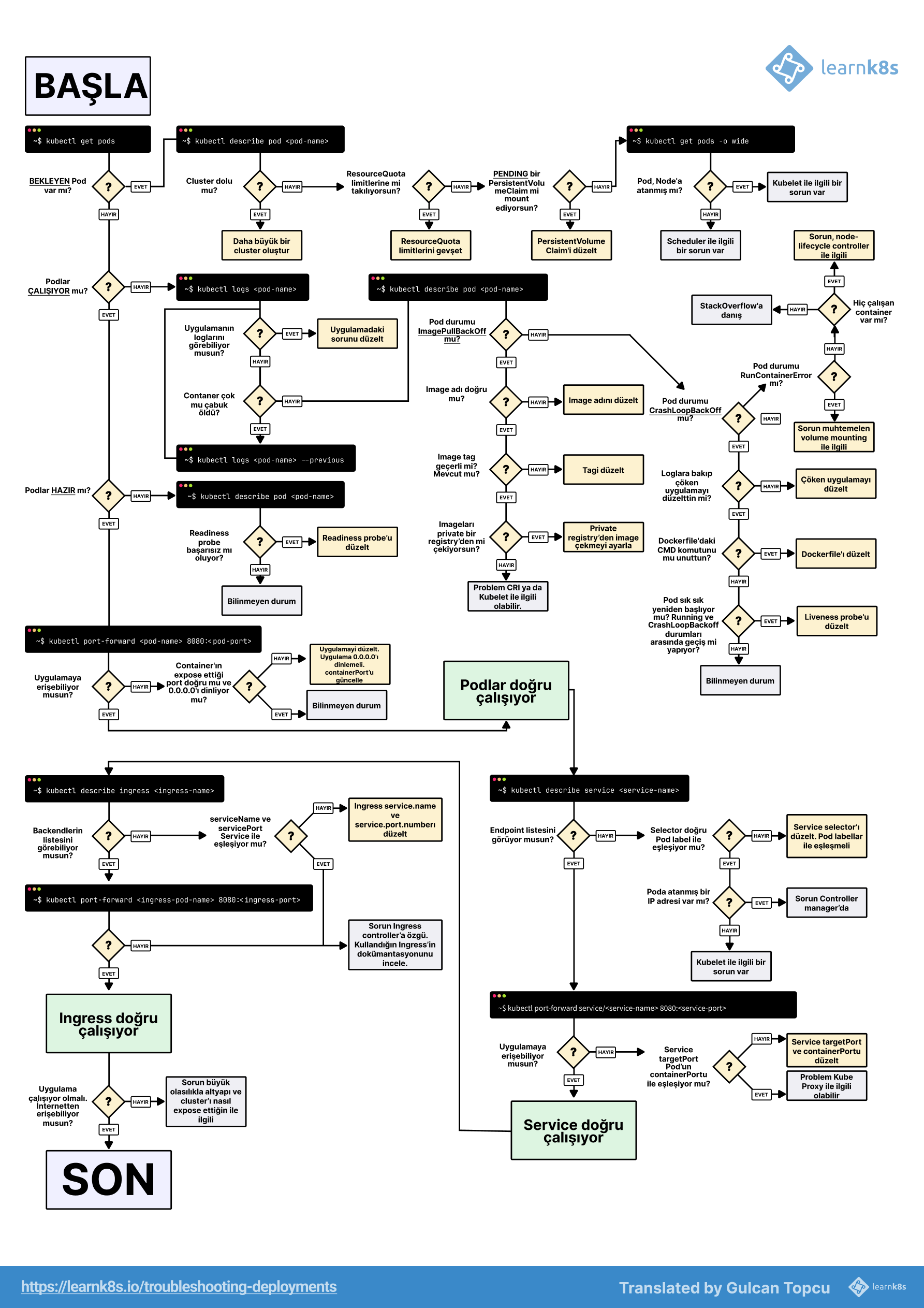
When everything's on fire, you have maybe 5 minutes before panic sets in and management starts breathing down your neck. Here's what I learned after getting paged at 3am more times than I care to remember.
Step 1: Is kubectl Even Working?
Before you do anything fancy, check if you can talk to your cluster at all:
kubectl cluster-info
If this times out, your control plane is fucked. I wasted 4 hours once debugging a "cluster failure" that was just my VPN disconnecting. Always check the obvious shit first.
The kubectl cluster-info command should return URLs for your API server and other core services. If you're getting timeouts, check your kubeconfig file and network connectivity before diving deeper.
Common error messages you'll actually see:
Unable to connect to the server: dial tcp: lookup kubernetes.docker.internal- Your kubeconfig is pointing to the wrong clusterThe connection to the server localhost:8080 was refused- You forgot to set your contexterror: You must be logged in to the server (Unauthorized)- Your token expired while you were sleepingdial tcp 10.0.0.1:6443: i/o timeout- API server is overloaded or dead (this one always means bad news)
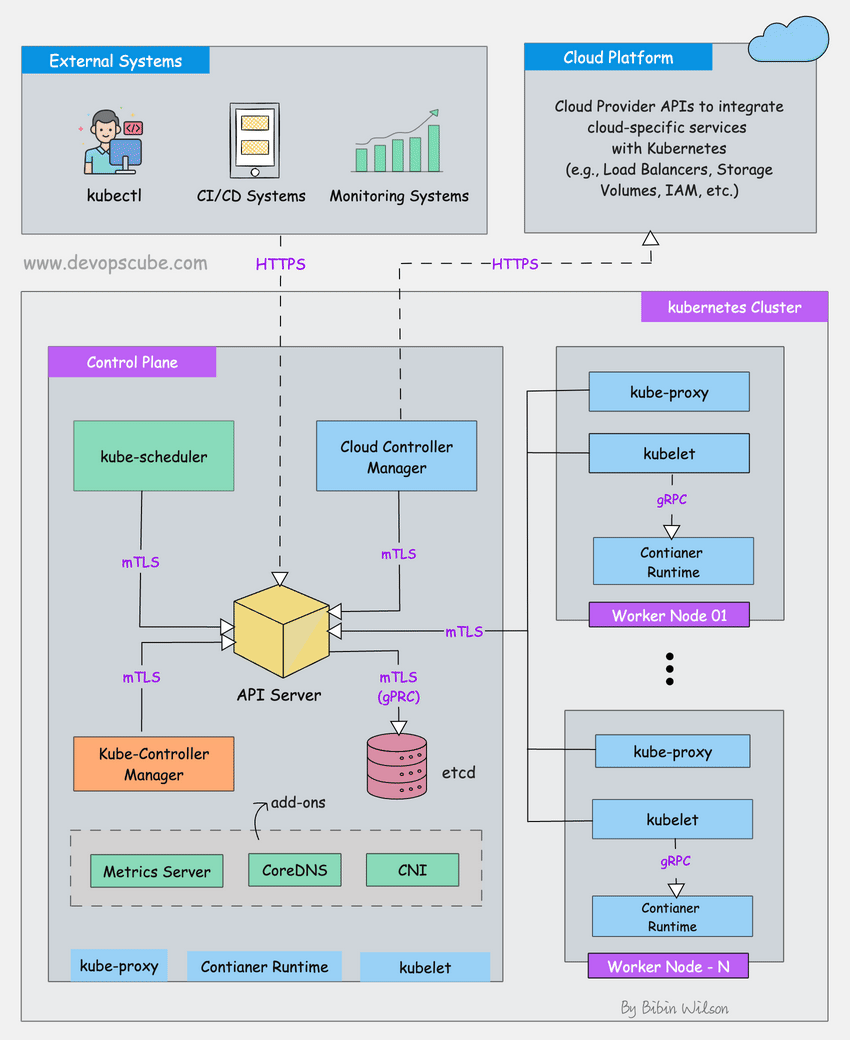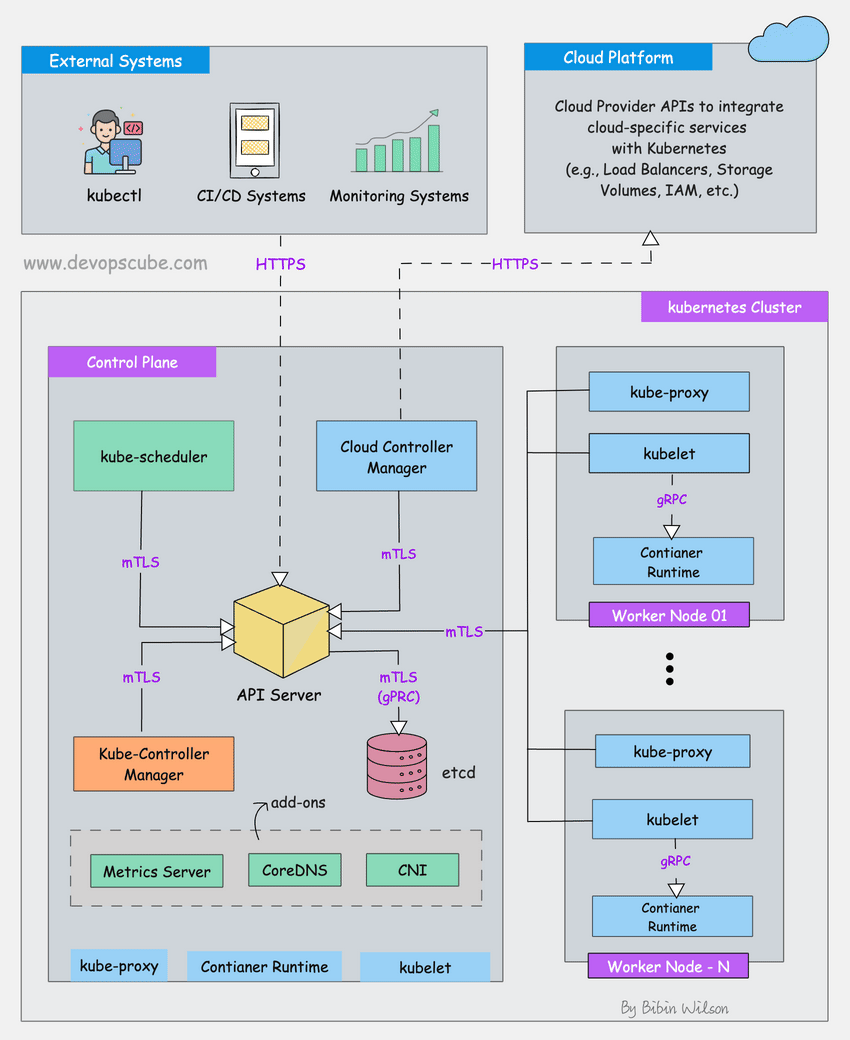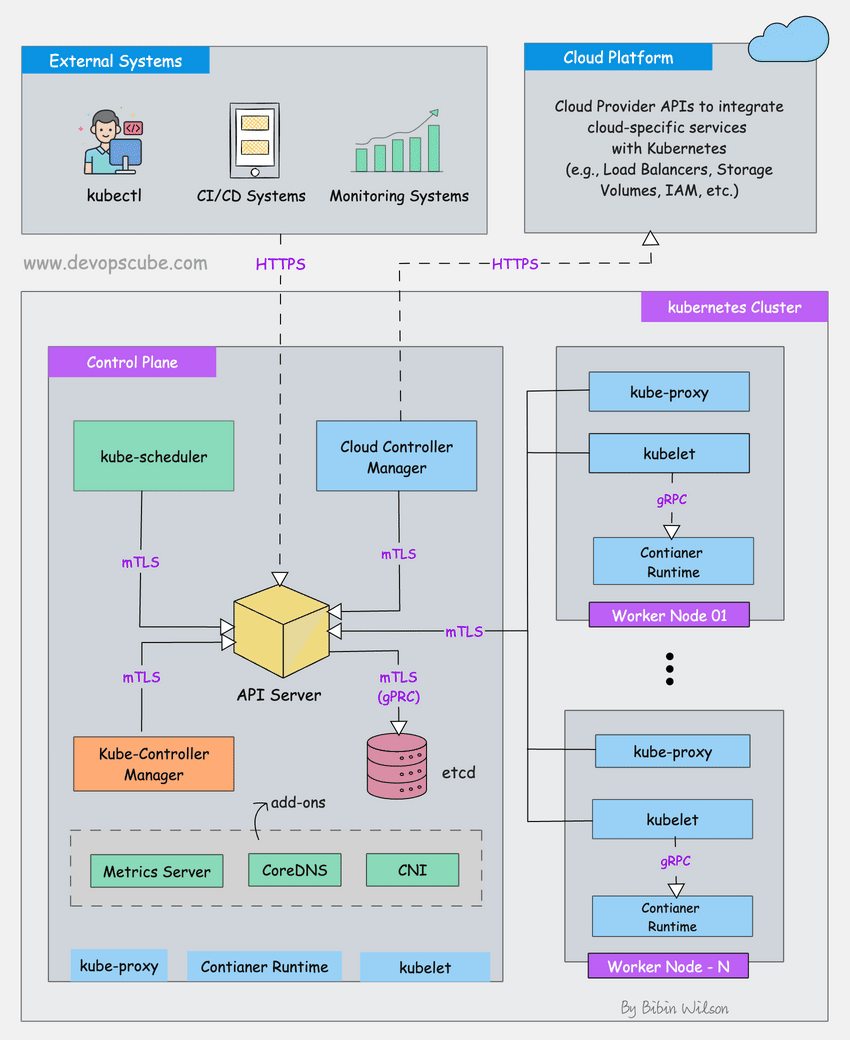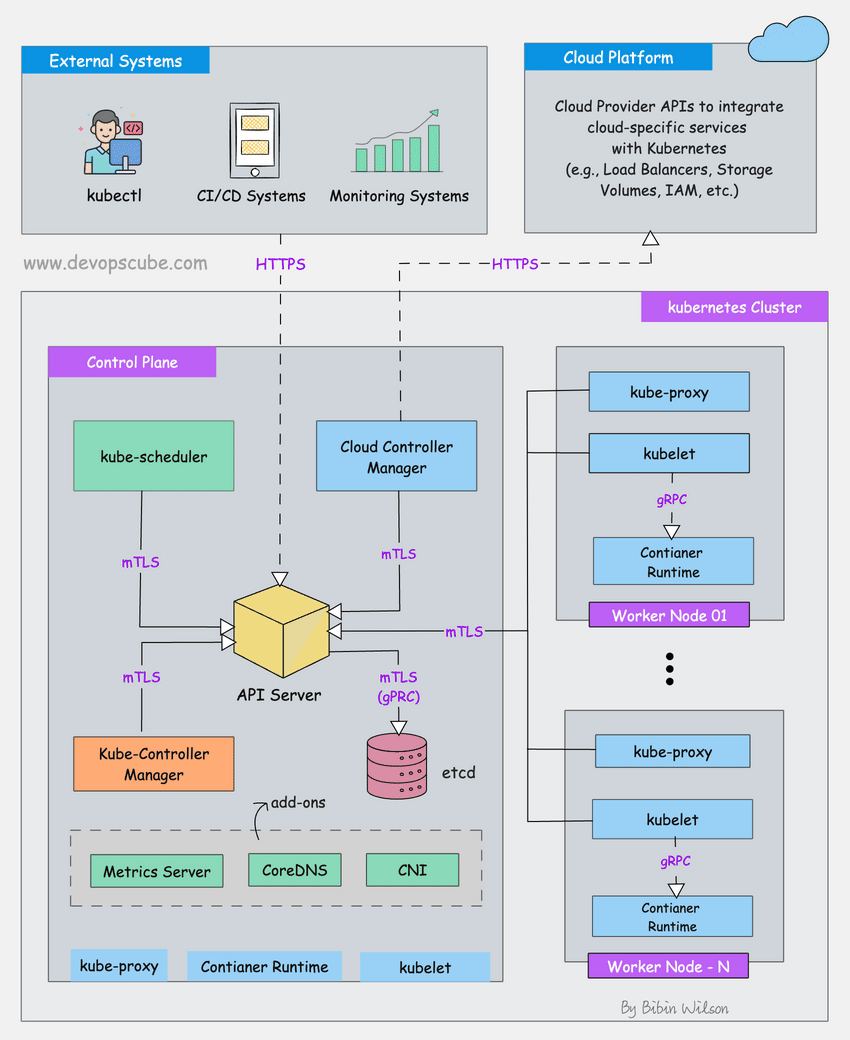
Step 2: Check If Your Nodes Are Still Alive
kubectl get nodes -o wide
If you see a bunch of NotReady status, don't panic yet. I've seen nodes show as NotReady for stupid reasons like:
- Network hiccup that lasted 30 seconds
- Node ran out of disk space because someone left debug logs running
- Cloud provider decided to restart the VM without telling anyone
Check the node conditions to understand what's actually broken. The kubelet logs usually have the real story. Pro tip: Take a screenshot of the node status. You'll forget the exact error when you're stressed and your manager asks what happened.
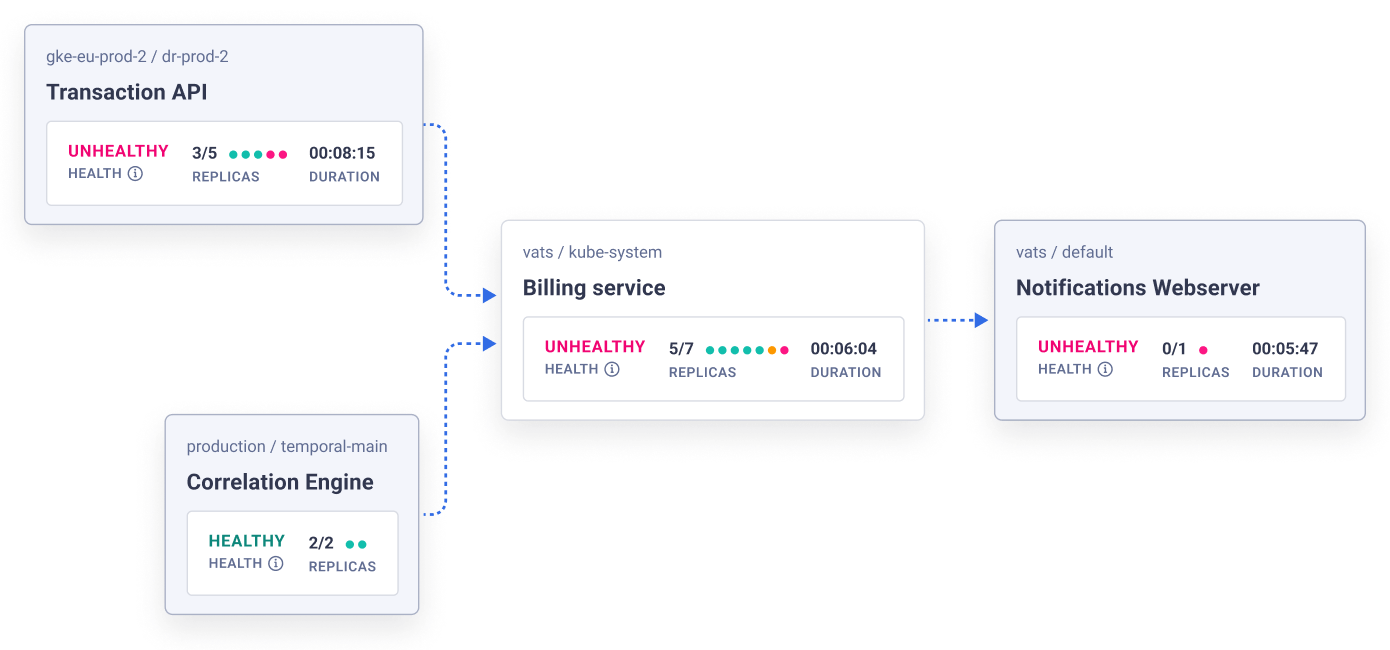
Step 3: What's Actually Running in kube-system?
kubectl get pods -n kube-system --sort-by=.status.phase
This shows you what control plane components are actually alive. Key things to look for:
- kube-apiserver pods stuck in
Pending= you're totally fucked - etcd pods in
CrashLoopBackOff= data corruption, probably need to restore from backup - kube-controller-manager failing = workloads won't get scheduled
Had our EKS cluster go down once because AWS rotated some cert we didn't know about. Spent forever troubleshooting the wrong thing because their error messages are garbage. Check the EKS troubleshooting guide if you're on AWS.
For Managed Clusters: Check Your Cloud Provider First
If you're running EKS, GKE, or AKS, check the cloud provider console before diving deep. Half the time it's:
- Planned maintenance they forgot to announce
- Your account hit a quota limit
- Their control plane is having issues (happens more than they admit)
Had our EKS cluster mysteriously die during a product demo once. Spent 30 minutes debugging our apps before checking the AWS console - they'd deprecated the control plane version we were using and auto-upgraded us mid-demo. Thanks, AWS.
Don't feel bad about checking this first - I've debugged "mysterious" cluster issues that were just AWS having a bad day. Check GKE status and Azure status pages too.
Reality Check: How Long Will This Take?
Based on actual experience, not textbook estimates:
Quick Fixes (15-30 minutes on 3-node cluster, 45+ minutes on 20+ nodes):
- Config mistakes you can fix with kubectl
- Restarting stuck pods
- Certificate renewals (unless you hit the cert rotation bug, then it's 2+ hours)
Medium Pain (1-3 hours on small clusters, 4-6 hours on large ones):
- Node failures requiring replacement (AWS takes 20-30 minutes just to provision new nodes)
- etcd issues that aren't corruption (compaction alone took 45 minutes on our 500GB etcd last time)
- Network policy fuckups (CNI restarts cascade across all nodes)
You're Fucked (4+ hours minimum, potentially days):
- etcd corruption without recent backups (took us 12 hours to rebuild everything from manifests)
- Multiple node failures in a small cluster (lost quorum = start over from scratch)
- Control plane components completely missing (happened during our k8s upgrade disaster)
Pro tip: If you can't get basic kubectl commands working in 15 minutes, something is fundamentally broken and you need to escalate. Check the official troubleshooting docs and don't be afraid to call your cloud provider support - that's what you're paying for.