The Reality of Distributed Logging
Your logs are scattered across 50 different places and when something breaks, you're fucked. EFK fixes this by sucking all your logs into one place so you can actually find the error that's crashing your app at 2am on Sunday.
What Each Component Actually Does

Elasticsearch is your search engine. Think Google but for your application logs. It indexes everything so you can search for that specific NullPointerException instead of tailing log files like a caveman. Warning: Elasticsearch 8.10+ has a nasty bug where it crashes with OutOfMemoryError: Java heap space if you hit it with too many concurrent searches - plan your cluster sizing accordingly.
Fluentd collects logs from everywhere. Unlike Logstash which needs 200MB just to start up, Fluentd runs on 30MB and actually stays running. Written in Ruby but the important parts are in C, so it's fast where it matters. Pro tip: Fluentd 1.16.2 has a memory leak when processing JSON with null values - took me 6 hours to figure that out during a weekend outage. The tag-based routing means you can send different logs to different places without building a nightmare pipeline.

Kibana turns your logs into pretty graphs. More importantly, it lets you search and filter without having to remember Elasticsearch's query syntax every damn time.
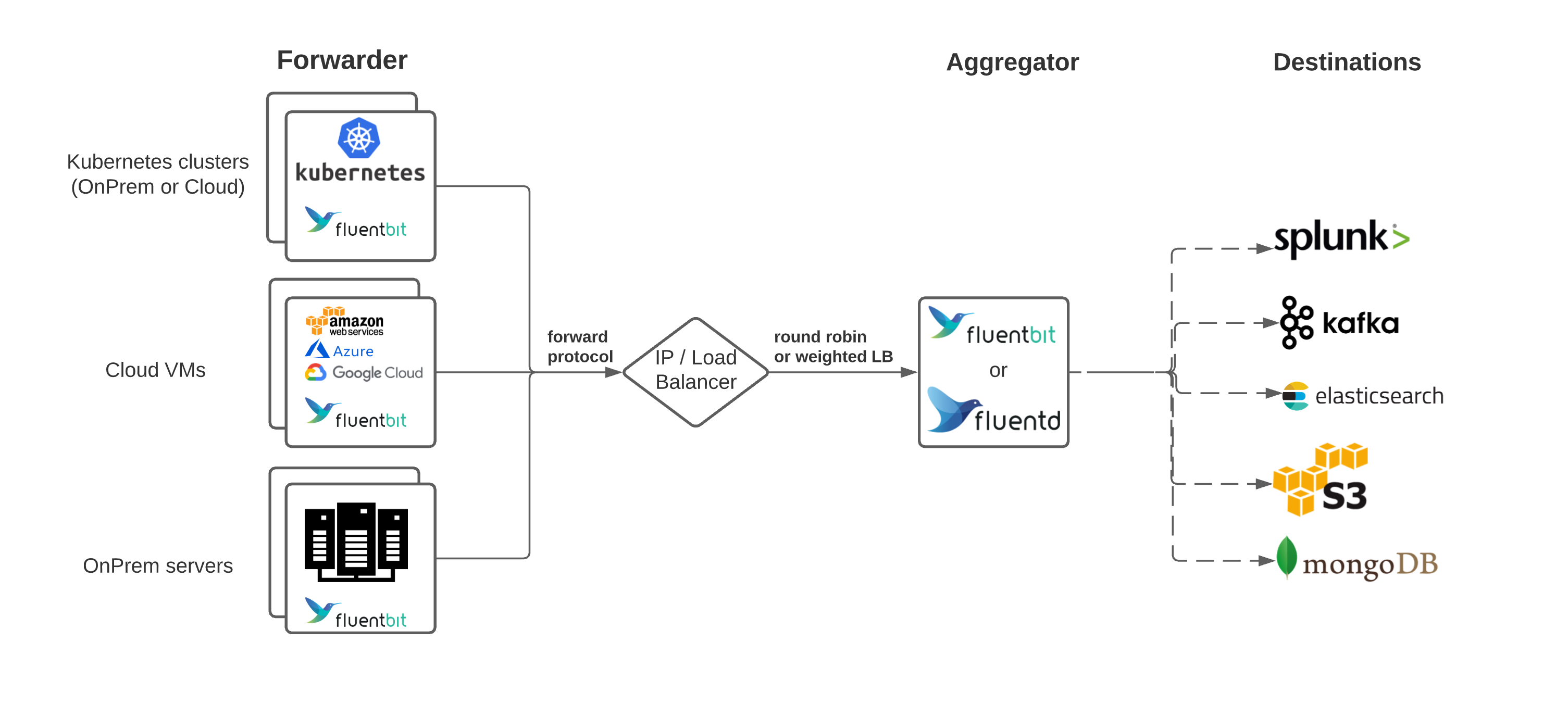
Deployment Patterns That Actually Work
Direct Setup: Every server sends logs straight to Elasticsearch. Works until you hit about 50 servers, then Elasticsearch starts choking on the connections and you get CONNECT_ERROR spam in your Fluentd logs. Good for getting started, bad for staying employed when it crashes during peak traffic.
Aggregator Setup: Smart move - Fluentd agents forward to central Fluentd aggregators, which buffer and batch logs before sending to Elasticsearch. This is what you want in production because it handles network hiccups and load spikes without losing data.
Multi-Region Nightmare: If you're running across multiple clouds or regions, you'll need regional Elasticsearch clusters with cross-region forwarding. Expensive but necessary if you want sub-second query response times globally.
Performance Reality Check
Fluentd uses 30-40MB of memory. Logstash needs 200-300MB just to exist. In containers, this difference will save you serious money - we're talking 5x more Fluentd instances per node.
Elasticsearch scales horizontally, but here's what the docs don't tell you: your JVM heap hits a wall at 32GB. Beyond that, you need more nodes, not bigger ones. Plan for 1TB indexed per day to need about 3-4 data nodes with proper SSDs.
The dirty secret: Elasticsearch will crash if you run out of disk space with a cryptic blocked by: [FORBIDDEN/12/index read-only / allow delete (api)] error. Set up index lifecycle management or prepare to get paged at 3:15am when your logs fill the disk and everything stops working. Been there, done that, bought the t-shirt.