Yahoo had a Kafka cluster that kept shitting itself. 100 billion messages per day across their ad platform, and every time they needed to scale storage, they had to rebalance the entire cluster. Weekend deployments became weekend disasters.
So they built Pulsar in 2013, open-sourced it in 2016, and solved the fundamental problem that makes Kafka operationally painful: compute and storage are glued together.
The Architecture That Actually Matters
![]()
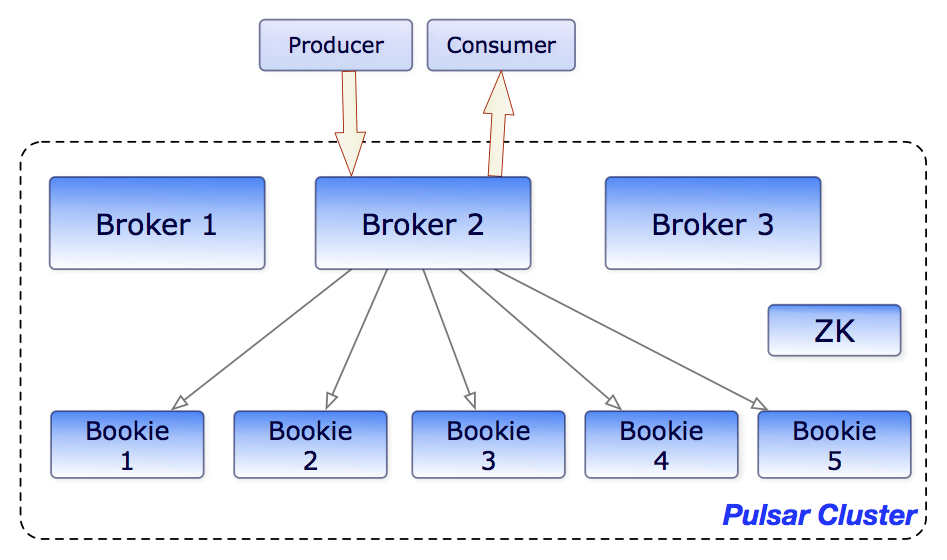
Here's the thing that makes Pulsar different: brokers don't store data. BookKeeper handles the storage, brokers just route messages. When you need more storage, you add BookKeeper nodes. When you need more throughput, you add brokers. No rebalancing, no weekend outages, no praying to the distributed systems gods.
I learned this the hard way when our Kafka cluster ate shit during Black Friday 2021. We had 12 brokers at 85% disk usage, and adding storage meant migrating partitions. That took 18 hours and cost us about $200k in lost orders.
With Pulsar, adding storage is literally: docker run apache/bookkeeper and the cluster picks it up automatically. Same with brokers. It's almost too easy.
Multi-Tenancy That Doesn't Suck
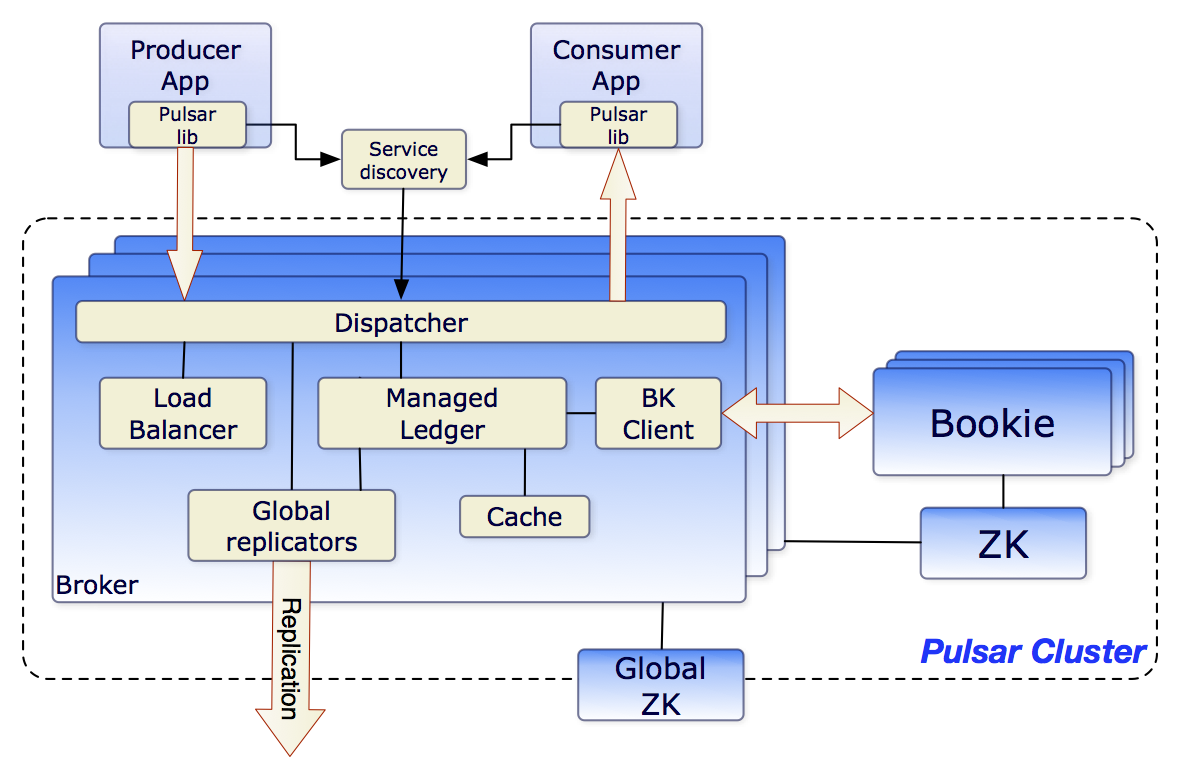
Most platforms added multi-tenancy as an afterthought. Pulsar built it from day one, which means you can actually use it without hacky workarounds.
Real example from production: we run dev, staging, and prod workloads on the same cluster. Different teams, different access controls, different resource limits. In Kafka, this would be three separate clusters and a DevOps nightmare.
The tenant/namespace model is simple:
persistent://tenant/namespace/topic- Each tenant gets its own auth, quotas, and policies
- Namespaces isolate environments within tenants
- One cluster, one operational headache instead of dozens
The Stuff That Actually Works (Pulsar 4.1, Just Released)
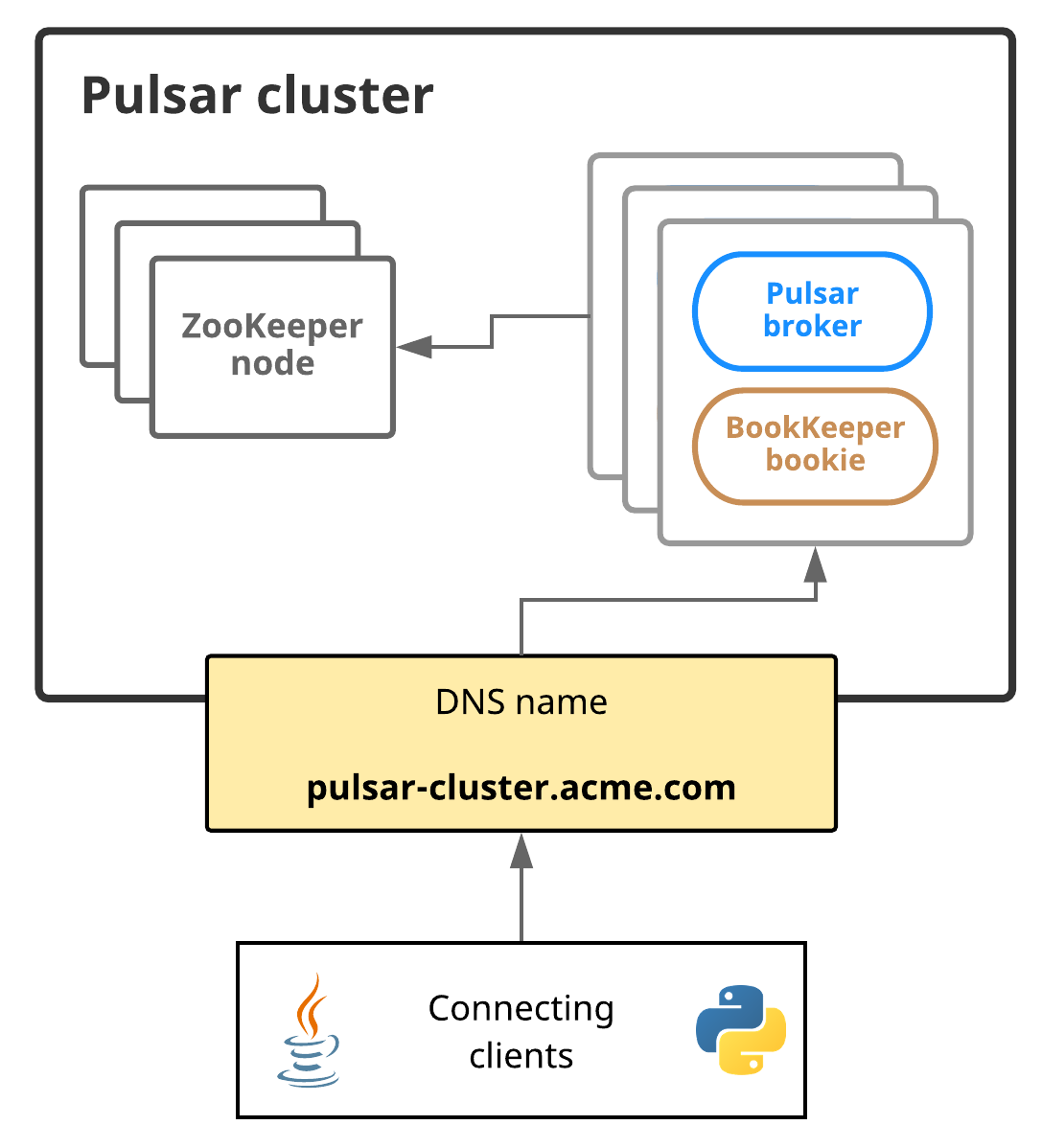
Major update: Pulsar 4.1.0 just dropped yesterday (September 8, 2025) as the latest stable release, building on the solid 4.0 LTS foundation from October 2024. Here's what actually works now:
Key_Shared subscriptions finally work right. Before 4.0, ordering guarantees were more like "ordering suggestions." Now they maintain order per key while scaling consumers horizontally.
Java 21 support and Alpine images. The old images were security nightmare fuel. New ones have zero CVEs and boot 40% faster.
Built-in schema registry. No more Confluent licensing bullshit for basic schema validation.
Connection pooling that doesn't leak. The old connection leak issues finally got fixed - connections actually close when they should.
Where It Actually Gets Used
Verizon pushes 4 billion events daily through Pulsar for their 5G network analytics. Splunk uses it for log ingestion at scales that would melt Kafka clusters.
But here's the reality check: most teams don't need Pulsar. If you're pushing less than 100k messages/sec and don't need multi-tenancy or geo-replication, Kafka is probably fine. Pulsar shines when you need the stuff Kafka can't do, but you pay for it with operational complexity that'll eat your weekends if you don't know what you're doing.
For deep-dive comparisons, check out Confluent's Kafka vs Pulsar analysis, AutoMQ's technical comparison, and this 2024 performance analysis. The StreamNative architecture guide explains why the separation of storage and compute matters, while RisingWave's comprehensive guide covers deployment best practices in detail.