
Still here after that warning? Good. Look, this stack became popular because it actually works at scale. Lambda functions shit the bed after 100K events, and simple queues are great until you need to transform the data or search through it later.
The Three-Headed Monster You're About to Build
You've got three moving parts that all hate each other: Kafka (the data firehose), Spark (the processing engine that eats RAM), and Elasticsearch (the search engine that corrupts indices for fun).
This architecture is awesome if you have Netflix's budget. For everyone else, expect your AWS bills to get ugly fast - like, maybe $8k monthly, could be way higher depending on your data volume. Costs have been climbing since 2023 with all the instance price increases.
I learned this the hard way when our "simple" event tracking system went from around $2k to like $12k+ monthly - maybe higher, I stopped looking at the exact number after it hit five figures. Turns out nobody mentioned that Elasticsearch replicates everything 3 times by default. Fun discovery.
This shit gets expensive. Your typical production setup needs beefy instances across all three services, plus storage, plus network bandwidth. Start budgeting at least $8k monthly, probably more once you factor in monitoring, backups, and the extra capacity you'll need when things go sideways.

What Each Component Actually Does
Kafka: The Data Firehose
Kafka ingests data and keeps it around for a while. The partition-based architecture sounds great until you realize wrong partitioning will bottleneck your entire pipeline. Pro tip: start with more partitions than you think you need - you can't increase them easily later without major pain.
The Kafka cluster architecture distributes data across multiple brokers for fault tolerance. Each topic partition gets replicated across configured brokers, but replication complexity can bite you in production.
Version hell warning: Kafka 3.6.1 works great, but then 3.6.2 came out and broke a bunch of stuff - consumer group rebalancing got weird and offset management had issues. Kafka 4.x series (current as of Sep 2025) has breaking changes in the admin client API and consumer group management. Don't ask why, nobody knows. Pin every single version in your build files or you'll spend days debugging ClassNotFoundException errors when Gradle decides to "helpfully" upgrade dependencies.
The new KRaft mode (no more ZooKeeper dependency) in Kafka 4.x is supposedly stable but requires different monitoring and operational procedures. Check the Kafka compatibility matrix religiously before upgrading anything.
Spark: The RAM Gobbler
Spark Structured Streaming processes your data in "micro-batches" which is fancy talk for "we'll batch it up and pretend it's real-time." The docs claim sub-second latency. In reality, expect 2-5 seconds once you add actual business logic.

The micro-batch processing model achieves 100ms latency at best, but continuous processing can hit 1ms if you're willing to sacrifice fault tolerance. Databricks recommends micro-batching for most use cases due to exactly-once guarantees.
Spark's memory management will drive you insane. Set spark.executor.memory=8g and it'll use 12GB. The checkpointing mechanism that "enables recovery from failures" fails randomly and corrupts your state. Always backup to multiple locations. Read Spark performance tuning guide before you lose your sanity.
Elasticsearch: The Index Destroyer
Elasticsearch will eat all your RAM and ask for more. The distributed architecture supports "petabyte-scale search" if you have petabyte-scale hardware budgets.
The cluster, nodes, and shards architecture distributes data across primary and replica shards, but shard allocation can become a nightmare at scale. Too many shards destroy performance, too few create hotspots.
Real talk: Elasticsearch decides to go read-only when disk hits 85% full. This happens on weekends when you're not watching. Your pipeline stops, data backs up in Kafka, and you get angry calls from product managers. Monitor cluster health religiously or suffer the consequences.
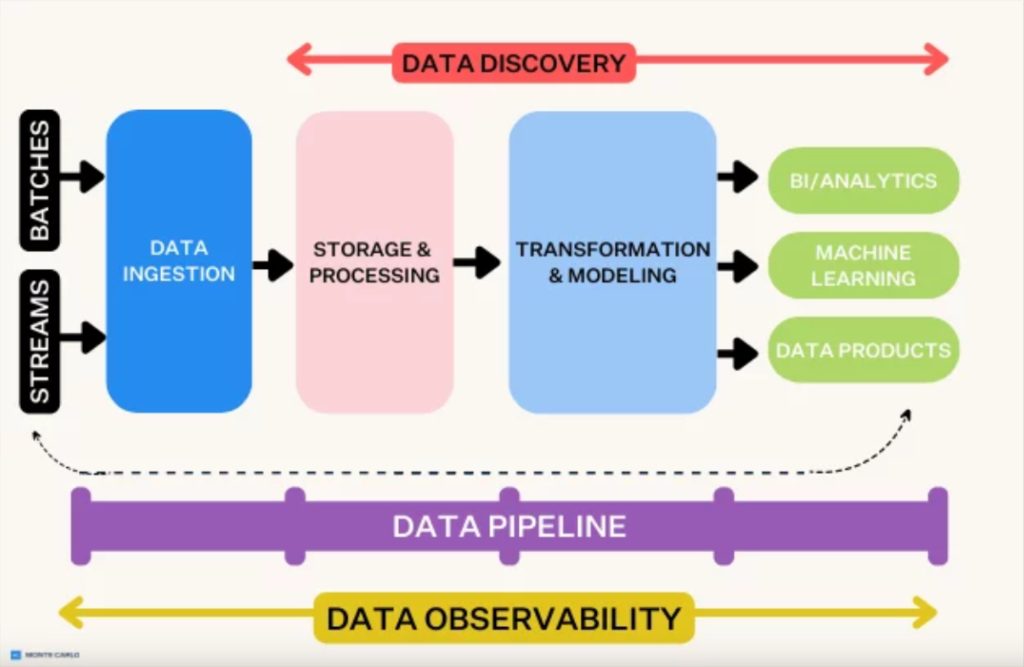
The Data Flow (When It Works)
- Applications → Push events to Kafka topics (works great until network blips)
- Kafka Brokers → Store and replicate data (replication factor saves you from disk failures)
- Spark Jobs → Read from Kafka using Kafka-Spark connector (breaks every upgrade)
- Data Processing → Transform and enrich (where 90% of your bugs live)
- Elasticsearch → Index for search (randomly stops working and nobody knows why)
- Kibana → Pretty dashboards (when Elasticsearch cooperates)
What the Docs Don't Tell You
The marketing bullshit about "100x faster than batch" is assuming your data is pristine, your network never hiccups, and AWS gives you unlimited resources for free. Real world? Your data is garbage, your network drops packets, and your AWS bill makes CFOs cry.
Real performance depends on:
- How much crap is in your data (answer: a lot)
- Network latency between your components (AWS AZs add 1-3ms)
- Whether Elasticsearch feels like working today (coin flip - check indexing performance issues)
- Phase of the moon and your proximity to a data center
Plan to hire someone whose job is just keeping this shit running. Kafka rebalances for no reason, Spark eats all your RAM, ES corrupts indices on Tuesdays. Budget for at least one full-time babysitter who actually knows what they're doing.
Look into production monitoring strategies before you deploy this monster. The stream processing challenges are real and the learning curve will kick your ass.
