minikube is fucking useless for testing real production scenarios. Here's what actually matters when your clusters serve real traffic and downtime costs money.
SSL Certificate Management Hell
SSL certificates are where most people lose their minds with ingress controllers. NGINX Ingress Controller integrates with cert-manager to automate Let's Encrypt certificate provisioning, but you need to understand the certificate lifecycle or you'll be debugging expired certs at 2am.
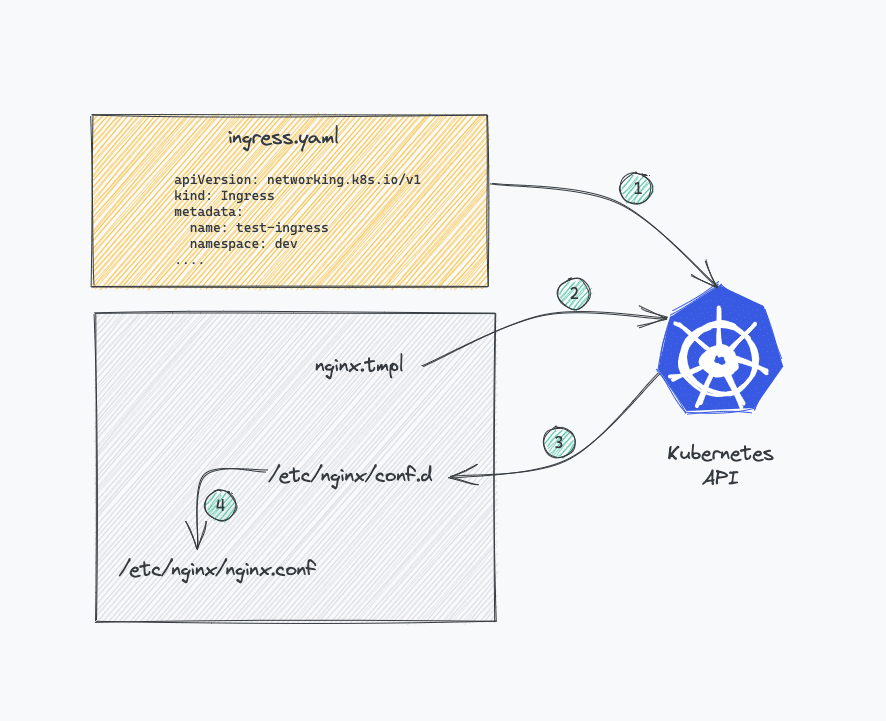
The automatic certificate provisioning works through annotations on Ingress resources. cert-manager watches for cert-manager.io/cluster-issuer annotations, requests certificates from ACME providers, and stores them in Kubernetes secrets. NGINX Ingress Controller automatically picks up the certificates and configures SNI properly.

But certificate rotation is where things break. Let's Encrypt certificates expire every 90 days, and cert-manager handles renewal automatically - until it doesn't. I've seen clusters where cert-manager failed to renew certificates because of DNS propagation issues, rate limiting, or ACME challenge failures. Nothing quite like getting paged at 3am because all your SSL certs expired and customers can't access the site.
The real gotcha is wildcard certificates. They require DNS-01 challenges instead of HTTP-01, which means cert-manager needs cloud DNS API credentials. Route53, CloudFlare, and Google DNS all work, but credential management becomes another failure point.
For production, you want multiple certificate issuers configured as backups. If Let's Encrypt rate limits kick in (50 certificates per registered domain per week), having a secondary ACME provider saves you from emergency certificate purchasing.
Load Balancing and Service Discovery
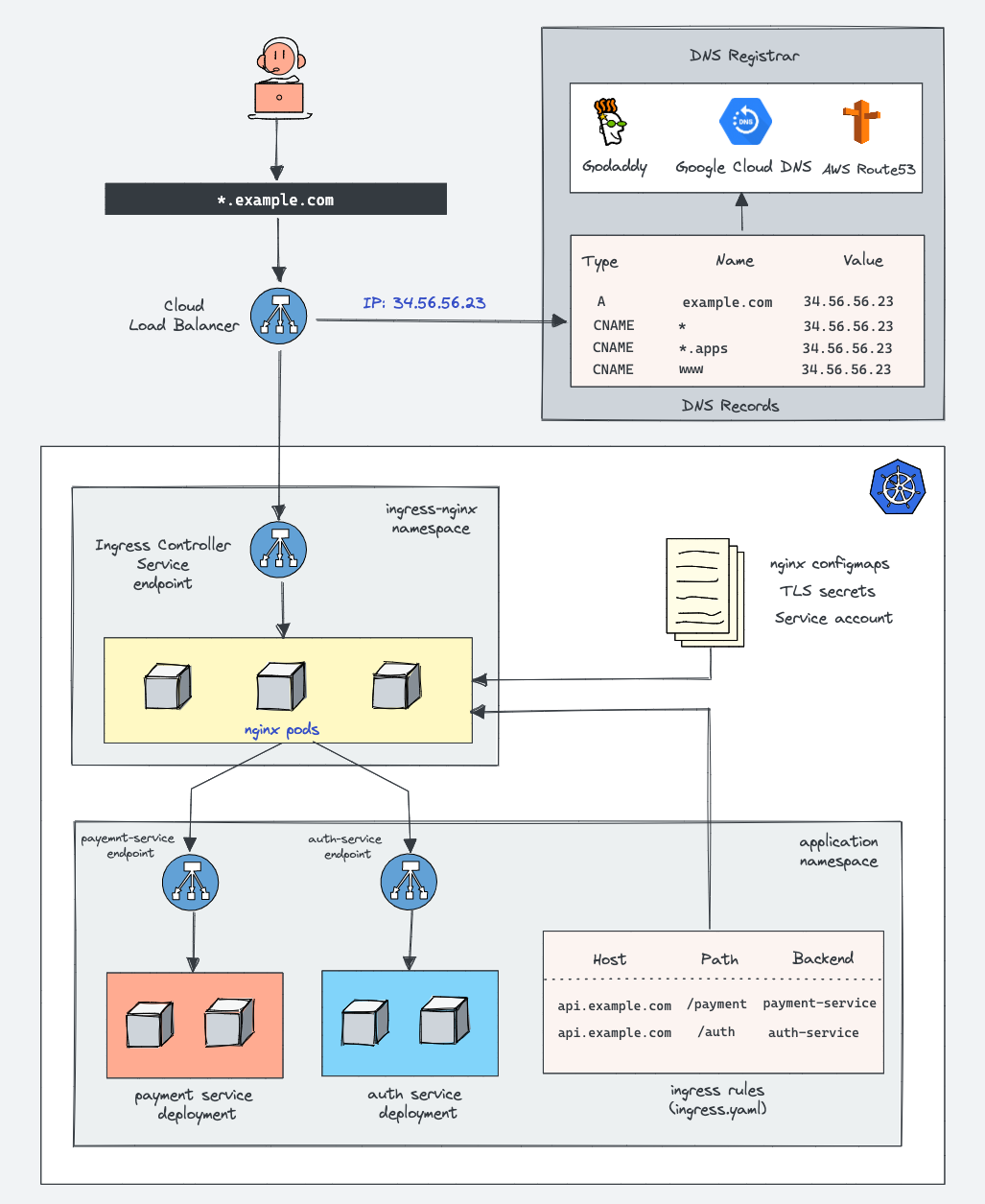
NGINX Ingress Controller handles Kubernetes service discovery automatically, but understanding the internals prevents mysterious traffic routing issues. The controller watches Endpoints resources and maintains NGINX upstream blocks with current pod IPs.
When pods scale or restart, there's a brief window where NGINX might still route to dead pod IPs. The controller usually detects endpoint changes fast, but I've seen it take 30 seconds when the API server was having a bad day. The nginx.ingress.kubernetes.io/upstream-fail-timeout annotation helps by marking failed upstreams as down faster - when it works right.
Session affinity is another production headache. The nginx.ingress.kubernetes.io/affinity annotation provides cookie-based or IP-based session persistence, but it fights against Kubernetes' load balancing philosophy. If you need session affinity, your application architecture probably needs work.
Rate Limiting That Actually Protects You
NGINX's rate limiting is one of its killer features, but configuring it correctly requires understanding burst handling and distributed rate limiting. The community ingress controller provides basic rate limiting through annotations, but F5's version offers sophisticated controls through Policy resources.
Basic rate limiting with nginx.ingress.kubernetes.io/rate-limit-rpm works for simple cases, but it applies per NGINX worker process, not globally across all ingress pods. Rate limits were completely fucked for weeks until I realized each worker process applies them independently. Took me way too long to figure out why we were getting flooded with 12x the traffic we expected. Should've actually read the docs instead of assuming it worked like a sane person would expect.
F5's advanced rate limiting supports tiered limits based on JWT claims - premium users get higher limits than free users. This requires deep integration between your authentication system and ingress configuration, but it's incredibly powerful for SaaS applications.
The biggest rate limiting mistake is not configuring burst properly. Without burst handling, legitimate traffic spikes trigger rate limits even when average rates are acceptable. The burst setting allows temporary spikes above the base rate, then enforces the average over time.
Security Beyond Basic TLS
NGINX Ingress Controller provides security features that go beyond basic SSL termination, but most people don't enable them properly. Security note: In March 2025, several critical vulnerabilities (CVE-2025-1974 and others) were disclosed affecting the community ingress-nginx controller. Make sure you're running patched versions and have proper network isolation. Web Application Firewall integration, geographic restrictions, and authentication delegation all work, but require careful configuration.
NGINX App Protect integration (F5 version only) provides WAF capabilities directly in the ingress controller. It can block SQL injection, XSS, and other OWASP Top 10 attacks at the ingress layer before they reach your applications. The detection accuracy is good, but tuning rules for your specific applications prevents false positives.
Geographic restrictions through the GeoIP module work well for compliance requirements. You can block or allow traffic from specific countries using MaxMind's GeoIP database. But IP geolocation isn't perfect - VPNs, proxies, and mobile carriers can make geographic restrictions unreliable.
Authentication delegation with the auth_request module lets you offload authentication to external services. The ingress controller makes a subrequest to your auth service for every request, caching responses based on your configuration. This centralizes authentication logic but adds latency and creates a dependency on your auth service.
Monitoring and Debugging Production Issues
When NGINX Ingress Controller breaks in production, you need visibility into what's happening at the NGINX level, not just the Kubernetes level. The default metrics are useful but incomplete for serious troubleshooting.
The nginx-prometheus-exporter provides detailed NGINX metrics including request rates, response codes, upstream health, and SSL handshake statistics. Combined with Kubernetes metrics from kube-state-metrics, you get full visibility into ingress performance.
But metrics don't help when traffic isn't reaching your pods at all. The nginx.ingress.kubernetes.io/enable-access-log annotation enables detailed access logging for specific ingresses. Combined with the kubectl logs from ingress pods, you can trace request routing decisions.
The most useful debugging technique is enabling NGINX debug logging temporarily. It shows exactly how NGINX processes requests, evaluates location blocks, and selects upstreams. The logs are verbose and will impact performance, but they reveal why requests aren't routing as expected.
Request tracing with OpenTelemetry (available in F5's recent releases) provides distributed tracing across your entire request path - when you can get it configured properly. You can see latency breakdown from ingress → service → pod → database, identifying bottlenecks and failures in complex microservice architectures.
High Availability and Scaling Patterns
Running NGINX Ingress Controller in production means planning for failures and scaling beyond single pod deployments. The typical pattern is running ingress controllers as a DaemonSet on dedicated nodes with NodePort services, but this creates single points of failure.
For true high availability, you want multiple ingress controller replicas behind a cloud load balancer. The cloud LB handles health checking and traffic distribution across ingress pods. If one pod dies, traffic routes to healthy instances automatically.
Node affinity rules ensure ingress pods run on different worker nodes, preventing a single node failure from taking down ingress entirely. Anti-affinity rules spread pods across availability zones in multi-AZ clusters.
But scaling ingress controllers isn't just about pod replicas - NGINX configuration complexity affects reload times. Large clusters with hundreds of ingresses start choking on config reloads. Someone added a fuckload of regex patterns and custom annotations to every ingress, and suddenly our 2-second reloads turned into 30-second nightmares. Never found out which genius thought that was a good idea. The F5 version's dynamic reconfiguration API reduces this clusterfuck by avoiding full NGINX reloads for certain changes.