Stop Reading Bullshit Tutorials - Here's What Production Looks Like
I've been fighting with vector databases since early 2024. Pinecone costs a fortune, Weaviate's clustering is a nightmare, ChromaDB dies at any real scale. Qdrant actually works, and more importantly - it doesn't bankrupt you.
Why Qdrant Works When Others Don't
It's Built in Rust, Not Python:
Qdrant uses Rust under the hood, which means it doesn't shit the bed under load like ChromaDB. We're running 5M+ vectors with sub-50ms P95 latency on a $40/month Hetzner box. Try doing that with ChromaDB - you'll be waiting forever. The Rust performance benefits are real, with detailed benchmarks showing consistent sub-100ms response times even at scale.
The Latest Version (v1.15.4) Has Stuff That Matters:
Qdrant v1.15 added asymmetric binary quantization which cut our memory usage by 60%. The BM25 local inference in v1.15.2 means hybrid search actually works now without external dependencies. Check the official documentation for the latest features, and the GitHub repository has real-world performance discussions.
LangChain Integration (When It Works):
The langchain-qdrant package exists but the error messages are useless. Spent 3 hours debugging connection timeouts because the docs don't mention you need to set prefer_grpc=False for Docker networking issues. The hybrid search with FastEmbed works once you figure out the right parameters, but expect to read source code. The LangChain official integration docs are actually helpful, and there's a solid integration tutorial from Qdrant themselves.
How to Actually Deploy This Thing
1. Start Simple, Don't Fuck Around with Clusters
What Actually Works:
Your App → Docker Qdrant → SSD Storage
↓
Load balancer if you need it
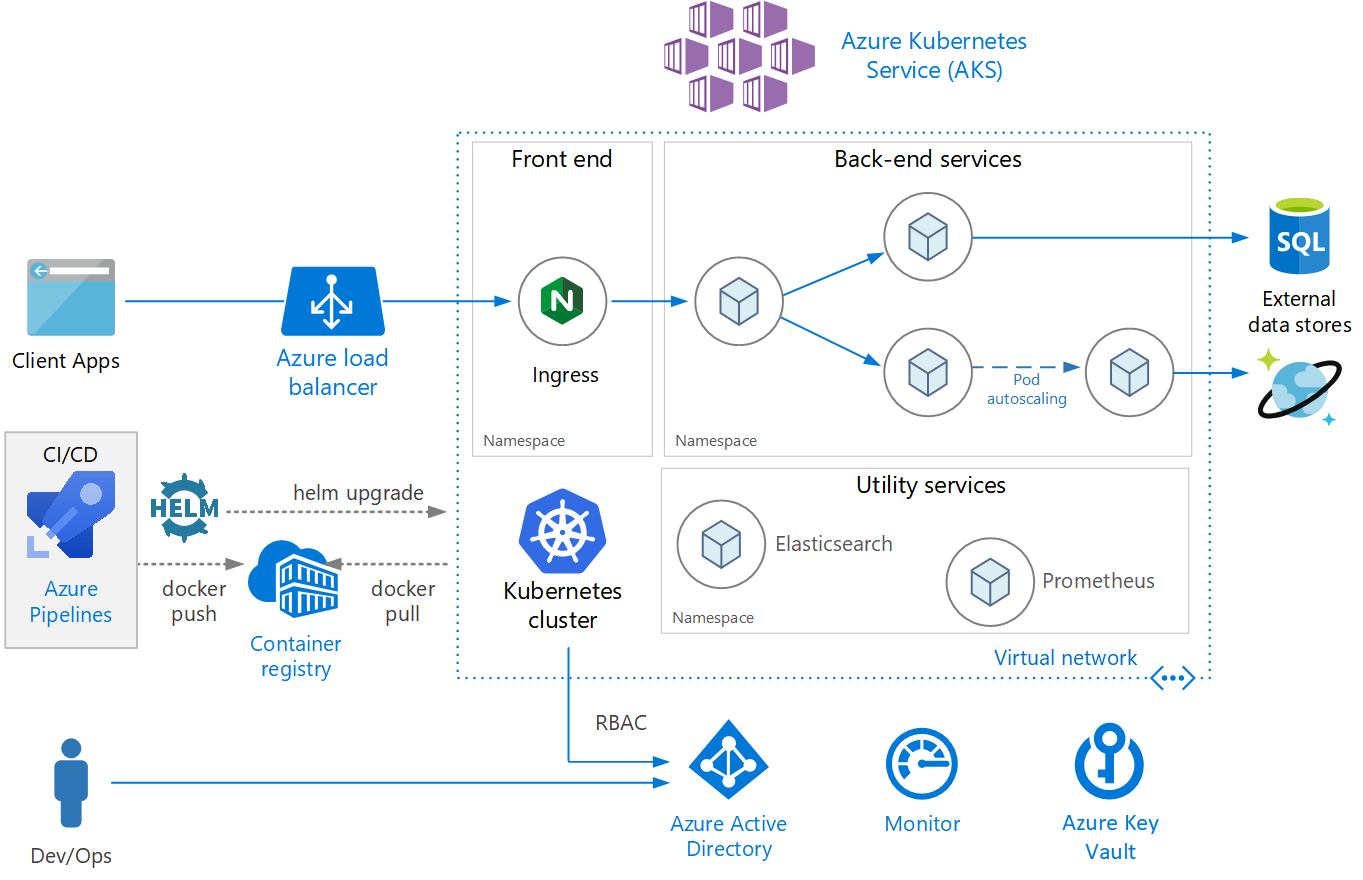
I wasted 2 weeks trying to set up distributed mode for 2M vectors. Single node on a $40 Hetzner dedicated server handles our traffic fine. Don't over-engineer this shit.
OK, enough bitching. Here's the actual setup...
Real Resource Requirements (From Production):
- CPU: 4 cores minimum. 2 cores = slow queries when indexing
- Memory: Plan 2GB per million vectors, not 1GB. The official docs underestimate this
- Storage: Fast SSD or you'll hate life. NVMe if you can afford it. AWS EBS gp3 works fine, DigitalOcean block storage is cheaper
- Network: Whatever - it's not the bottleneck. Docker networking basics matter more than bandwidth
For detailed resource optimization, see the Qdrant performance guide and Docker production best practices.
Docker Compose That Won't Fuck You Over:
services:
qdrant:
image: qdrant/qdrant:v1.15.4
container_name: qdrant_production
restart: unless-stopped
ports:
- \"6333:6333\" # REST API
- \"6334:6334\" # gRPC (optional but faster)
volumes:
- qdrant_data:/qdrant/storage
- ./config/production.yaml:/qdrant/config/production.yaml
environment:
- QDRANT__SERVICE__API_KEY=${QDRANT_API_KEY}
- QDRANT__LOG_LEVEL=INFO
- QDRANT__SERVICE__MAX_REQUEST_SIZE_MB=64
healthcheck:
test: [\"CMD\", \"curl\", \"-f\", \"http://localhost:6333/healthz\"]
interval: 30s
timeout: 10s
retries: 3
deploy:
resources:
limits:
memory: 8G # Learned this the hard way after 3 container crashes
cpus: '4.0'
volumes:
qdrant_data:
2. Distributed Cluster (Enterprise Scale)
Multi-Node Architecture:
Load Balancer → Qdrant Cluster (3+ nodes) → Distributed Storage
↓ ↓ ↓
Application Layer → [Node 1, Node 2, Node 3] → Consensus & Replication
Qdrant's clustering actually works, unlike most databases that shit the bed when you add more nodes. It keeps your data consistent without the single point of failure nightmare that'll wake you up at 3am.
When You Need Distributed Deployment:
- Data Volume: 50M+ vectors or 500GB+ storage
- Query Load: 1000+ QPS sustained traffic
- Availability: 99.9%+ uptime requirements
- Latency: Sub-10ms P99 response times globally
Check the Qdrant clustering documentation for distributed deployment patterns and the indexing guide for HNSW parameter tuning.
3. Kubernetes Production Pattern
Cloud-Native Deployment:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: qdrant-cluster
spec:
serviceName: qdrant
replicas: 3
selector:
matchLabels:
app: qdrant
template:
spec:
containers:
- name: qdrant
image: qdrant/qdrant:v1.15.4
ports:
- containerPort: 6333
- containerPort: 6334
env:
- name: QDRANT__CLUSTER__ENABLED
value: \"true\"
- name: QDRANT__SERVICE__API_KEY
valueFrom:
secretKeyRef:
name: qdrant-secret
key: api-key
volumeMounts:
- name: qdrant-storage
mountPath: /qdrant/storage
resources:
requests:
memory: \"4Gi\"
cpu: \"1000m\"
limits:
memory: \"8Gi\"
cpu: \"2000m\"
volumeClaimTemplates:
- metadata:
name: qdrant-storage
spec:
accessModes: [\"ReadWriteOnce\"]
resources:
requests:
storage: 100Gi
storageClassName: fast-ssd
Kubernetes Reality Check:
- Storage: You'll need persistent volumes or your data disappears when pods restart (learned this the hard way)
- Updates: Set pod disruption budgets or your users get 503 errors during deployments
- Security: Network policies are a pain to configure but necessary if you value your job
- Scaling: HPA works but tune it carefully - too aggressive and your pods thrash like crazy
The Kubernetes StatefulSets documentation covers the basics, but check production StatefulSet patterns for real deployment strategies. Container monitoring is crucial - don't deploy blind.
Security Architecture for Production
Authentication & Authorization:
from qdrant_client import QdrantClient
## Production client with API key authentication
client = QdrantClient(
url=\"https://your-qdrant-instance.com\",
api_key=os.getenv(\"QDRANT_API_KEY\"),
timeout=60,
https=True,
verify=True # SSL certificate verification
)
Network Security (Don't Skip This Shit):
- HTTPS: Use TLS or your API keys are toast in network logs
- API Keys: Rotate them quarterly - learned this after Dave left with production keys in his personal .env file
- Private Networks: Don't expose Qdrant to the internet unless you want to get pwned
- Firewalls: Lock down ports 6333/6334 or enjoy random crypto mining in your cluster
Data Protection (Your Ass Is On The Line):
- Disk Encryption: Turn it on or explain data breaches to legal
- Backup Security: Encrypt your S3 backups - unencrypted backups are security theater
- Audit Logs: Log API calls because auditors will ask and "we don't log that" isn't an answer
- Compliance: GDPR/SOC2 means real processes, not just checking boxes
Cost Reality Check (Real Numbers From Our Bills)
What We Actually Pay (5M vectors, ~200 QPS average):
| Platform | What They Charge | Hidden Costs | Real Monthly Cost |
|---|---|---|---|
| Pinecone | Starts around $70/1M | Bandwidth costs will murder your budget | $400-500+ (depends on how much they hate you) |
| Weaviate Cloud | Confusing pricing | Support costs | Never figured it out |
| Self-Hosted (Hetzner) | $40-60 server | Couple hours maintenance | $40-60 |
The Break-Even Math:
If you're doing more than 1M vectors, self-hosting saves you hundreds monthly. The catch? You need someone who doesn't panic when Docker containers restart at 3am. If you're a 3-person startup, pay for managed. If you have ops people, self-host and buy better coffee with the savings.
Things That Will Break and How to Fix Them
Memory Leaks (Happened to Us Twice):
Qdrant slowly eats RAM until the container gets OOM killed. Check /metrics endpoint for process_resident_memory_bytes. If it keeps growing, restart the container. This is usually indexing operations not cleaning up properly.
## Monitor memory usage via Qdrant metrics endpoint
curl \"http://your-qdrant-host:6333/metrics\" | grep memory
## Note: Replace your-qdrant-host with your actual Qdrant host in production
## Metrics endpoint documentation: https://qdrant.tech/documentation/guides/monitoring/
## Nuclear option when memory is fucked
docker restart qdrant_production
Slow Queries After Index Rebuilds:
The HNSW parameters in your collection config matter. If queries slow down after optimization, check ef parameter - it's probably too low.
Connection Timeouts with LangChain:
LangChain's default timeout is 5 seconds, which is stupid for large queries. Set it higher:
from qdrant_client import QdrantClient
client = QdrantClient(
url=\"http://localhost:6333\",
timeout=60 # Don't use 5 seconds like the docs say
)
Docker Networking Issues:
If you're getting connection refused errors, the problem is usually Docker's DNS. Use host.docker.internal instead of localhost if connecting from another container, or just put everything on the same Docker network.
When Performance Goes to Shit:
- Check disk I/O first -
iostat -x 1 - RAM usage second - Qdrant will swap and die
- Query the
/collections/{name}endpoint to see optimization status - If all else fails, restart. It's faster than debugging
The official Qdrant docs are actually decent, unlike most database docs. The GitHub issues are where you'll find real solutions to production problems. For monitoring and observability, check the API reference and retrieval quality guide.