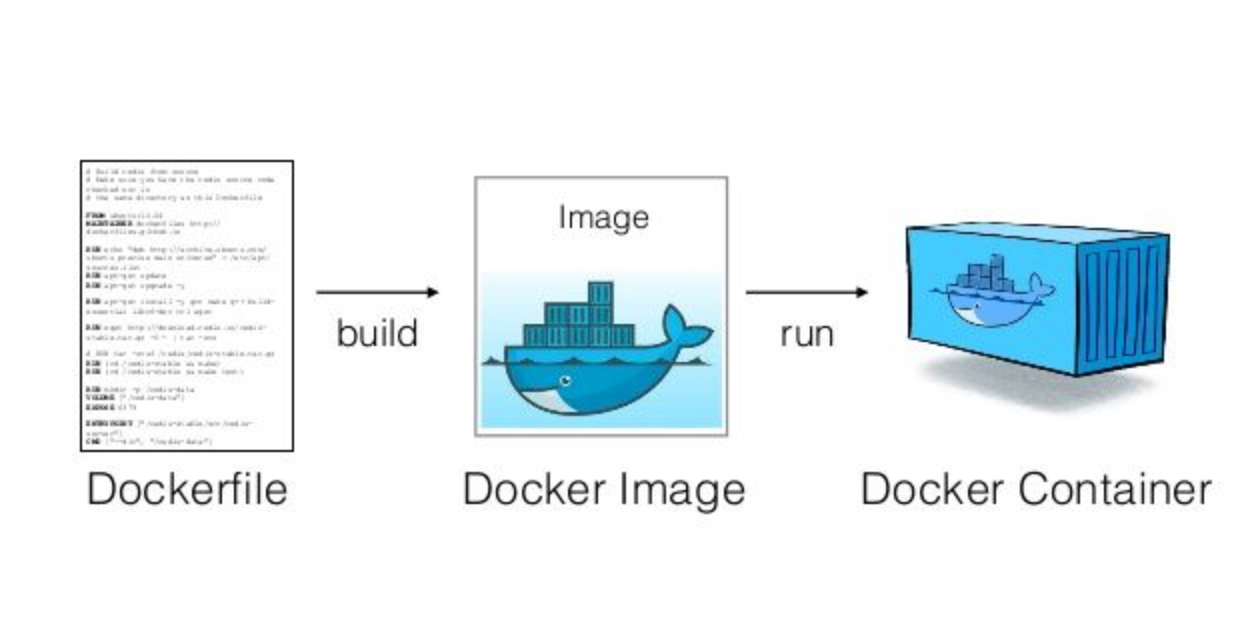
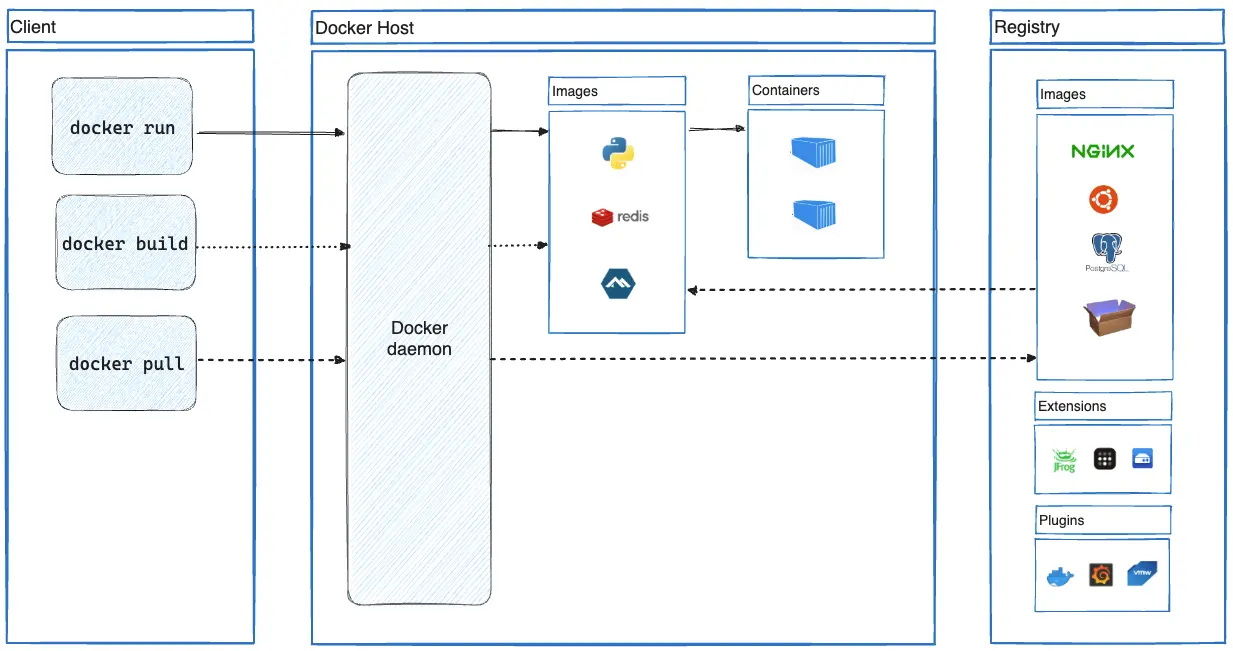
Look, deploying LangChain with Hugging Face models in production isn't the smooth ride the documentation promises. After burning through something like 8 grand in our first month, here's what we learned the hard way.
The Three Patterns That Actually Work
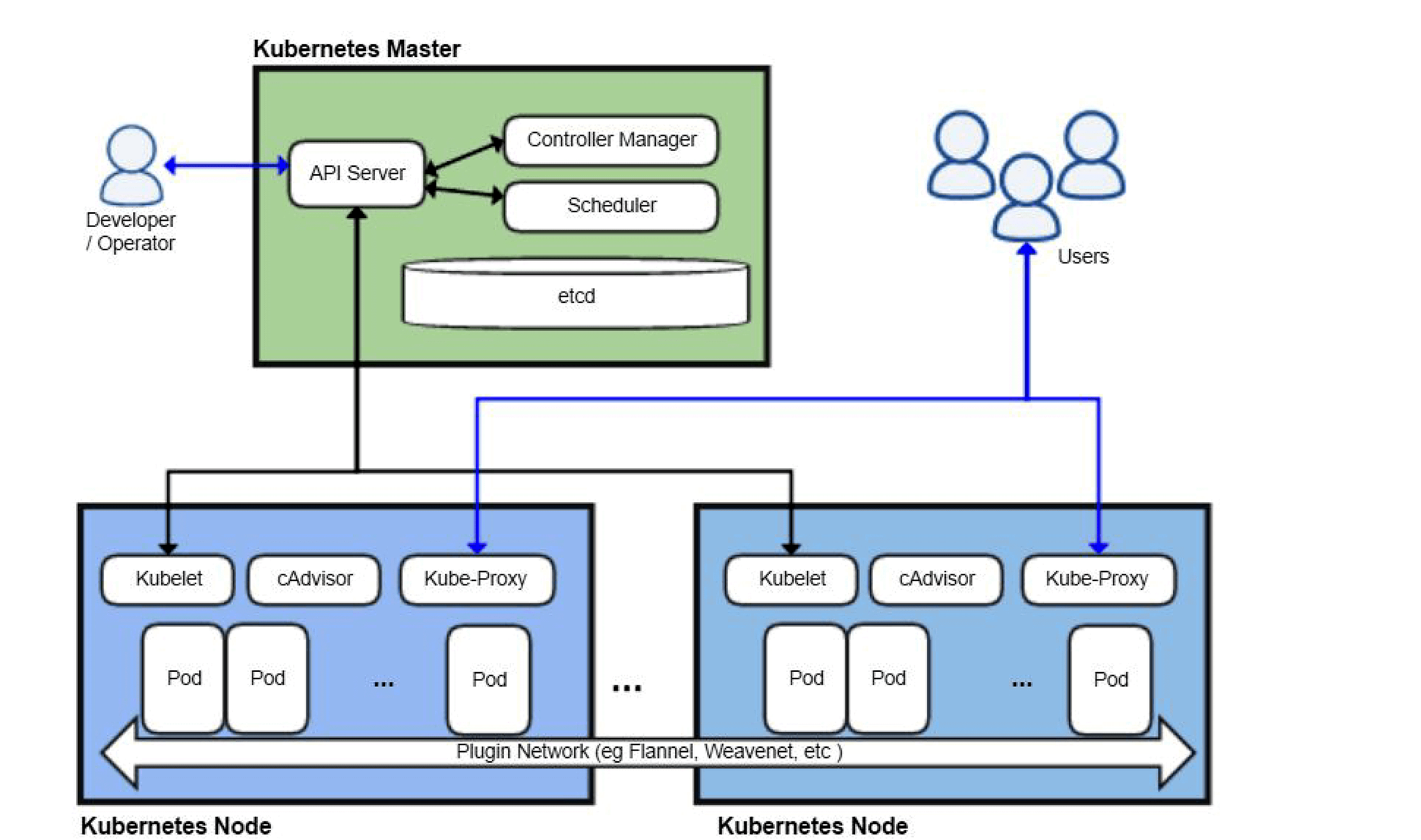
Forget the perfect marketing diagrams. These are the only three deployment patterns that survive contact with real traffic:
1. Hugging Face Endpoints (The "Expensive But Easy" Route)
Hugging Face Inference Endpoints are great for demos, but expensive for production. That "pay-per-request" pricing adds up fast - we were at around $2,400/month for moderate traffic before switching. But here's the thing: they actually work reliably. No weekend alerts about OOMKilled pods, no GPU scheduling failures. Just expensive.
The langchain-huggingface integration is mostly solid, but version conflicts happen regularly. Pin to whatever versions actually work in your environment or get fucked by breaking changes: langchain==0.2.x and huggingface-hub==0.24.x worked for us.
2. Self-Hosted Kubernetes (The "Control Freak" Route)
Only choose this if you have a dedicated platform team. Otherwise you'll spend more time fixing Kubernetes networking issues than building features.
We learned this when our GPU scheduling randomly stopped working on EKS 1.24. Turns out the NVIDIA device plugin had memory leaks. Got woken up at 2am because all our inference pods were stuck in Pending state. Solution? Restart the daemonset weekly with a cronjob. Glamorous, right?
Docker builds take forever because downloading 8GB models is slow as hell. Use multi-stage builds and cache the model downloads, or your CI will time out every damn time.
3. Serverless (The "Scale-to-Zero Dream")
Google Cloud Run with GPU support sounds awesome until you realize cold starts take 2-3 minutes for large models. Your users will think the app is broken while the container spins up.
AWS Lambda with containers? Forget about it for anything larger than a 7B model. The 15-minute timeout will kill you during model loading.
What Actually Matters for Model Serving


Text Generation Inference (TGI) is the only model server that doesn't suck. Here's why:
- Dynamic batching is the difference between serving 10 requests/minute vs 100. Everything else is marketing fluff.
- Quantization actually works now. GPTQ can cut memory usage in half without destroying quality.
- Tensor parallelism lets you split large models across multiple GPUs, but watch out - network latency between GPUs kills performance if you're not on the same node.
The memory requirements in the docs are complete bullshit. Budget 16GB or watch your pods die - we OOM-killed production three times before learning this. GPU memory profiling is your friend.
Scaling Reality vs Documentation
Auto-scaling sounds great in theory. In practice, Horizontal Pod Autoscaler takes 8 minutes to spin up new instances during traffic spikes. Your queue backs up, users get 504 Gateway Timeout errors, and your phone starts buzzing at 3am.
The real solution? Over-provision slightly and use vertical scaling for predictable load patterns. It costs more but your app actually works.
Memory leaks are real in long-running model servers. We restart our TGI containers every 6 hours via cronjob. Not elegant, but it prevents the 3am PagerDuty alerts about response times hitting 30 seconds.
For more deployment patterns, check out MLOps best practices and production ML system design. The CUDA toolkit documentation is also essential for GPU troubleshooting, and PyTorch performance tuning covers memory optimization techniques that actually work. Don't forget the Kubernetes best practices guide - it'll save you from common pitfalls.