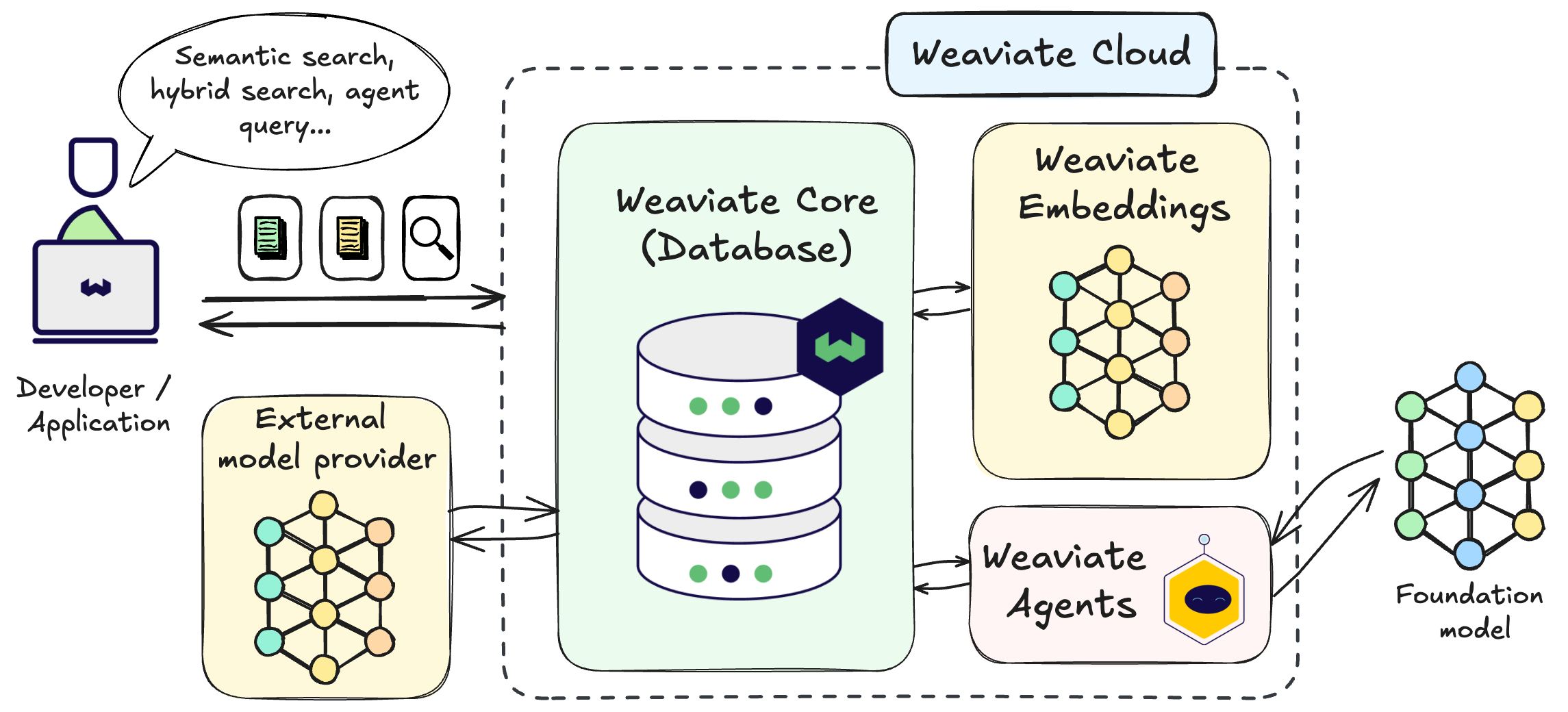
Weaviate is an open-source vector database that solves the "where do I put my embeddings?" problem. Released in 2019 and built in Go (not Python, thank god), it stores both your data and vector embeddings so you can search by meaning instead of playing keyword roulette.
If you've ever tried building RAG systems with separate vector storage and metadata filtering, you know the pain - queries that take forever, join operations from hell, and race conditions that make you question your career choices. Weaviate eliminates this by combining semantic search with traditional filtering in a single atomic query.
Why Vector Databases Exist (Spoiler: SQL Sucks at Similarity)
We tried building our own vector search with PostgreSQL and pgvector. Three weeks in, our queries were timing out, our RAM usage hit the ceiling, and we realized we'd basically reinvented the wheel... poorly.
Traditional SQL databases are great for exact matches but terrible at "find me things similar to this." Weaviate bridges this gap by storing both your objects and their vector representations, then letting you search by meaning rather than exact keywords. The result? Searches that actually understand what users want.
Latest version as of September 2025 is Weaviate v1.26.x, with 1.33.0-rc.0 available for those who like living dangerously. Fair warning: v1.25.2 had a nasty bug where HNSW rebuilds would silently corrupt indexes - learned that one the hard way during a 3am production incident. The collection aliases feature is a lifesaver for migrations - no more "delete everything and start over" moments. Rotational quantization cuts memory usage by 75%, which your AWS bill will appreciate. The HNSW optimizations mean fewer "why is my query taking 30 seconds?" moments.
It supports 50+ embedding models from OpenAI, Cohere, HuggingFace, and Google. Pro tip: Set your OpenAI rate limits conservatively or prepare for 429 errors that'll tank your app.
Core Architecture and Performance
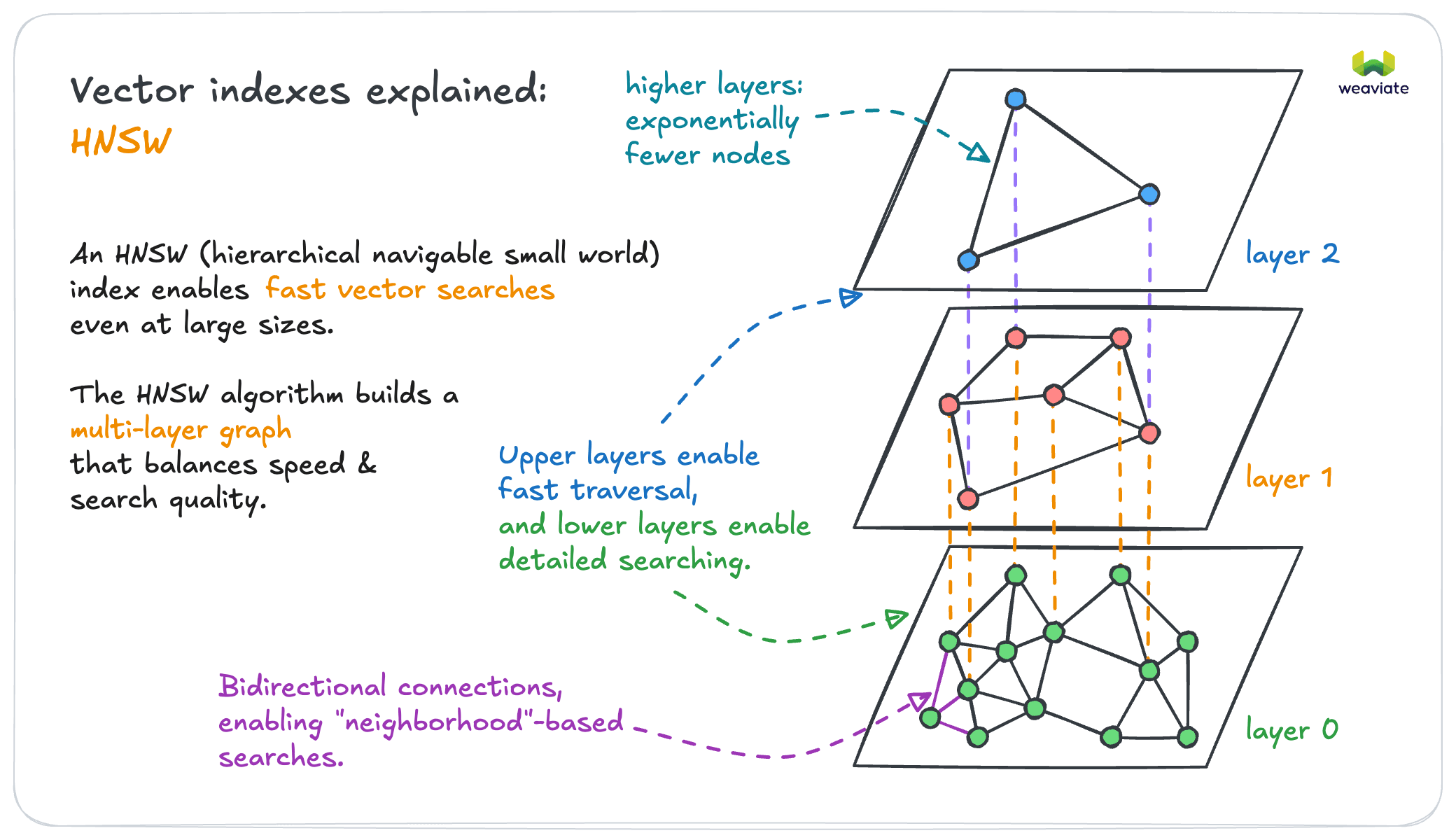
Weaviate uses the HNSW algorithm for indexing, which is fancy talk for "finds similar stuff really fast." Works great until you misconfigure the parameters and have to rebuild everything.
Response times hover around 100-200ms on a properly sized setup. The marketing docs say "sub-millisecond" but that's with perfect conditions and optimized data that doesn't exist in production. In the real world, expect 50-200ms for typical queries, which is still decent but don't believe the hype.
Getting the HNSW parameters right is more art than science. Too aggressive and your index takes forever to build. Too conservative and queries are slow. The GitHub discussions have saved my ass multiple times - search for 'HNSW parameters' and you'll find gold.
You get multiple search types in one query:
- Vector search for semantic similarity (the main event)
- Keyword search with BM25F for exact matches (surprisingly useful)
- Hybrid search that combines both (the secret sauce)
- Image search for visual similarity (when it works)
- Generative search for RAG apps (integrates with LLMs)
Enterprise-Ready Features
Weaviate will eat your RAM for breakfast - plan accordingly. Multi-tenancy looks great until you have 1000+ tenants, then everything slows down. Horizontal scaling works but the setup is more complex than "just add nodes."
We learned the hard way about memory usage during our first production deployment. A single 1536-dimension vector collection with 100k documents ate through 32GB of RAM stupid fast, crashed with OOMKilled errors that gave zero useful information. Vector dimension mismatches throw errors like "incompatible tensor shapes" with no context about what broke where. Spent 6 hours debugging what turned out to be a single document with wrong embedding dimensions because the error message was useless as tits on a bull.
The solution that actually worked? Start with ridiculously oversized instances (we went from t3.large to r6i.2xlarge), monitor memory usage obsessively, then scale down once you understand your actual footprint. Scaling up during an outage is not fun - takes 15 minutes minimum while your app returns 502s and your boss asks why monitoring didn't catch it.
RBAC is solid once you survive the setup documentation, which assumes you're simultaneously an expert in Kubernetes, OAuth2, and Weaviate's specific auth flow. Version upgrades have a charming habit of breaking your auth configuration in ways that only surface at 3am during production queries.
Enterprise compliance is real though - SOC 2 Type II, HIPAA-ready deployments, and the security audit checkboxes that keep procurement happy. Azure and GCP support exist but feel like afterthoughts compared to the AWS integration.
