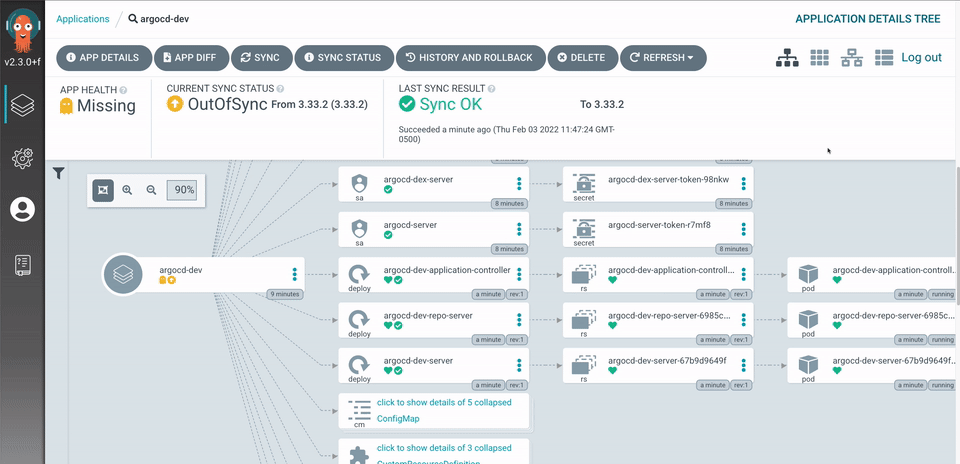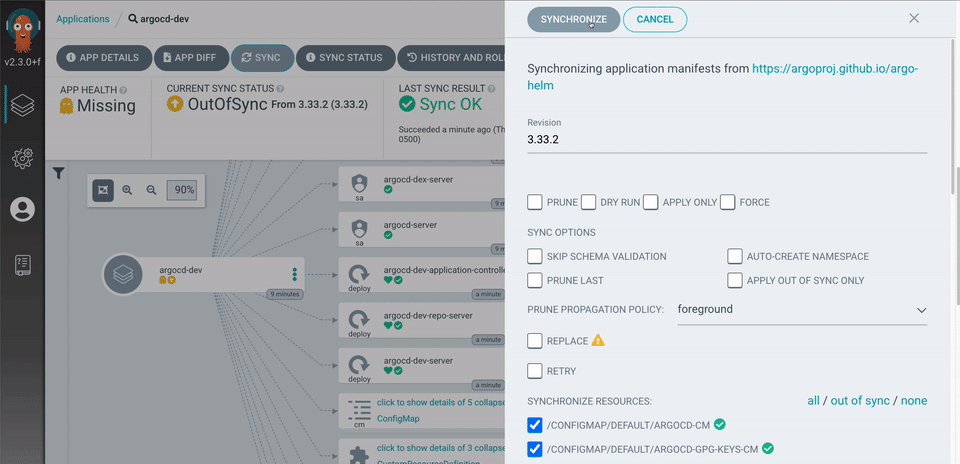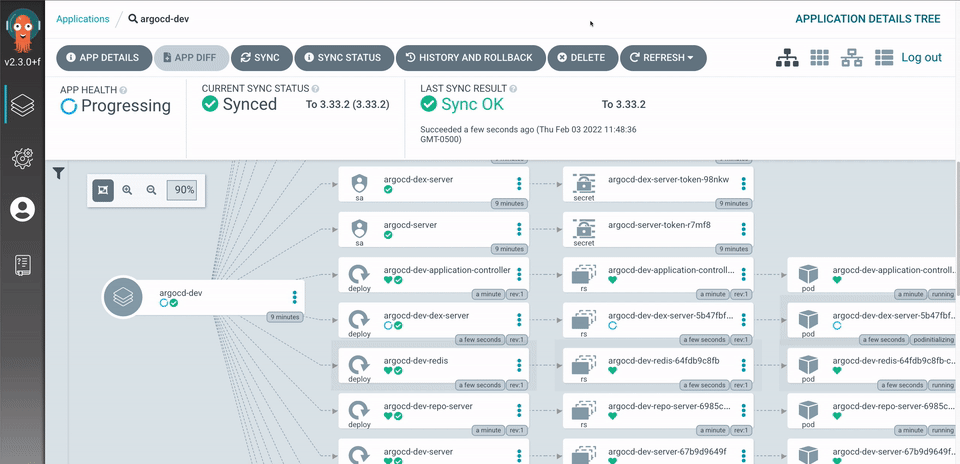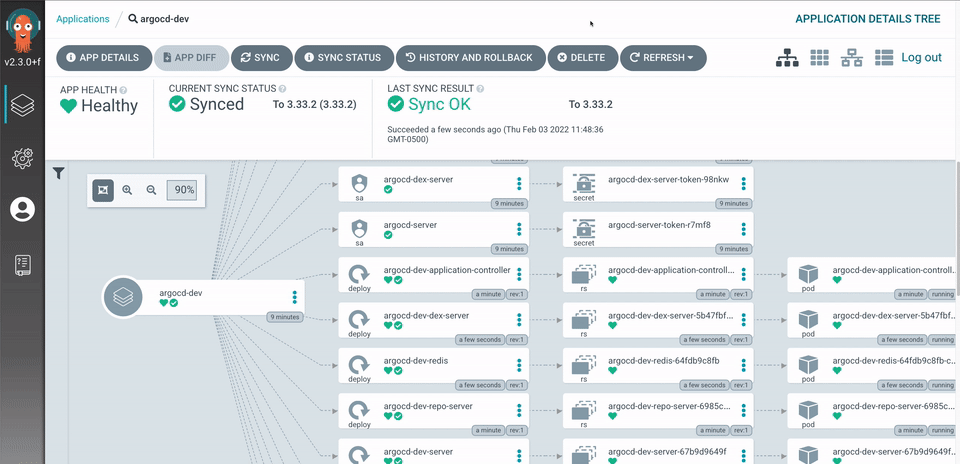
Let's be honest - most Kubernetes clusters are security disasters waiting to happen. I've seen production clusters where everything runs as cluster-admin, network policies don't exist, and someone thought putting a reverse proxy in front was "good enough." Spoiler alert: it wasn't.
The Kubernetes Trust Problem (AKA Why Everything is Broken)
Traditional security assumes you have a nice, neat perimeter you can defend. Kubernetes throws that out the window and lights it on fire:
Your Pods Don't Have Real Identity: That web service that was running on 10.244.1.45 two minutes ago? It's now on 10.244.3.12. Good luck maintaining firewall rules. IP-based security in Kubernetes is like trying to nail jello to a wall - messy and ultimately pointless.
Everything Talks to Everything: Most clusters have zero network segmentation. One compromised pod can pivot to your database, your secrets, your other services, your coffee machine - basically everything. I've seen lateral movement happen in under 10 minutes from initial compromise.
You're Running a Multi-Tenant Nightmare: Your "secure" application is sharing kernel space with that sketchy service from the intern project. Container isolation is better than nothing, but it's not magic. When someone inevitably breaks out of a container, they're on the same node as your critical stuff.
What Zero Trust Actually Means (Beyond the Marketing BS)
Zero Trust means every service has to prove who it is before talking to anything else. No more "I'm inside the network so I must be trustworthy" bullshit. Every request gets challenged.
Never Trust, Always Verify: Every connection between pods gets mutual TLS. Every API request gets authenticated. Every image gets signed and verified. Yes, it's annoying. Yes, it breaks things initially. Yes, it's worth it when someone inevitably gets pwned.
Assume You're Already Compromised: Because you probably are. Design everything assuming an attacker is already in your cluster. When they compromise one pod, they should hit a wall trying to go anywhere else. That's the whole point - contain the damage.
Least Privilege (Actually This Time): Most service accounts have way too many permissions because it was easier than figuring out what they actually need. That ends now. Each service gets exactly what it needs to function, nothing more.
Service Mesh: Your Best Bet for Not Fucking This Up

Service meshes handle the crypto and identity stuff you'll inevitably screw up if you try to roll your own. Linkerd is probably your best starting point - less complexity than Istio, more mature than everything else. The CNCF service mesh landscape shows your options, but most are overly complex or undercooked.
The beauty is it works with normal Kubernetes stuff you already understand. ServiceAccounts become real identities with actual certificates. Network policies actually matter. RBAC stops being a checkbox exercise.
Reality Check: This Takes Forever
Zero Trust implementation is measured in quarters, not sprints. I've seen companies take 18+ months to get it right in production. The NIST Zero Trust Architecture framework provides realistic timelines. Start with your most critical stuff and expand slowly. Google's BeyondCorp took them years to fully implement, and they invented half this shit.
DO NOT try to flip the switch on everything at once. Your developers will hate you, your apps will break in creative ways, and you'll spend your nights debugging certificate rotation issues. Ask me how I know. The Kubernetes security best practices document outlines a gradual approach. CISA's Zero Trust maturity model shows how to phase implementation properly. Even Microsoft's Zero Trust implementation guide recommends starting small and expanding incrementally.
Start with the Kubernetes Pod Security Standards to get baseline security right first. Read Aqua Security's Kubernetes security checklist for a practical implementation roadmap. The CIS Kubernetes Benchmark provides detailed hardening guidelines that actually work in production environments. OWASP's Kubernetes Security Cheat Sheet covers the gotchas you'll encounter, while Sysdig's Kubernetes security guide explains the runtime security aspects you can't ignore.
The NSA/CISA Kubernetes Hardening Guide provides government-grade security recommendations. Falco's threat detection rules help with runtime monitoring, and Istio's security model demonstrates advanced service mesh security patterns. The Kubernetes Network Policy recipes repository offers practical examples for network segmentation.