![]()
Now that we've covered the practical gotchas, let's dive into what makes Qdrant different from the dozen other vector databases trying to solve the same problem. Qdrant is a vector database written in Rust that doesn't fall over when you throw real data at it - but the devil is in the details.
The name comes from "quadrant" but everyone I know just calls it "Q-drant" and moves on.
Why It's Actually Fast
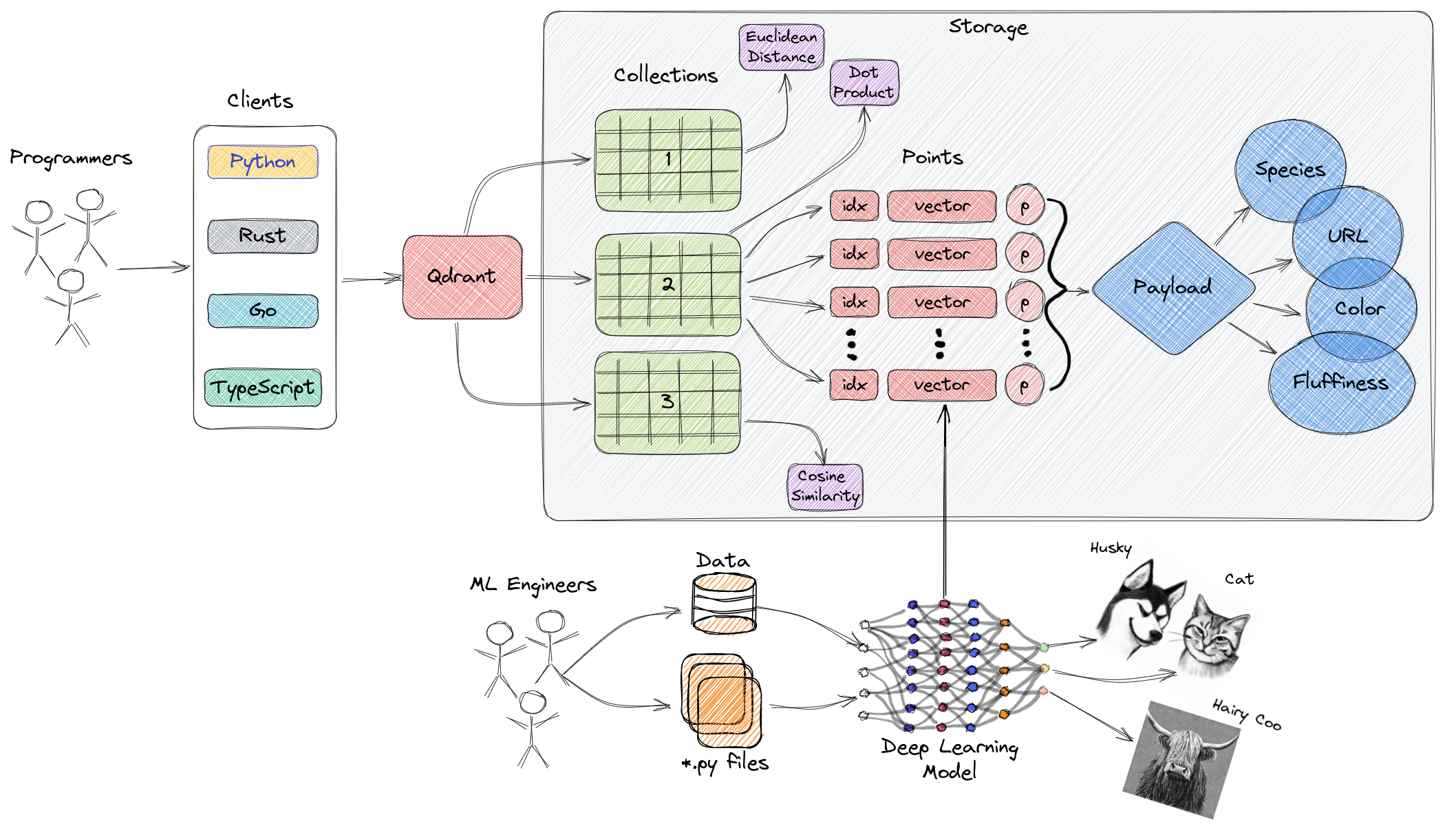
Most vector databases are academic toys dressed up for production. Qdrant was built in Rust by people who actually had to run this shit at scale.
HNSW That Works: The HNSW algorithm is great in theory, terrible in practice when you need filtering. Qdrant's implementation actually handles complex queries without accuracy going to hell. I've seen other databases lose 40% accuracy when you add simple metadata filters - Qdrant doesn't do that.
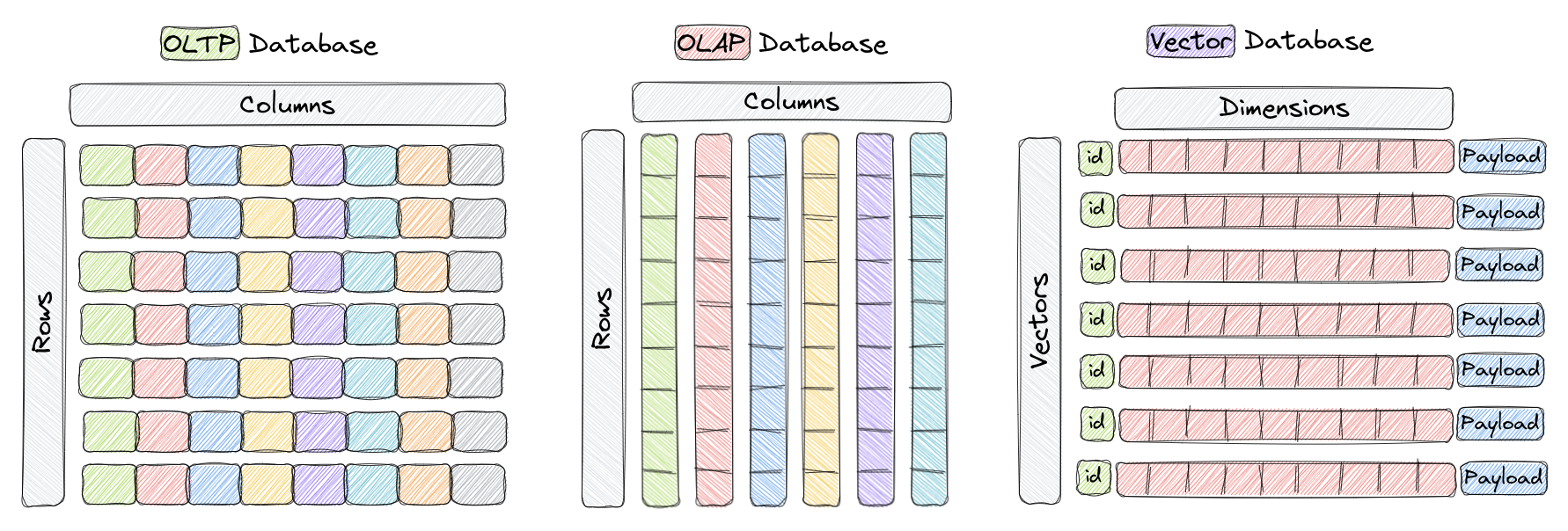
Memory Management That Isn't Broken: The quantization feature can genuinely reduce RAM usage by 60-80% in real deployments. Not the "97%" they claim in marketing, but still enough to make a 32GB server handle what used to need 128GB.
I/O That Doesn't Suck: They use io_uring on Linux, which actually matters when you're hitting disk. AWS EBS performance goes from "meh" to "actually usable" with proper async I/O.
The Performance Numbers (That Aren't Bullshit)
We tested Qdrant against Pinecone and Weaviate on our production workload:
- Qdrant handled 80k queries/day where Pinecone timed out at 20k
- Query latency stayed under 50ms at 95th percentile (Pinecone hit 200ms regularly)
- The official benchmarks match what we saw - 4x better RPS is real
HubSpot's case study mentions similar numbers. When a company that big says something works, it probably works.
Features That Actually Matter
Hybrid Search: You can store both dense and sparse vectors in the same collection. This means semantic search + keyword matching in one query instead of two separate systems. Launched in v1.13 and it actually works.
Custom Scoring: The v1.14 release added score boosting where you can weight results by recency, location, or whatever business logic you need. Most other databases make you do this in application code.

Filtering That Doesn't Break Everything: Filterable HNSW means you can do complex metadata queries without the database shitting itself. This is huge if you need multi-tenant systems or user-specific filtering.
Deployment Options (That Don't Suck)
Docker works fine for development. For production:
- Self-hosted: You own the hardware, you own the problems. Installation guide is actually decent.
- Qdrant Cloud: Managed service starting at $25/month. Still cheaper than Pinecone's $50 minimum.
- Kubernetes: Use their Helm chart unless you like debugging PV mount issues.
The nice thing is you can start local, prove the concept works with real data, then move to cloud without rewriting everything. Unlike switching from SQLite to PostgreSQL, the migration path is actually smooth.

