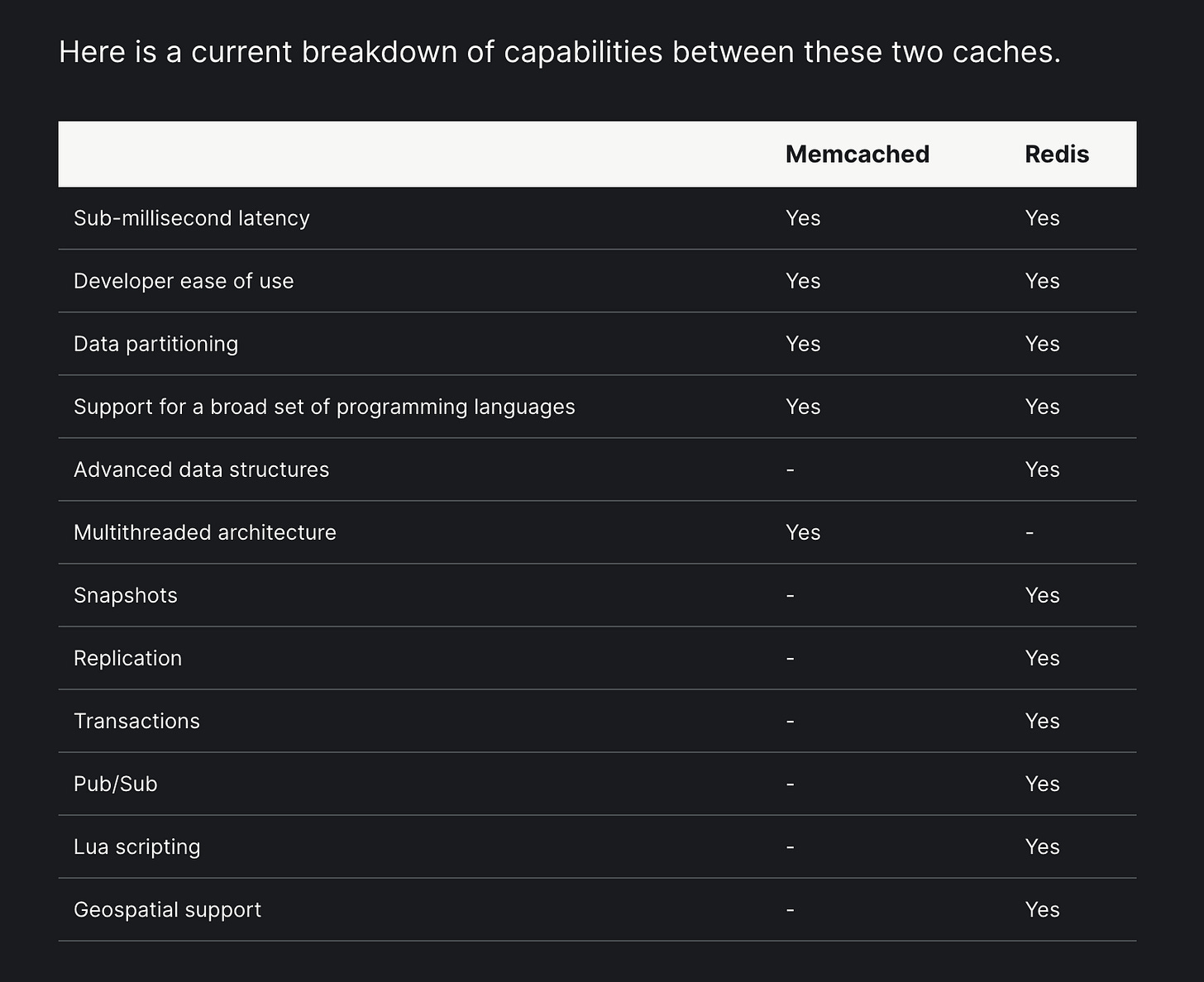
The "ERR max number of clients reached" error strikes when Redis reaches its connection limit and starts rejecting new clients. But here's the brutal reality: your application doesn't gracefully degrade when this happens - it just fucking breaks. New requests fail instantly, connection pools starve waiting for available connections, and your entire service architecture crumbles in a cascade of failures.
I first encountered this on a Tuesday morning in production when our microservices started cascade-failing one by one. The Redis dashboard showed 9,999 connections stuck open, and new services couldn't get in. What made it worse? Our Kubernetes deployment was auto-scaling pods based on CPU usage, creating even more connection attempts while Redis was already maxed out. Fun times.
What Actually Triggers This Clusterfuck
Redis caps concurrent connections to prevent resource exhaustion, but here's the gotcha: the default 10,000 limit assumes your OS can handle it. Most production systems can't.
Real-world problem: Your Ubuntu server ships with `ulimit -n 1024` by default. Redis reserves 32 file descriptors for itself, leaving you with ~992 usable connections - not the 10,000 you expected. I learned this the hard way when our "high-capacity" Redis setup could barely handle 900 concurrent users during Black Friday 2023, a classic gotcha detailed in Redis connection best practices.
Version-specific gotcha: Redis 3.2+ has better file descriptor handling, but Redis 2.8 will silently reduce your maxclients without warning. I learned this the hard way when our "upgraded" Redis 2.8 instance quietly dropped from 10,000 to 992 connections during a migration, causing connection failures that took hours to track down. Always check your version with `redis-server --version` and don't assume anything.
Redis 8.x improvements: If you're running Redis 8.0 (released May 2025) or Redis 8.2 (released August 2025), you get significant performance improvements with up to 87% faster commands and better memory efficiency. Performance gains are substantial, but connection handling fundamentals remain the same - file descriptor limits still apply.
Why This Happens (From Someone Who's Fixed It 20+ Times)
The Real Culprits (In Order of How Often I See Them):
Shitty connection management in your app - 70% of cases
- Python developers forgetting to use connection pools (guilty as charged)
- Node.js apps creating new Redis clients per request instead of reusing
- Java apps with misconfigured Jedis pools that never return connections
- Django Redis connection issues are particularly common
Docker memory limits fucking with file descriptors - 20% of cases
- Container has `ulimit -n 1024` while Redis config says
maxclients 10000 - Kubernetes resource limits don't account for connection overhead
- That one time AWS ECS defaulted to tiny ulimits and nobody noticed
- Container has `ulimit -n 1024` while Redis config says
Zombie connections from crashed processes - 10% of cases
- Kubernetes pods getting killed mid-operation, connections stay open
- TCP keepalive disabled, so Redis doesn't know clients are dead
- Connection leak in Flask-Redis that haunted us for weeks
The System Reality Check:
Run ulimit -n right now. If it's 1024 or less, you're fucked. Redis does the math: available FDs minus 32 reserved equals your actual limit. So that 10,000 connection dream becomes a 992 connection nightmare.
How This Breaks Your Day (Real Impact Stories)
Existing connections keep working, but new ones get rejected. Sounds manageable until you realize most apps rely on connection pools that panic when they can't grow.
What you'll see in your logs:
- Python redis-py:
redis.exceptions.ConnectionError: max number of clients reached - Node.js ioredis:
ReplyError: ERR max number of clients reached - Java Jedis:
JedisConnectionException: Could not get a resource from the pool - Go redis/go-redis:
dial tcp: connection refused(misleading as fuck)
Real production war story:
Our microservices architecture had 15 services sharing one Redis instance. When the connection limit hit during Black Friday traffic, services started timing out waiting for pool connections. The cascade effect took down our entire checkout flow because everything depends on Redis sessions. The worst part? Our Spring Boot applications were configured with default Lettuce connection pools, which silently queue requests instead of failing fast - so we didn't even realize the problem for 12 minutes while orders were failing silently.
Time to recovery: 2 minutes if you know what you're doing, 2 hours if you're reading documentation while your CEO is asking questions.
Diagnostic Commands That Actually Help
Stop reading theory and run these commands right fucking now:
## Check your current death spiral
redis-cli INFO clients | grep connected_clients
## See who's hogging connections (spoiler: probably your own app)
redis-cli CLIENT LIST | head -20
## The nuclear option - kill everything idle > 60 seconds
redis-cli CLIENT LIST | grep "idle=" | awk '$0 ~ /idle=[6-9][0-9]/ {print $2}' | cut -d= -f2 | xargs -I {} redis-cli CLIENT KILL addr={}
## Watch connections in real-time (Ctrl+C when you've seen enough)
watch -n 1 'redis-cli INFO clients | grep connected_clients'
Production debugging session transcript:
$ redis-cli INFO clients | grep connected_clients
connected_clients:9998
$ redis-cli CONFIG GET maxclients
1) "maxclients"
2) "10000"
## Oh fuck, we're 2 connections from disaster
$ redis-cli CLIENT LIST | grep idle=0 | wc -l
3847
## 3847 active connections?! That's not right...
Key numbers to watch:
connected_clients: How fucked you are right nowrejected_connections: How long this has been a problemmaxclients: Your theoretical limit (probably not your real limit)
AWS ElastiCache tracks this as CurrConnections in CloudWatch, but by the time that alert fires, you're already having a bad time.
The difference between a 5-minute fix and a 2-hour outage is knowing these commands before you need them. Print this shit out and tape it to your monitor.
Now that you understand why Redis connection limits become a nightmare and how to diagnose what's eating your connections, it's time for the real solutions. We'll start with emergency triage to stop the bleeding immediately, then move to permanent fixes that ensure this crisis never happens again.