Your FastAPI app is humming along nicely in a single Docker container. Then one day you wake up to 500 errors, angry users, and a server that died sometime around 2am. Welcome to the production nightmare nobody warned you about.
Before you dive into Kubernetes complexity, ask yourself: are you actually at the point where you need this? Because K8s will consume your life for the next 3 months while you figure out why pods are stuck in Pending and why your health checks are lying.
The "Oh Shit" Moments That Led Me Here
Here's when you know you've outgrown simple deployments:
Your server died and took everything with it. That AWS instance just... stopped existing. Your app, your database connections, your uptime - all gone. You spent 6 hours setting up a new server from scratch while your boss asked when the site would be back up.
A traffic spike killed your app. Traffic came from somewhere - maybe Reddit, maybe a bot, who knows - and everything just died. Your single FastAPI process couldn't handle whatever the hell hit it and just started returning 500s. You watched helplessly as potential customers bounced while trying to figure out where the traffic even came from.
Deployments became a nightmare. I was deploying on a Tuesday afternoon and somehow broke user authentication for 3 hours. You're SSH'd into the server at 11pm on a Friday, carefully running docker-compose down && docker-compose up -d and praying nothing breaks. Half the time you forget to run migrations first. The other half you realize you need to rollback but don't have a clean way to do it.
Configuration hell. You've got prod secrets scattered across environment files, some hardcoded values that differ between environments, and database URLs that you copy-paste between servers while hoping you don't fuck up the connection string.
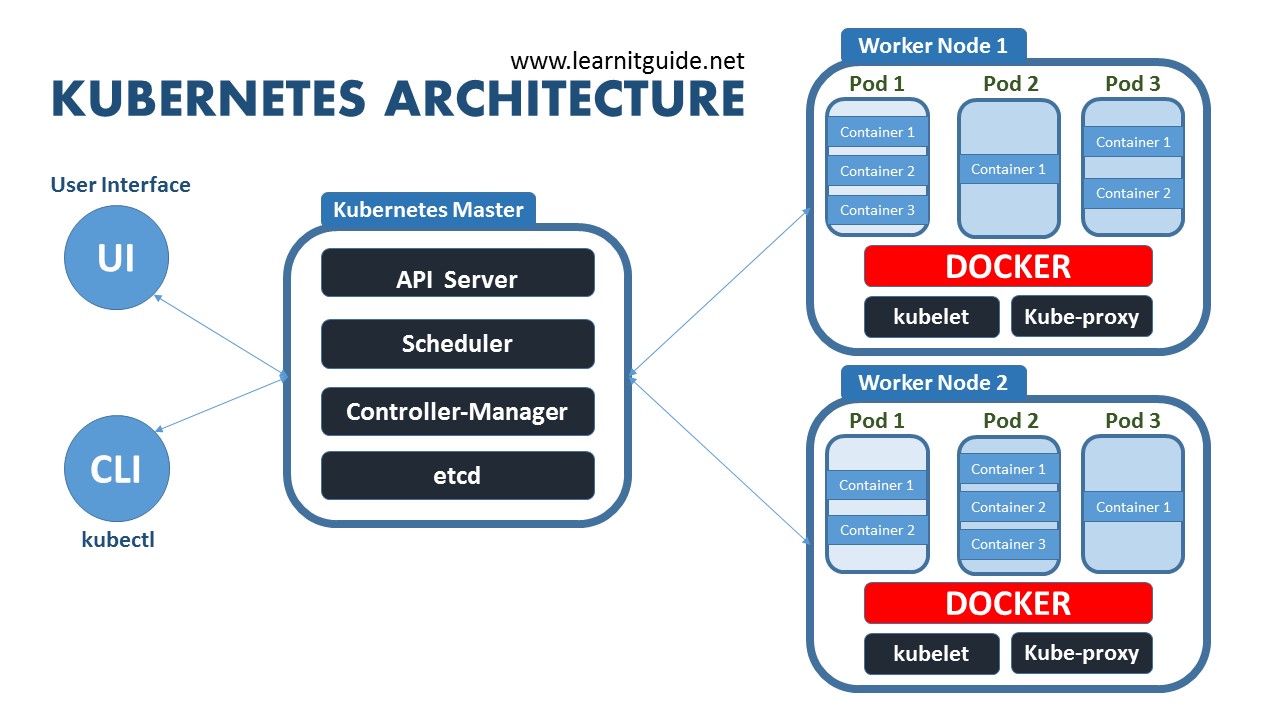
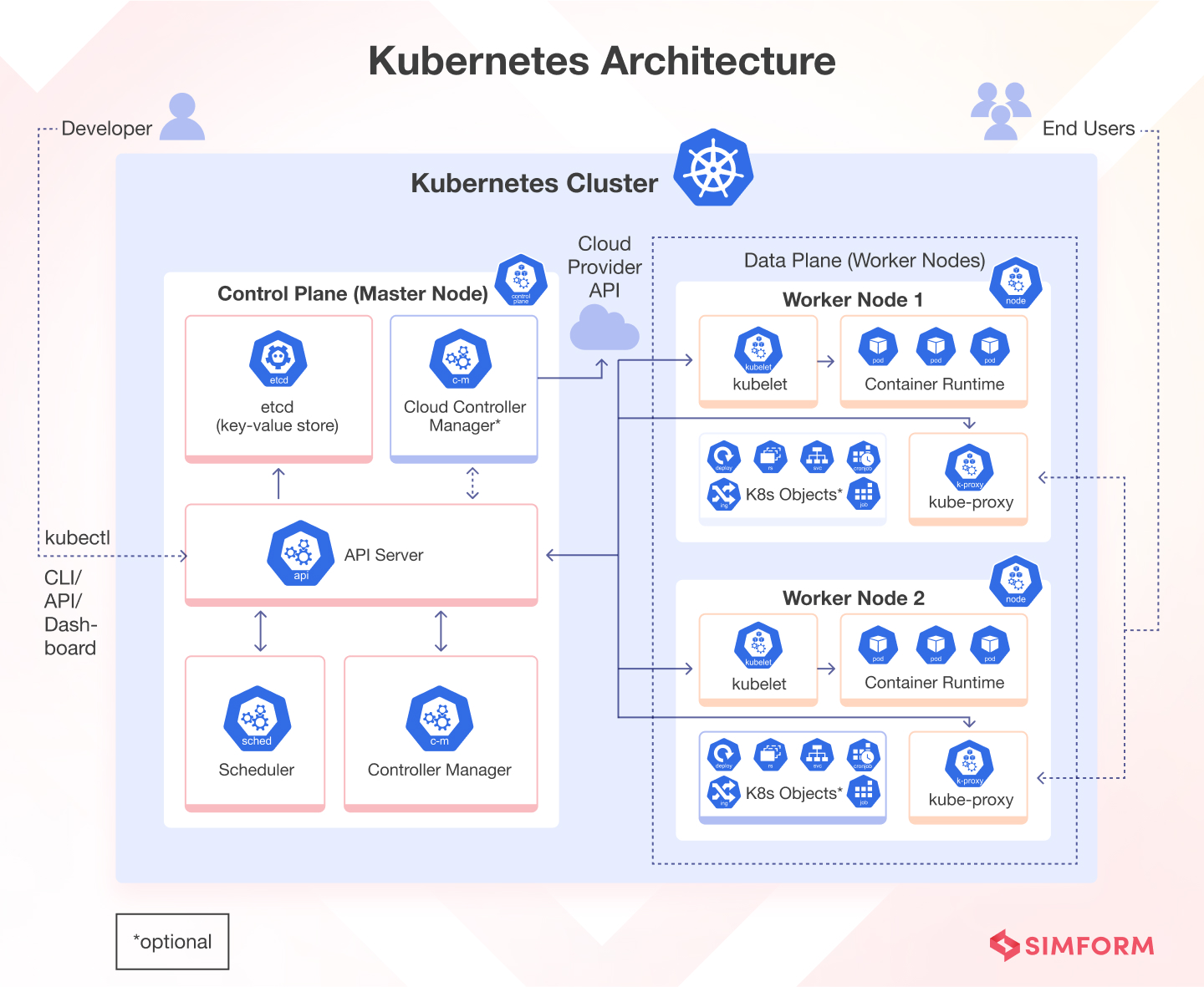
Why FastAPI Actually Works Well with Kubernetes (Once You Get Past the Initial Hell)
Look, FastAPI's async nature means it doesn't waste resources sitting around waiting for database queries. In Kubernetes, this translates to being able to pack more traffic into fewer pods, which saves you money on your AWS bill. But here's the thing about those health checks everyone raves about...
You can set up /health endpoints that actually tell you when your app is broken, instead of returning 200 while your database connections are dead. Sounds great, right? Well, those same health checks will fucking kill your pods during database outages if you make them depend on external services. I learned that one the hard way during what was supposed to be a "5-minute maintenance window" that turned into 3 hours of RDS being completely unreachable, and Kubernetes just kept killing healthy pods because they couldn't ping the database.
Realistic performance expectations: On decent hardware with proper async database connections, you'll get around 15-20k requests per second per pod - but that's with empty endpoints doing nothing. In the real world with database queries, external API calls, and actual business logic, expect 3-8k req/sec per pod. The TechEmpower benchmarks showing 21k+ are synthetic bullshit that test returning "Hello World" - your actual app with authentication, database calls, and logging will be nowhere close.
The official FastAPI documentation explains the async benefits in detail, while Kubernetes architecture docs cover why this distributed approach actually works.
What You're Actually Getting Into
Here's the reality of a production FastAPI Kubernetes setup:
YAML Hell: Your app is now defined by 12 different YAML files that you'll constantly be editing. Resource limits, health checks, ingress rules, config maps - it never ends. Every simple change requires touching multiple files.
Secrets Management That Actually Works: Instead of environment variables scattered everywhere, your database passwords and API keys live in Kubernetes Secrets. Base64 encoded (which is NOT encryption, despite what tutorials imply). For real production security, consider Sealed Secrets or External Secrets Operator.
Health Checks That Might Work: Set up /health endpoints that Kubernetes can ping. When they return 200, your pod is "healthy". When they don't, Kubernetes kills your pod. The tricky part is making these checks actually meaningful without killing pods during database maintenance.
Load Balancing That Mostly Works: Ingress controllers handle SSL and routing. NGINX Ingress is rock solid. Traefik looks fancier but has weird edge cases that will bite you. For cloud providers, AWS Load Balancer Controller and GCP Ingress work well.
The Real Cost of Kubernetes
Time investment: Plan on 2-3 weeks minimum to get a basic production setup working. Then another month to understand why things randomly break.
Money investment: A real production cluster costs at least $500/month on AWS. Maybe $300 if you optimize aggressively and don't mind spending weekends tuning resource limits.
Mental health investment: You'll spend a lot of time debugging why pods are stuck in Pending status. Usually it's resource limits, IP address exhaustion, or some other cluster-level issue that takes hours to diagnose.
When NOT to Use Kubernetes
Seriously consider these alternatives first:
- Railway: If you just need to deploy FastAPI apps without infrastructure nightmares
- Docker Swarm: For teams that know Docker but don't want Kubernetes complexity
- DigitalOcean App Platform: Managed container hosting that's simpler than K8s
- Good old VPS: If your traffic is predictable and you don't mind manual deployments
The point where Kubernetes becomes worth it is when you're serving enough traffic that downtime costs you actual money, and you have the team bandwidth to manage the operational overhead. For detailed comparisons, check out CNCF's landscape and Kubernetes deployment patterns.
Look, I know everyone says "just use Kubernetes" but let's be fucking honest about what each option actually costs you in time and money before you commit to months of YAML hell.