Vector databases are hot as hell right now, but most enterprise implementations are garbage. Teams nail the demo then face-plant when they hit real operational requirements. Scaling vector databases for enterprise demands requires understanding operational complexity that most vector database tutorials completely ignore.
Why Enterprise Vector Deployments Actually Fail
Here's what the success stories don't tell you: most enterprise vector database projects fail not during the POC phase, but 6-12 months later when they hit production reality.
The typical failure pattern looks like this: a team builds an impressive demo with 100,000 documents using Chroma or Pinecone, gets executive approval, then discovers their 50 million document corpus requires something like 400GB of RAM, costs 7-8K monthly in Pinecone's enterprise pricing, and violates three different compliance frameworks. Most teams rely on vector similarity search algorithms without understanding the operational complexity of production deployments.
I've seen legal teams kill vector projects over GDPR concerns - turns out OpenAI embeddings from customer PII violates pretty much every data governance policy ever written. Expensive lesson.

The Infrastructure Reality Check
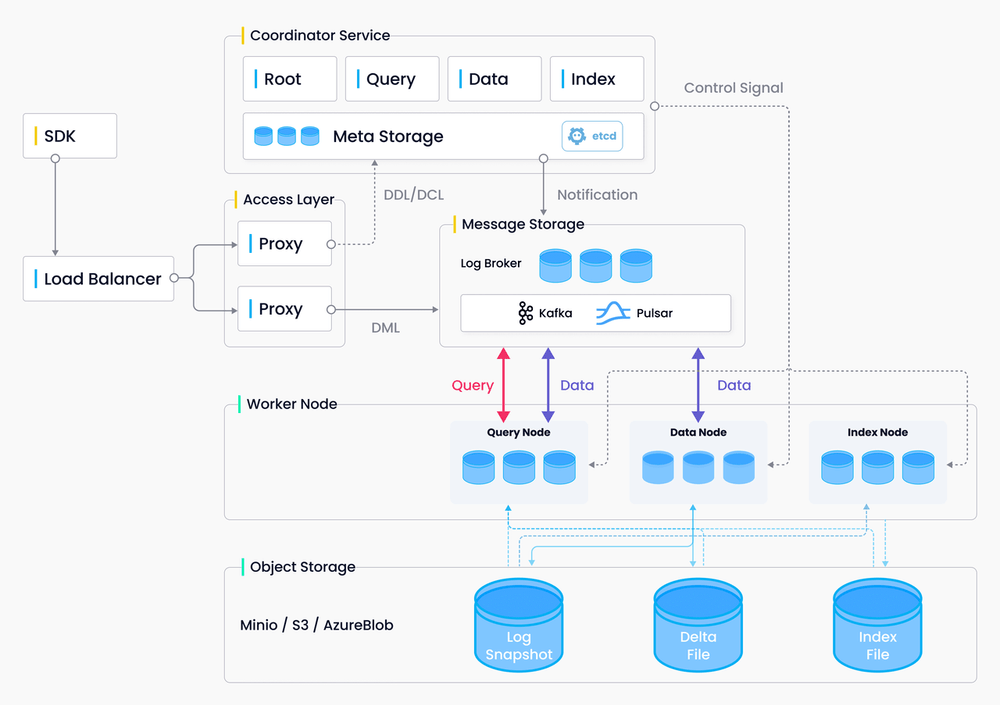
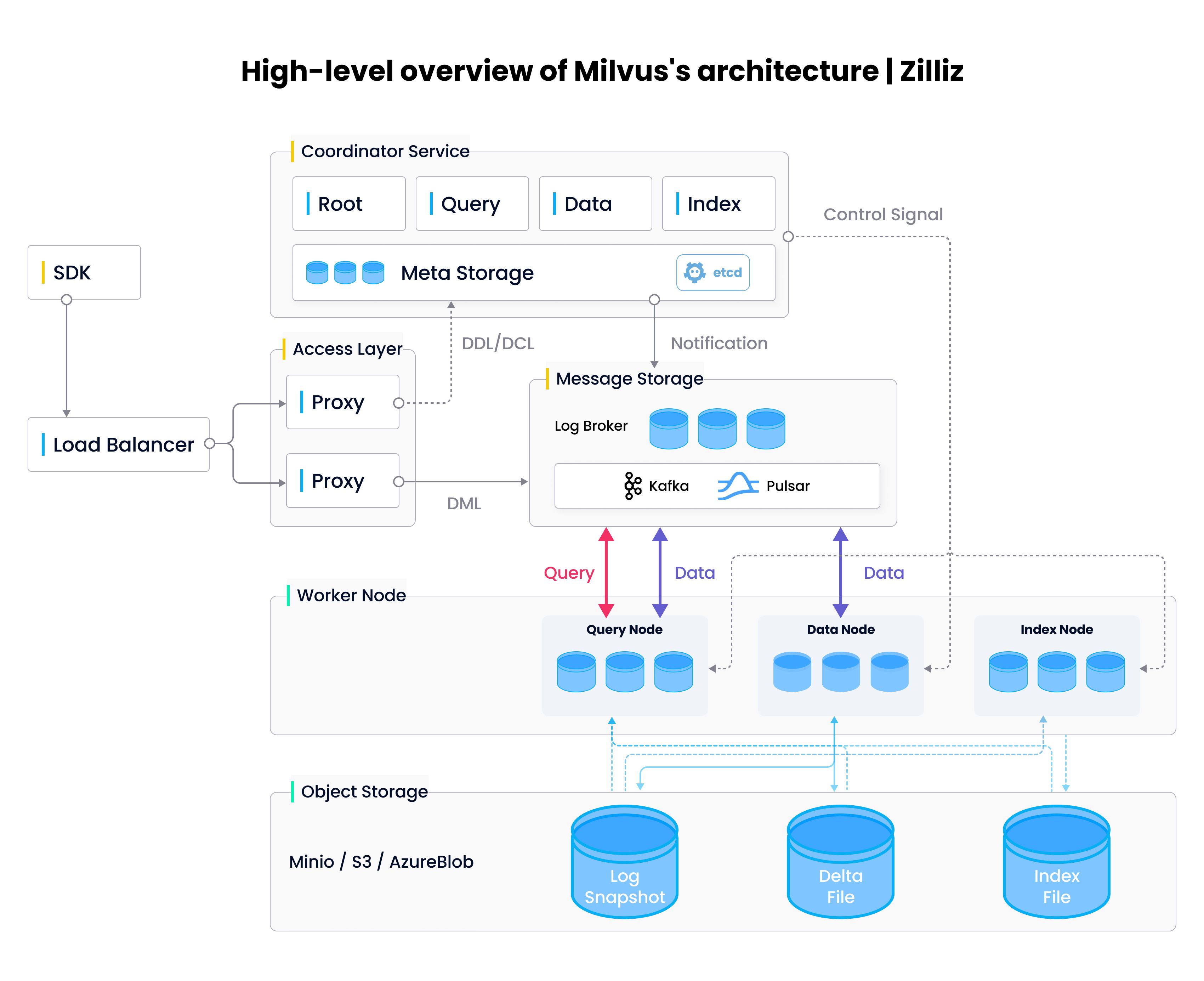
Memory requirements will absolutely fuck you. Microsoft's SQL Server 2025 now includes native vector support specifically because they got tired of customers complaining about running separate systems that eat 500GB of RAM. The DiskANN integration lets you do vector search without keeping everything in memory, which is the only reason this approach works.
For a 10 million document enterprise corpus using 1536-dimensional embeddings:
- Raw storage: 60GB for vectors alone
- HNSW index: Additional 120-300GB in memory for decent query performance
- Replication: 3x multiplier for high availability across regions
- Staging/dev environments: Another 2x multiplier for realistic testing
That's potentially 1.2TB of RAM across your infrastructure before you handle a single production query. AWS costs for this start around 3K/month in compute alone, but that's before they hit you with bandwidth charges, storage fees, and all the other bullshit that nobody mentions in the sales call. Vector database cost optimization becomes critical as you scale beyond prototype deployments.
![]()
The Compliance Nightmare
Costs are just the start. Now let's talk compliance hell. GDPR's "right to erasure" means you need to delete specific user data from vector embeddings, but how the fuck do you remove individual embeddings from a 50-million vector HNSW index without rebuilding the entire thing?
SOC 2 Type II compliance requires audit trails for all data access. Pinecone's enterprise tier provides this, but pgvector requires you to implement access logging yourself. Many teams discover these requirements after months of building on non-compliant platforms.
Data residency requirements are another killer. European enterprises often need vector data stored in EU regions, but some managed services don't offer EU-specific deployments or have complex data transfer policies that legal teams reject. Understanding GDPR implications for vector databases becomes essential for European deployments.
Integration With Existing Systems
The biggest enterprise challenge isn't choosing a vector database - it's integrating it with decades of legacy infrastructure. Your vector search needs to work with:
- Active Directory for authentication and authorization
- Kafka or similar for real-time data streaming
- Data warehouses like Snowflake or Redshift for analytics
- ETL pipelines for data processing and embedding generation
- Monitoring systems like DataDog or Splunk for observability
Weaviate's built-in authentication integrates well with enterprise identity providers, but many teams end up building custom API gateways to handle complex authorization rules like "only show vectors derived from documents this user has permission to access."
The Disaster Recovery Question Nobody Asks
When your vector database goes down at 2 AM, how quickly can you restore service? Traditional databases have well-understood backup and recovery procedures, but vector databases introduce new complexities:
Index rebuilding time can be hours or days for large corpora. Rebuilding a 30 million article index? That's a weekend-long project if you're lucky. Content recommendations go dark until it's done.
Embedding consistency during recovery is another issue. If you restore vector data but not the source documents, or vice versa, your search results become inconsistent. Some teams maintain synchronized backups, others rebuild embeddings from source during recovery.
Cross-region replication of vector indexes is often more complex than relational data. Qdrant's distributed mode helps, but introduces CAP theorem trade-offs that need careful consideration for enterprise availability requirements.
The reality is that enterprise vector database deployment in 2025 isn't a technical challenge - it's an operational, compliance, and integration challenge that requires the same rigor as deploying any other business-critical system.