Here's what the docs don't tell you about production deployments. We've deployed Weaviate clusters that handle billions of vectors, and I'm going to tell you exactly where shit goes sideways. Skip this section if you enjoy debugging mysterious memory leaks at 3am.
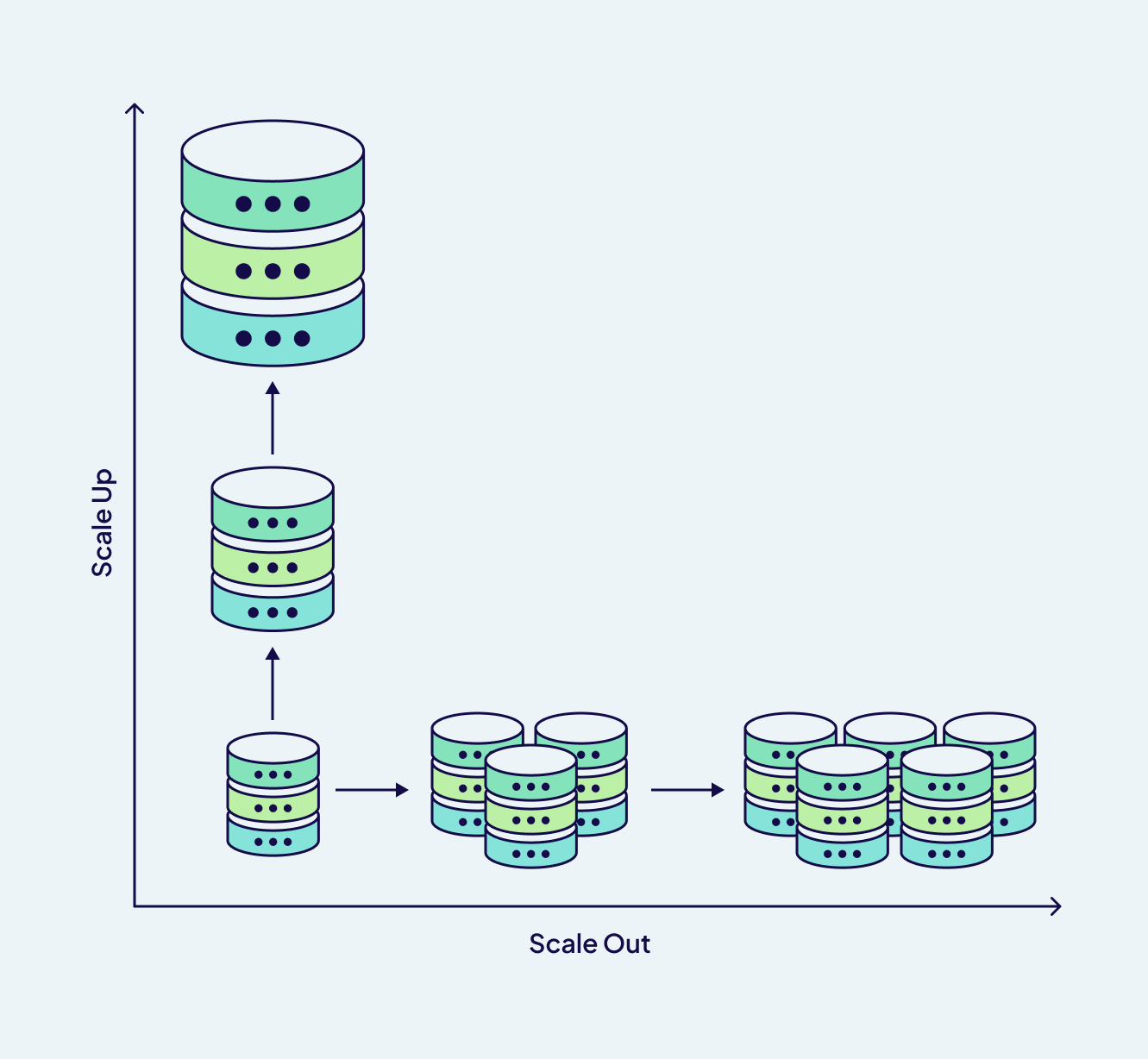
Memory Planning - Where Everyone Gets It Wrong
Look, I've watched teams blow their entire AWS budget because they trusted the memory planning docs. That (objects × dimensions × 4 bytes) + overhead formula works great in their lab environment, but here's what actually happens in production.
The Memory Formula is a Lie:
The formula assumes single-tenant, write-once workloads. Add multi-tenancy and suddenly you need 2x more memory. Add frequent updates and you're looking at 3x. I learned this after our staging cluster that handled 1M vectors fine completely shit itself when we hit production traffic. The resource requirements documentation glosses over these real-world multipliers.
What Actually Happens:
- 1M vectors = 3GB RAM in theory, 6GB+ in practice
- HNSW index rebuilding doubles memory usage temporarily
- Garbage collection pauses will make your queries timeout
- Memory fragmentation means you can't use all allocated RAM
- Multi-tenancy overhead adds 50-100% memory usage per tenant
Kubernetes "High Availability" is a Joke:
3 nodes sounds good until one dies during a memory spike and suddenly your "highly available" cluster has all pods running on the same overloaded node. You need 5+ nodes and proper pod anti-affinity or your HA cluster becomes a single point of failure faster than a JavaScript framework falls out of fashion. The cluster architecture docs conveniently forget to mention this.
HNSW Index Structure: This fancy algorithm builds a bunch of graph layers. Higher layers let you jump around fast globally, lower layers let you find the exact shit you're looking for. It's clever but eats memory like crazy.
AWS Storage Bills Will Make Your CFO Cry:
Use SSDs, obviously. The docs push provisioned IOPS like they're getting kickbacks from AWS. Our first production bill hit $4,800 in IOPS charges because our write pattern was dogshit and the deployment guide somehow forgot to mention that burst credits run out faster than your patience during a failed deployment. Start with EBS gp3 - it's fine until you actually hit a bottleneck. Don't upgrade to io2 just because some AWS solutions architect convinced you it's "enterprise grade." Check AWS storage optimization and Kubernetes persistent volume guides before AWS drains your bank account.
Security - The Other Thing That'll Break Your Deployment
Alright, let's talk security. This is where good intentions meet reality and reality usually wins.
Authentication: A Comedy of Errors:
API key auth works great until your security team discovers hardcoded keys in your Git history and starts scheduling "urgent security reviews." OIDC integration adds 500ms to every request and dies spectacularly when Azure AD decides to take a coffee break during your product demo. Reference the authentication troubleshooting guide and Kubernetes secrets best practices before your CISO makes you rewrite everything.
Network Policies Will Destroy You:
K8s network policies sound great until they block legitimate traffic in ways that take hours to debug. Start without them, get everything working, then add policies incrementally. Otherwise you'll spend your first week troubleshooting "connection refused" errors. Reference the Kubernetes network policy guide and CNI troubleshooting docs when everything breaks.
Security Architecture is a Beautiful Disaster:
Your security setup will become a nightmare collection of API keys that get committed to Git, OIDC configs that break when someone sneezes on the identity provider, TLS certificates that expire during your vacation, network policies that block legitimate traffic in ways that make you question your life choices, and RBAC configs that work perfectly in staging but explode spectacularly in production. Every single layer of security will find new and creative ways to ruin your weekend.
TLS Certificates: Your 2AM Nightmare:
Weaviate requires TLS for production, because of course it does. cert-manager works perfectly in staging, then mysteriously stops renewing certificates in production and your entire search API goes dark during the holiday weekend. I watched this happen on Christmas Eve when Let's Encrypt rate limits kicked in and cert-manager just... gave up. Always have manual cert rotation scripts ready and test them monthly, not when you're getting paged while opening presents. Study TLS certificate management and Let's Encrypt production guidelines before your certificates expire during the IPO demo.
The RBAC Rabbit Hole:
RBAC configurations that work in staging will fail in prod because of subtle differences in service account permissions. Test your exact RBAC setup in a staging environment that mirrors production, not your local dev cluster. Study Kubernetes RBAC and service account documentation.
What You Actually Need to Monitor (Not What the Docs Say)
Production Monitoring Architecture: Set up Prometheus to collect metrics, Grafana to make pretty graphs, and alerts that'll wake you up when latency hits 100ms, memory usage goes above 80%, or index rebuilds take forever. Because someone needs to know when shit's about to hit the fan.
Metrics That Matter:
Prometheus metrics are fine, but focus on memory usage per node, query latency p99 (not p50), and index rebuild times. Everything else is noise until you're debugging a production incident. Set up Grafana dashboards and Prometheus alerting rules before you need them.
The Backup Disaster You Haven't Thought Of:
Weaviate backups work great until you need to restore them. Test your backup/restore process monthly, not when shit hits the fan. Cross-region replication sounds awesome until you deal with split-brain scenarios and data lag. Study backup configuration and disaster recovery patterns extensively.
Performance "Baselines" vs Reality:
Weaviate benchmarks show sub-millisecond latency in perfect conditions. In production, with network overhead, authentication, and real query patterns, expect 10-50ms response times. Plan accordingly. Check performance tuning guidelines and query optimization techniques.
The Hard Truth About "Production Ready":
Nobody is ever actually ready. You deploy to staging, everything breaks, you fix it, then deploy to production where it breaks in completely different ways that make you wonder if you're cursed. The entire "planning phase" is just elaborate guesswork until real users start hitting your API. Follow the production readiness checklist like scripture, but it'll still miss half the shit that actually goes wrong.