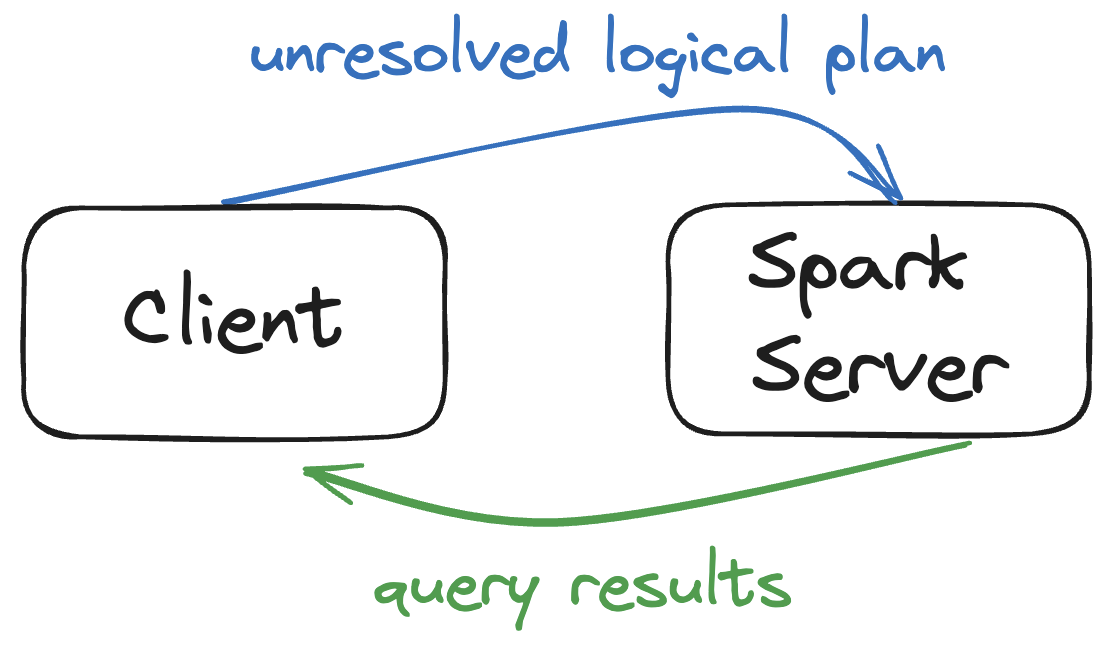
Apache Spark was built at UC Berkeley in 2009 because Hadoop MapReduce was slower than molasses and made simple data processing jobs take hours. The academics got it right this time - Spark actually works, mostly.
The Reality of Spark Performance
That "up to 100 times faster than Hadoop MapReduce" claim? It's technically true for specific workloads where your data fits in memory and you've spent weeks tuning your cluster. In practice, expect 10-20x improvements, and that's after you've figured out why your jobs keep running out of memory.
The speed comes from keeping data in RAM instead of constantly writing to disk like MapReduce. But here's the catch: memory management is a nightmare, and you'll spend more time tuning JVM garbage collection settings than writing actual code.
Architecture That Sounds Simple (Until You Debug It)
Spark uses Resilient Distributed Datasets (RDDs) - immutable collections that get split across your cluster. The "resilient" part means when something breaks (and it will), Spark can recreate the data. The "distributed" part means when things go wrong, good luck figuring out which machine is the problem.
The framework runs on a driver-executor architecture:
- Driver Program: The control center that crashes when you run out of memory
- Cluster Manager: Allocates resources (supports Standalone, YARN, Kubernetes, and Mesos - choose your poison)
- Executors: Worker nodes that do the actual processing and occasionally die for reasons like "Container killed by YARN for exceeding memory limits" or the classic "java.net.SocketTimeoutException: Read timed out"

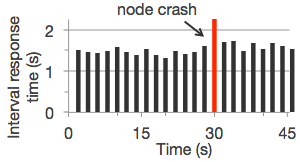
What they don't tell you: The "simple" driver-executor model hides incredible complexity. When your driver crashes with an OutOfMemoryError, you'll discover that debugging distributed systems is like finding a needle in a haystack while blindfolded.
Language Support (Choose Your Struggle)
Spark supports multiple languages, each with its own special pain points:
- Scala: The "native" language that Spark was written in. Functional programming purists love it, everyone else finds the syntax confusing as hell
- Python (PySpark): Most popular choice because Python is everywhere. Performance takes a hit due to serialization overhead, but you'll use it anyway
- Java: For enterprise environments where someone decided Java was mandatory. Works fine but verbose as fuck
- R (SparkR): For statisticians who haven't discovered Python yet. Limited API coverage
- SQL: Query structured data using Spark SQL - actually pretty decent and sometimes faster than the APIs
Version Status (Current as of Sep 2025)
Apache Spark 4.0.1 dropped on September 6, 2025, with the usual mix of new features and breaking changes. Preview releases of Spark 4.1.0 are already available if you enjoy living dangerously in production.
Pro tip: Wait at least 3 months before upgrading major versions. Let others find the bugs first. Remember the left-pad disaster? Or the Log4j panic? Early adopters in enterprise systems are just unpaid beta testers.
Who Actually Uses This Thing
Big companies like Netflix, Uber, and Airbnb use Spark in production, which means it's been battle-tested at scale. NASA JPL processes space mission data with it, so it probably won't crash your e-commerce analytics.
According to NVIDIA, tens of thousands of companies worldwide use Spark - though half of them are probably still stuck on version 2.4 because upgrading is a nightmare. Translation: it's popular enough that finding engineers who know it isn't impossible, and Stack Overflow has answers for most of your problems.
The Real Talk on Production Deployments
Spark works well for ETL pipelines, data science workflows, and analytics where you need to process more data than fits on one machine. But don't expect it to be simple - you'll spend significant time on:
- Memory tuning and JVM garbage collection optimization
- Dealing with data skew that makes some tasks take 10x longer than others
- Cluster configuration and resource management
- Debugging jobs that mysteriously fail after running for hours

Bottom line: Spark still beats the alternatives, despite all the pain points. But you need to know when it makes sense compared to alternatives, and when you should run screaming toward something else entirely.