Look, microservices networking is a nightmare. I've spent way too many weekends debugging container-to-container communication issues, watching services randomly fail to find each other, and cursing at load balancers that decide to route 100% of traffic to the one pod that's about to die.
This Docker + Kubernetes + Istio stack helps solve these problems, but it also creates entirely new ways for your infrastructure to fail spectacularly. The promise is simple: reliable networking, automatic security, and deep observability without touching your application code. The reality is a complex distributed system that requires expertise in container orchestration, proxy configuration, and certificate management.
But here's the thing - when it works, it actually delivers on those promises. The question is whether you're prepared for the operational complexity that comes with it.
The Architecture That Actually Matters

Envoy Proxies Everywhere: Istio shoves an Envoy proxy into every single pod as a sidecar container. These proxies intercept ALL network traffic - which sounds great until you realize they also eat CPU, add latency, and crash silently leaving you with zero useful logs.
![]()
Each sidecar uses about 100MB RAM and burns through CPU cycles like cryptocurrency mining. Multiply that by your pod count and watch your AWS bill explode.
The Control Plane That Controls Everything: Istiod is the brain that tells all those proxies what to do. When it works, it's magic. When it breaks (and it will break), every service in your mesh stops talking to each other simultaneously. I learned this at 2 AM during Black Friday.
What This Stack Actually Fixes
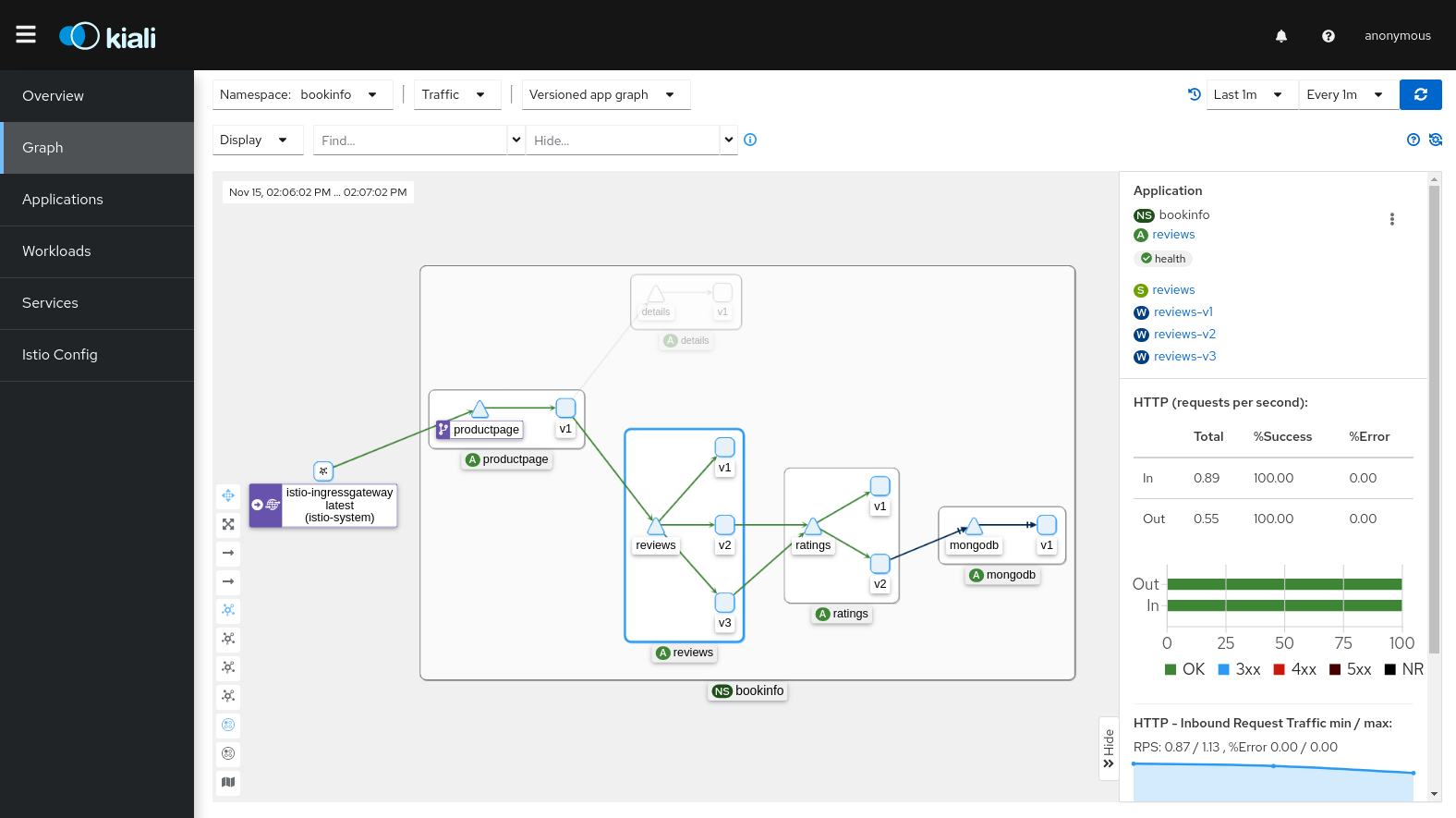
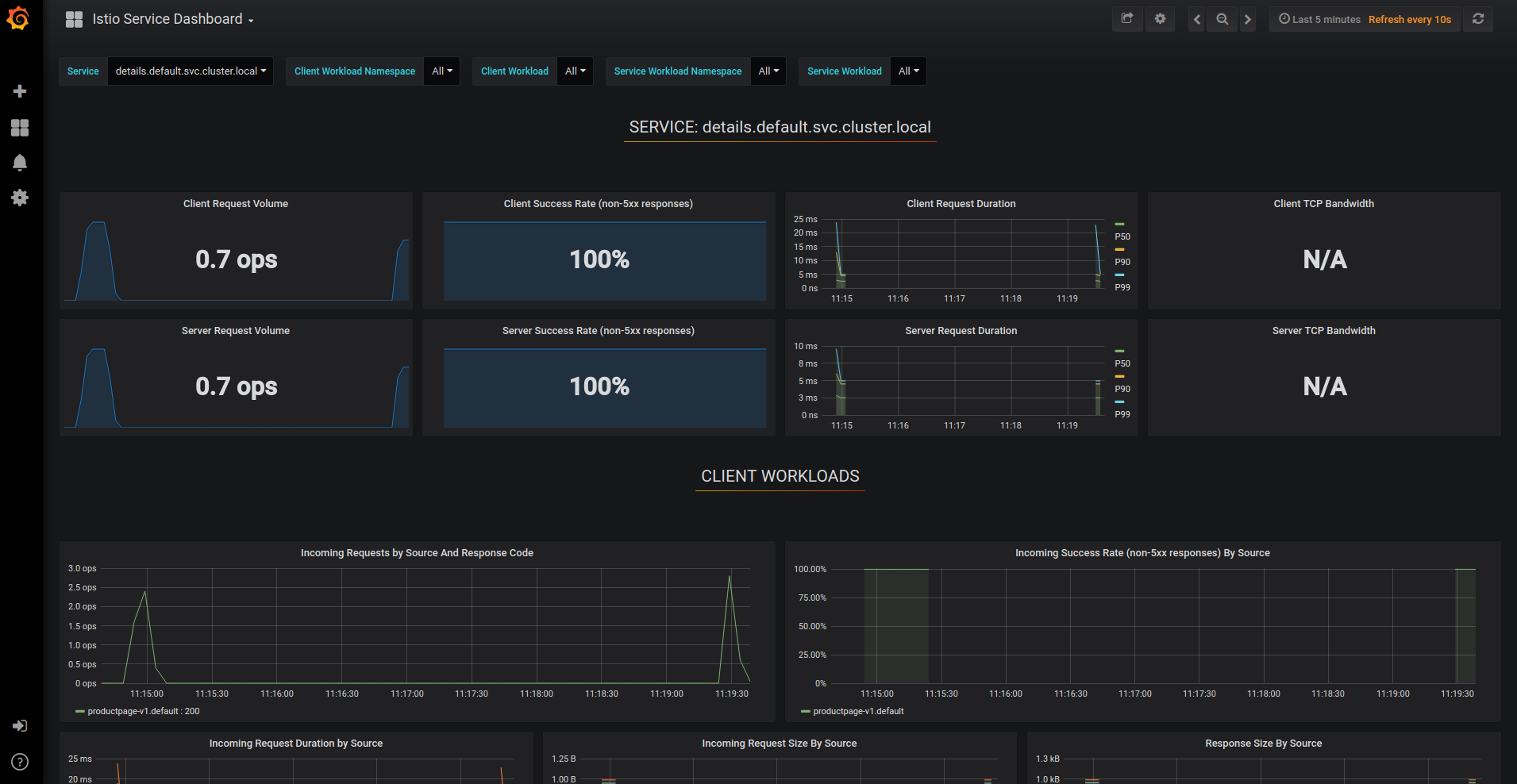
Observability Without Code Changes: This is legitimately awesome. Install Istio and suddenly you have RED metrics (request rate, error rate, duration) for every service without touching your application code. No more arguing with product managers about adding monitoring endpoints.
The catch? The metrics are only as good as your understanding of Envoy's configuration model, which is approximately as intuitive as quantum physics. You'll spend hours learning about clusters, listeners, and filter chains.
Security That Actually Works: Automatic mTLS between services is brilliant. Your services encrypt all communication without you writing a single line of TLS code. Certificate rotation happens automatically through Istio's PKI system.
Until it doesn't. Certificate rotation failures are silent killers - everything looks fine until services start rejecting each other's certificates and your entire mesh goes down. The SPIFFE specification that Istio uses is solid, but debugging certificate chain issues requires deep knowledge of X.509 certificates.
Traffic Splitting for Sane Deployments: Canary deployments with Istio actually work. You can route 5% of traffic to your new version while watching metrics, then gradually increase if everything looks good. The VirtualService and DestinationRule configurations give you fine-grained control.
This is the killer feature that makes the pain worth it. No more YOLO deployments to production. You can implement blue-green deployments, ring deployments, and feature flags at the infrastructure level.
Version Reality Check (September 2025)
Istio 1.27.1: Latest as of September 2025 and mostly stable. Supports Kubernetes 1.29-1.33. The 1.26.4 patch fixed the memory leaks that killed our staging cluster, but stick with 1.27+ anyway.
Kubernetes Compatibility: Stick with 1.30 or 1.31 if you value your sanity. The 1.29 release has some weird CNI interactions with Istio that cause random pod networking failures.
Resource Requirements: You need at least 16GB RAM and 8 CPU cores for even a tiny development cluster. The control plane alone uses more resources than most applications. Plan accordingly or watch your nodes get OOMKilled.
The Gotchas Nobody Warns You About
Ambient Mesh Reached GA: Ambient mesh officially went GA in Istio 1.24 (November 2024), but that doesn't mean it's ready for your production workload. The resource reduction is real, but debugging ambient mode failures still feels like reading tea leaves.
Sidecar Injection Breaking Existing Apps: Some legacy applications do weird networking things that break when you inject a proxy. Always test in staging first, and have a rollback plan that doesn't require DNS propagation.
Control Plane Single Point of Failure: Despite claims of "high availability," I've seen entire meshes go down when the control plane loses connection to etcd. Monitor control plane health obsessively.
The bottom line? This stack represents the current state of the art for microservices infrastructure, but it's not simple. You're trading application-level networking complexity for infrastructure-level complexity. Whether that trade-off makes sense depends on your team's expertise, operational maturity, and tolerance for debugging distributed systems at 3 AM.
If you're running 5 services, stick with basic Kubernetes networking. If you're running 50+ microservices with complex traffic patterns, security requirements, and observability needs, this pain might be worth it.