The problem isn't networking theory
- it's that every fucking service team reinvents the same broken networking code.
The Real Problem:
Everyone Implements Networking Differently
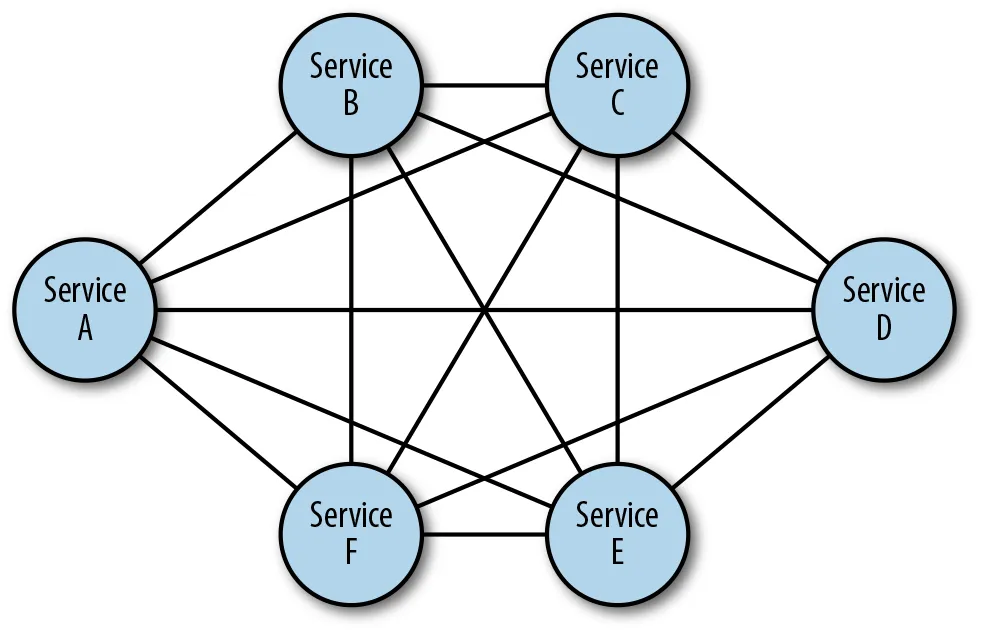
When you decompose a monolith into microservices without Envoy, you inherit a nightmare of inconsistent networking implementations:
- The Java team uses Hystrix for circuit breakers (because Netflix told them to)
- The Go team writes their own retry logic (because "it's just a for loop")
- The Python team uses requests with urllib3 and calls it a day
- The Node.js team has 47 HTTP client libraries and uses a different one each week
Six months later, you're debugging a production outage at 3am and every service handles timeouts differently.
The Java service retries for 30 seconds, the Go service gives up after 1 second, and the Python service just hangs forever because nobody configured a timeout.
I've been there. We spent 2 weeks debugging why our payment service was timing out, only to discover that the Node.js client was sending Connection: keep-alive but the Java service was closing connections after each request.
Check Envoy's HTTP connection management and debugging guides for similar issues.
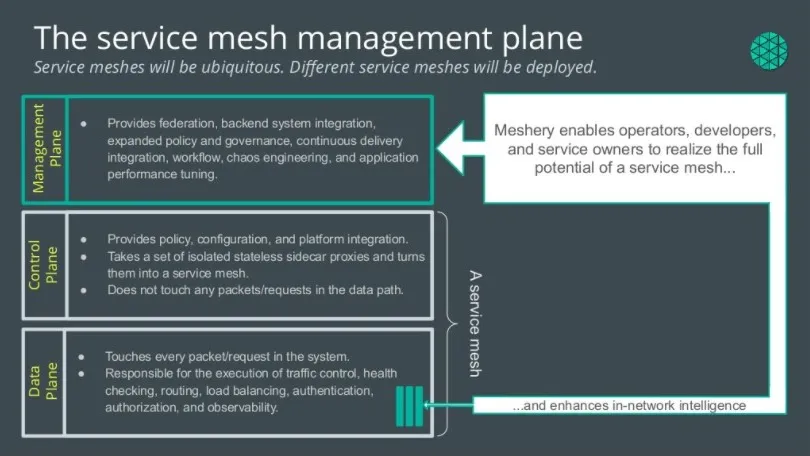
How Envoy Actually Solves This Shit
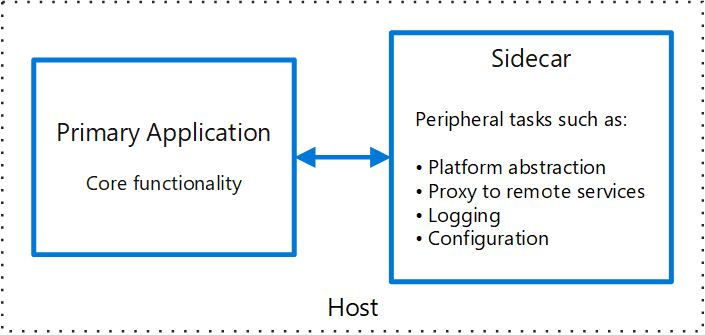
Instead of trusting every team to implement networking correctly, Envoy runs as a separate process and handles all network traffic.
Every service just talks to localhost:8080 and Envoy deals with the actual networking.
Consistent behavior everywhere:
Circuit breakers work the same way whether you're talking from Java to Python or Go to Node.js. No more language-specific quirks.
Hot configuration updates:
Change routing rules without restarting anything. The first time you update traffic routing from 50/50 to 90/10 without downtime, you'll never go back to NGINX reloads.
Built-in observability:
Every request gets logged, timed, and traced without touching your application code. When that service is slow at 2am, you'll know exactly where the bottleneck is.
The Memory and CPU Tax
Yes, Envoy uses resources. Each sidecar typically uses 10-50MB of RAM and adds 1-5ms latency.
If you're running 1000 services, that's 50GB of RAM just for proxies.
Is it worth it? Hell yes. The alternative is spending weeks debugging networking issues that Envoy prevents entirely.
War Story: Circuit Breakers That Actually Work
At my previous job, we had a payment processing service that would cascade fail every Black Friday.
The root cause? Our Java service used one circuit breaker library, our Python service used a different one, and our Go service didn't have circuit breakers at all.
After switching to Envoy, circuit breakers work consistently across all services.
When the payment service starts throwing 500s, Envoy automatically stops sending requests and serves cached responses. The circuit breaker saved our ass during a database outage
- instead of a total site failure, we had degraded functionality.
When NOT to Use Envoy
Don't use Envoy if:
- You have 3 services and they all talk HTTP to each other
- You're perfectly happy with NGINX and haven't hit any limitations
- Your team can't handle YAML configuration complexity
- You're not ready for the operational overhead of service mesh
But if you're debugging network issues regularly, dealing with inconsistent retry behavior, or want actual observability into service-to-service communication, Envoy is worth the complexity.
Explore production deployment patterns, observability features, and performance tuning guides to get started.