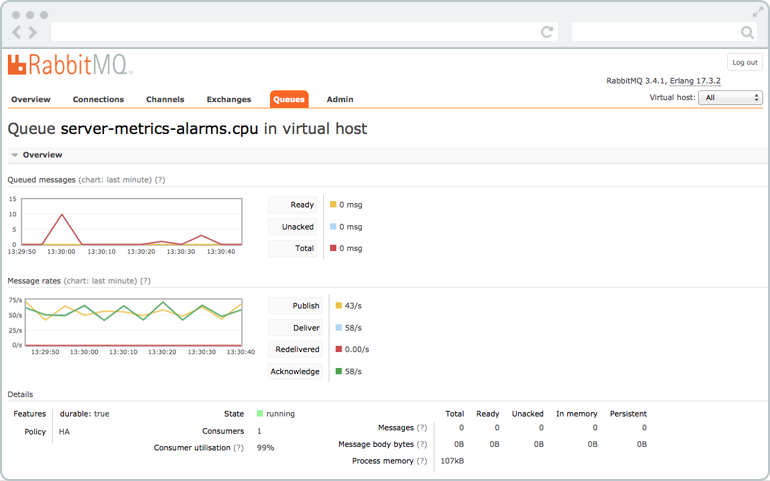
Here's what they don't tell you: RabbitMQ's memory usage grows like cancer with queue depth. Each message eats 1-4KB RAM depending on payload and metadata. Sounds small until you hit a backlog.
Learned this one the hard way during a weekend clusterfuck. Main service died around 2am - database was timing out or some shit - and messages just kept piling up while we were trying to figure out what the hell happened. Memory usage went absolutely nuts - think it hit 300GB or something insane before our alerts finally woke us up. RabbitMQ memory docs mention this but they should put it in 72pt red text: "THIS WILL KILL YOUR CLUSTER."
Memory exhaustion triggers flow control, which blocks everything. Not just the problematic queue - the whole damn cluster locks up. Configure memory limits from day one or you'll be debugging at 3am like we were. Monitoring guides and alerting best practices become essential.
Persistence Performance: The Trade-off Tax
Enabling message persistence absolutely destroys throughput. Non-persistent messages? Maybe 45k msg/sec if you're lucky. Turn on persistence? Drops to like 12k msg/sec on the same hardware. It's brutal.
Real talk: We run dual setups now. Persistent queues for business-critical stuff (payments, orders) and non-persistent for metrics and logs. It's more infrastructure to manage, but beats having one slow-ass queue for everything. Persistence configuration docs and durability trade-offs explain the technical details.
Clustering: Powerful But Operationally Demanding
RabbitMQ clustering handles failover okay, but network hiccups will absolutely ruin your day. Worst outage we had? Network went to shit between nodes for maybe 30 seconds. Boom - split-brain scenario that we had to fix by hand at 4am.
Lesson learned the hard way: Run odd numbers of nodes (3, 5, 7) and configure partition handling modes before you go live. The default "ignore" mode is basically asking for trouble. RabbitMQ clustering documentation and partition handling strategies saved our ass multiple times.
Version 4.x Improvements: Streams Change the Game
The streams feature in RabbitMQ 4.x fixes a lot of the traditional performance bullshit. Streams let multiple consumers read the same data and support replay capabilities like Kafka topics.
In our testing, streams push like 150k+ msg/sec per stream - way better than regular queues. But here's the catch: streams need different client libraries and totally different code patterns. If you've got existing AMQP code, migration isn't just flipping a switch - it's a proper rewrite. Stream documentation looks promising, but migration guides make it clear you're in for some work.