You know that moment when your "smart" FAISS implementation starts throwing RuntimeError: Invalid argument for no fucking reason? Or when your pgvector extension makes PostgreSQL eat 32GB of RAM and still takes 4 seconds per query?
That's why Milvus exists. It's a vector database that doesn't randomly shit the bed when you scale past your laptop. I've been running it for 8 months and it hasn't woken me up with production alerts. Had this weird memory issue one night - I think it was like 2am? Maybe 3am? Spent fucking hours tracking it down, turned out to be some cache that wasn't clearing. Classic. That was my fault though, not Milvus being shitty.
What It Actually Does
Vector Storage That Doesn't Suck: Remember the last time you tried stuffing 768-dimensional embeddings into Redis and got OOM command not allowed when used memory > 'maxmemory'? Or when you discovered that PostgreSQL's vector similarity search is basically a full table scan in disguise?
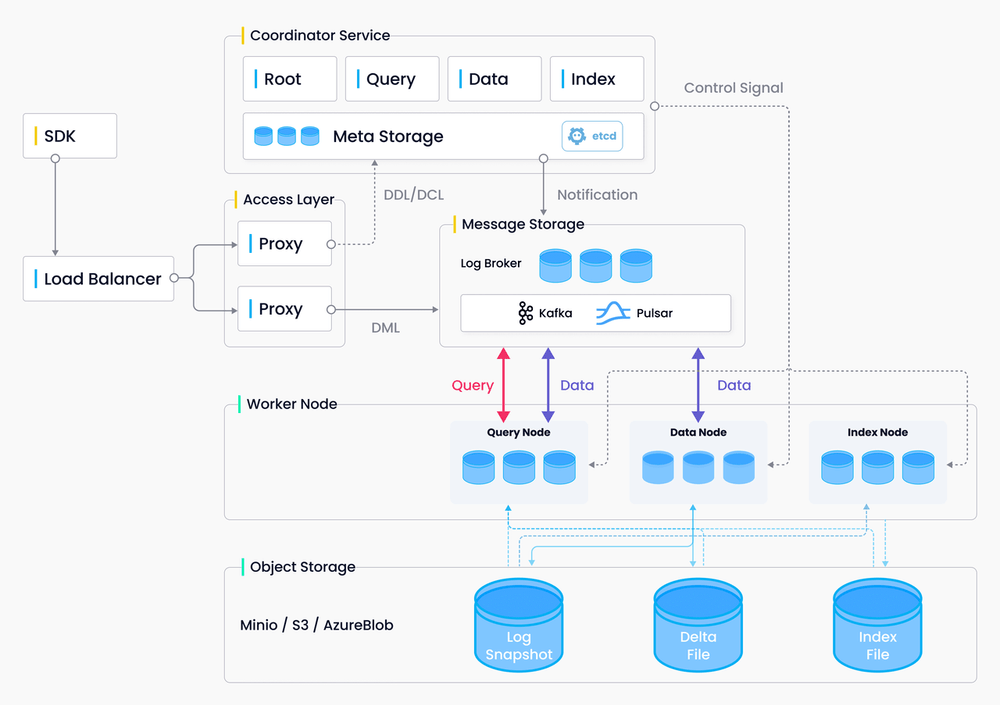
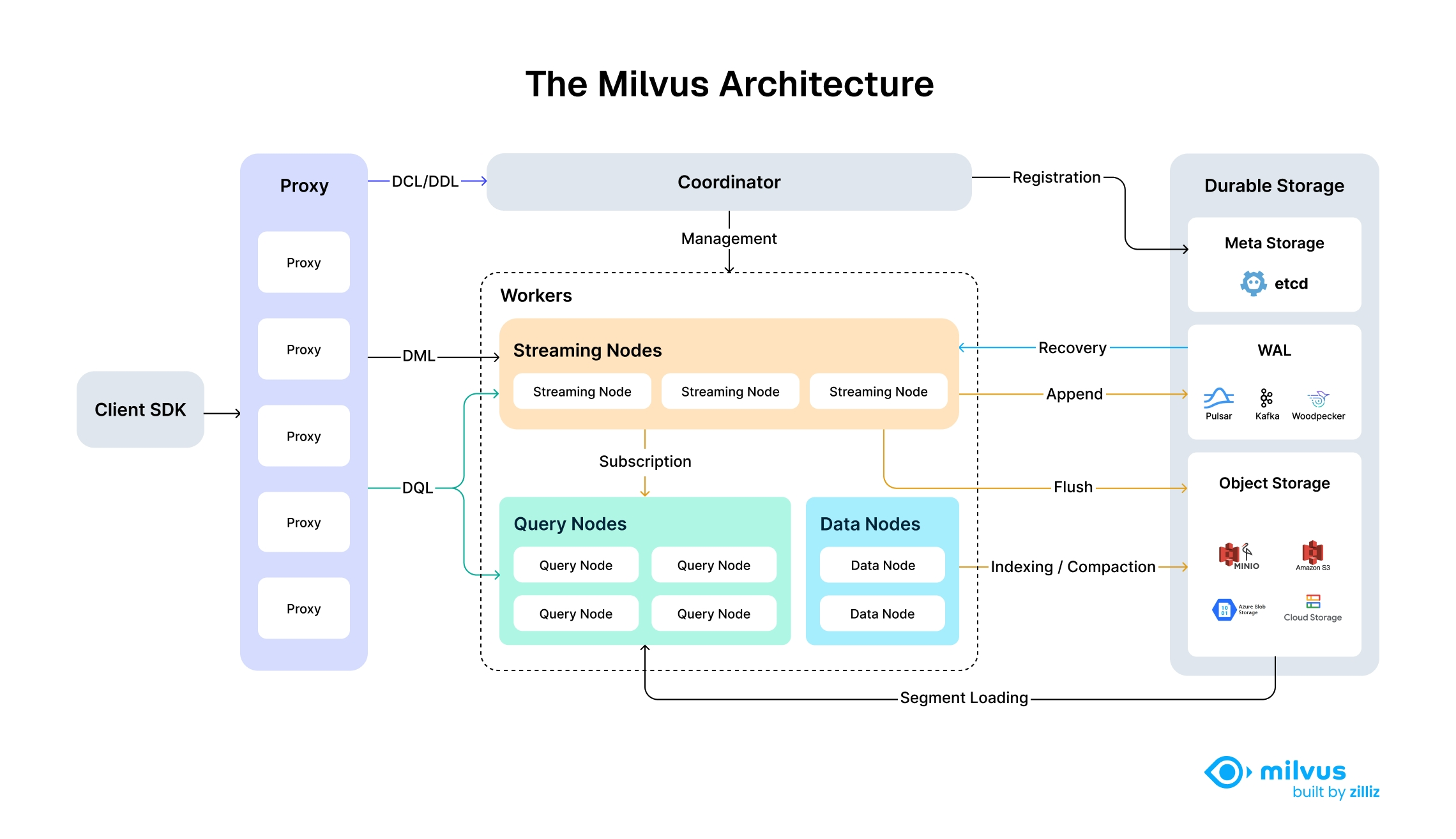
Milvus actually handles this shit. You throw your embeddings at it - OpenAI's `text-embedding-3-large`, some random Hugging Face sentence transformer, whatever - and it doesn't crash. Dense, sparse, binary vectors, it eats them all without you writing JSON serialization hacks. The official documentation covers all the supported vector types and their technical specifications.
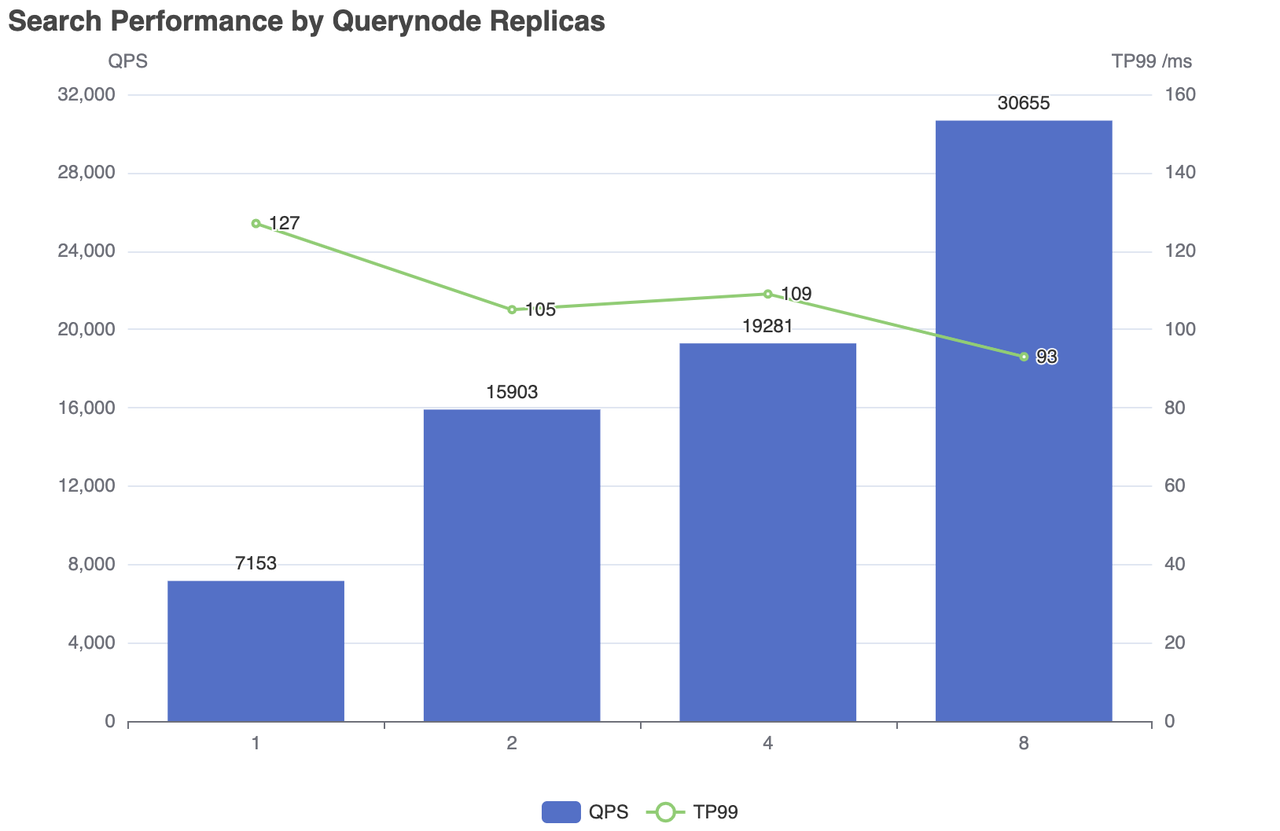
Search That's Actually Fast: On my production workload - 50M product embeddings from some e-commerce site - Milvus usually hits 30-80ms, though I've seen it spike to 200ms when things get weird. Same hardware with Elasticsearch? Fuck that, 200ms+ and sometimes just straight up timeouts when the query load spikes. You can see the official benchmarks and performance comparisons for detailed numbers.
The hybrid search in 2.6 is legit useful. You can do vector similarity AND keyword matching in one query instead of the typical "search two systems, merge results in application code" bullshit. Check out the hybrid search tutorial for implementation details.
Deployment Options That Don't Suck:
- Milvus Lite:
pip install milvus-liteand you're done. Runs in-process for development. Perfect for testing your embedding pipeline before deploying to production - Standalone: Single Docker container. I run this on a 32GB server and it handles 10M vectors without breaking a sweat
- Distributed: When you need to scale past one machine. Uses Kubernetes, which means it's complex but at least it's reliably complex
- Zilliz Cloud: Managed service. More expensive but you don't get paged at 3am when etcd shits itself
What's Actually New in 2.6
The latest stable release has some shit that actually matters:
Memory Compression That Works: RaBitQ quantization cut my memory usage from 480GB to about 140GB on a 100M vector dataset. Quality loss is minimal for most use cases - recall dropped from 0.98 to 0.94, which is fine for recommendations but might suck for exact matching.
No More Kafka Bullshit: They built Woodpecker WAL to replace Kafka/Pulsar dependencies. One less distributed system to babysit. Setup time went from "spend 3 hours configuring Kafka" to "just run it."
Multi-tenant Support: You can now run thousands of collections without the cluster imploding. Before 2.6, I hit performance walls around 10K collections. Now it handles way more, though I haven't pushed it to the claimed limits.
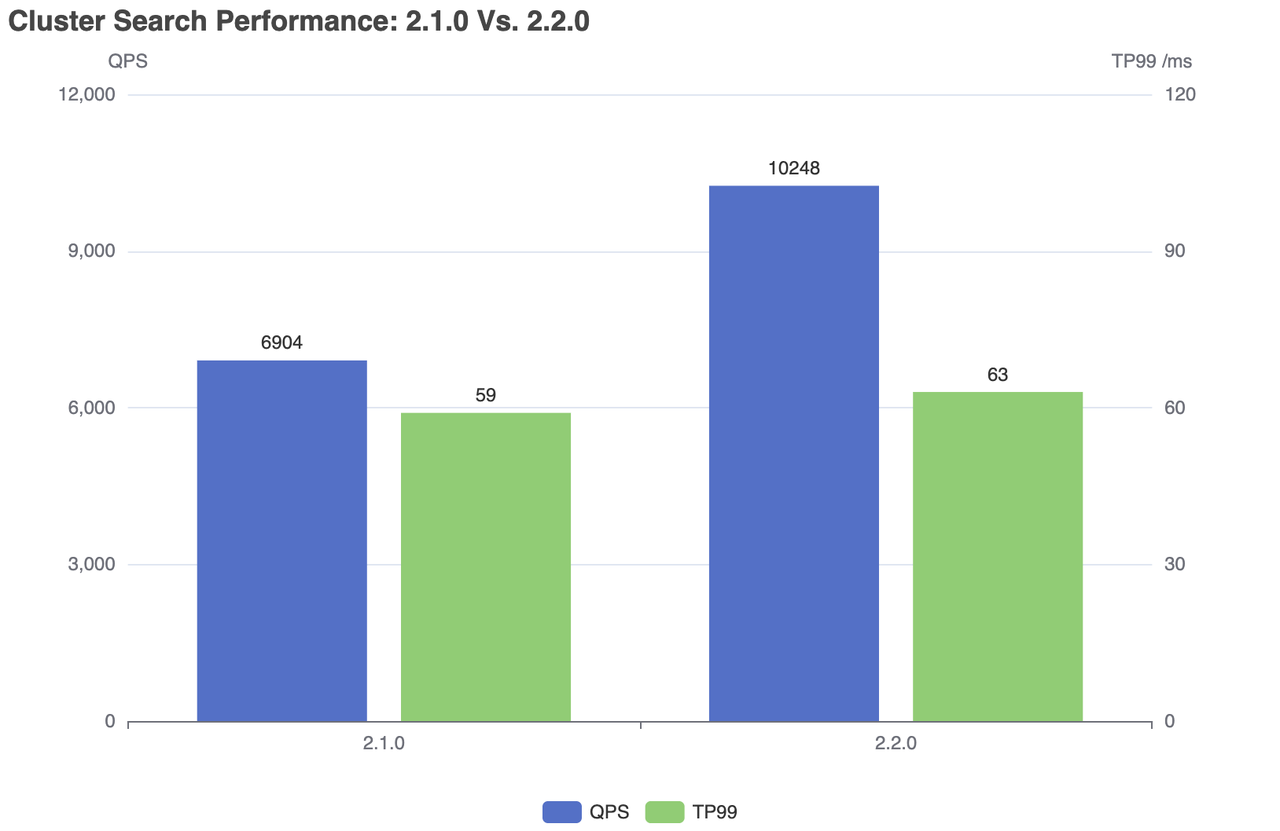
Real World Numbers: Migrated from Pinecone to self-hosted Milvus last year around October when our costs were getting stupid. AWS bill went from like $2,800/month down to $1,100/month - saved my ass in budget meetings. Query latency went from 180ms avg to... I think it was 65ms? Maybe 70ms? Either way, way fucking better. Your mileage will vary depending on your setup, but the migration tools actually work, which shocked me. There are detailed cost comparisons and production case studies showing similar results across different companies.