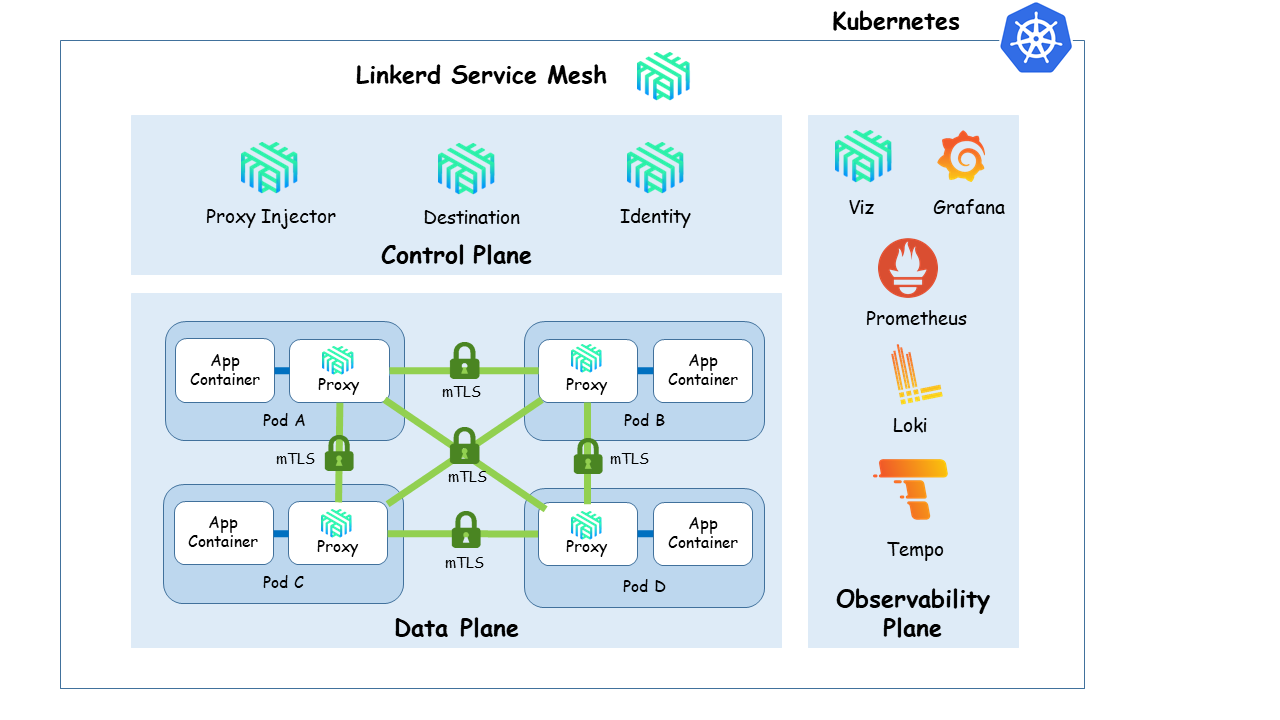
Look, I've been there. You installed Istio because "service mesh!" was the hottest thing in 2019. Fast forward to now and you're debugging why Istio's latest releases still use more CPU than your actual applications. Meanwhile, your teammate just showed you Linkerd's current resource usage graphs and you realized you've been Stockholm syndromed into thinking service meshes are supposed to suck this much.
The Istio Reality Check
Here's what nobody tells you about Istio: it's complicated as hell and burns resources like a crypto mining operation. I spent 6 months tuning Istio configs only to discover Linkerd typically shows 2-4x better latency with zero configuration tweaking. Not vendor marketing bullshit - actual benchmarks from teams who've done this migration.
The breaking point usually happens when:
- Your Envoy proxies are consuming more memory than your actual services
- You need to hire a dedicated "Istio engineer" just to keep the mesh running
istioctl proxy-configbecomes your most-used command afterkubectl get pods- Your monthly AWS bill shows Istio control plane eating 30% of your cluster resources
- You spend 2 hours debugging why
UPSTREAM_CONNECT_ERRORmeans your DestinationRule has a typo
For us, the breaking point was when Envoy ate 12GB of RAM during Black Friday and nobody knew why. Turned out some genius had enabled access logging to stdout on every proxy, and the log volume was causing memory leaks. We only discovered this at 2am when payments went down and I had to explain to the CEO why our "zero-config service mesh" needed a dedicated engineer to babysit it.
Companies like Grab documented their mesh evolution - though they went FROM Consul TO Istio, not the other direction. Point is, everyone's changing meshes because none of them got it right the first time.
Migration Approaches That Don't Suck
Forget the vendor whitepapers about "seamless transitions" - here's what actually works in production:
The Gradual Namespace Migration (Safest)
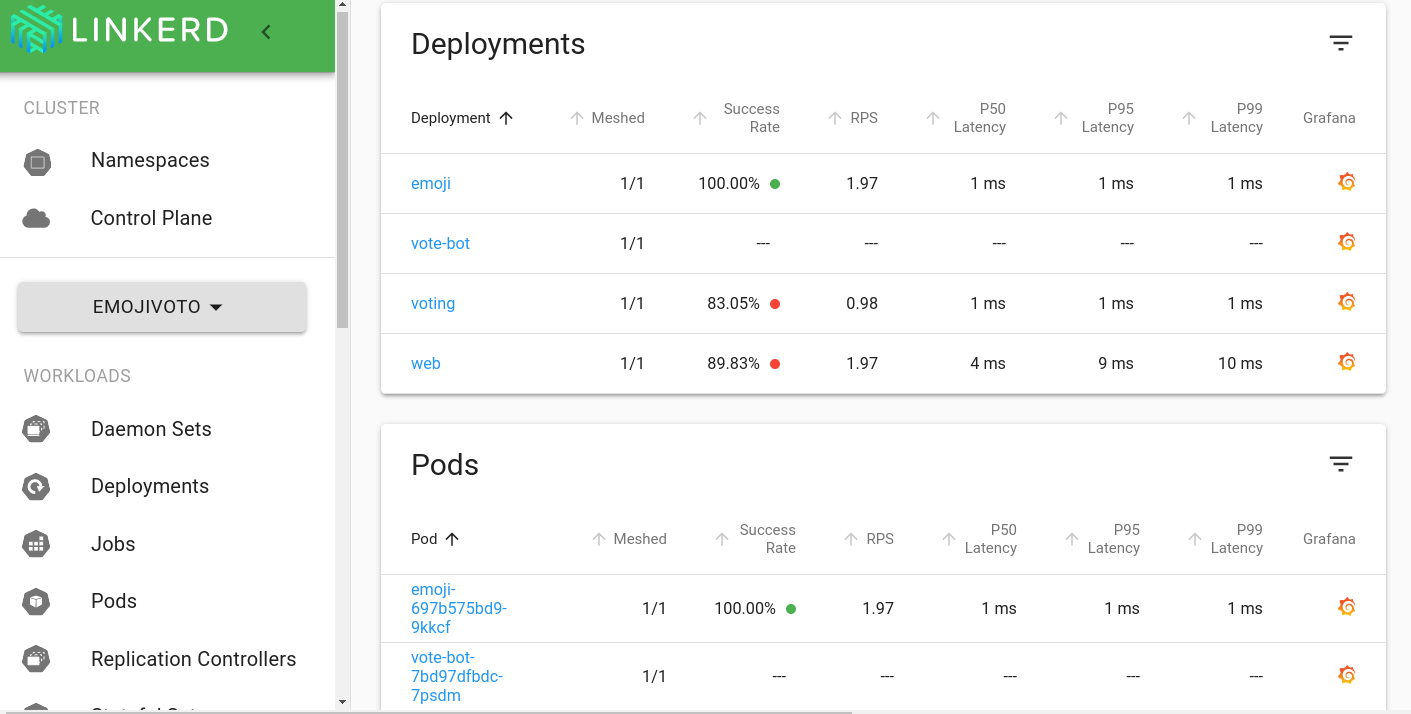
Start with your least critical services. Pick a development namespace, install Linkerd alongside Istio, and watch how much simpler everything becomes. Your monitoring dashboards will show the difference immediately - Linkerd's built-in observability actually makes sense without requiring a Grafana PhD.
The New Cluster Approach (Most Common)
Spin up new clusters with Linkerd and migrate services during your next deployment cycle. This lets you run both meshes in parallel without the nightmare of trying to make them play nice in the same cluster. Cross-cluster communication works through standard Kubernetes networking - no special mesh federation bullshit required.
The Big Bang Migration (For the Desperate/Insane)
Shut down Istio Friday at 6pm, install Linkerd, spend your weekend fixing all the shit that breaks. Works great until you discover at 2am that your payment service has some weird Envoy dependency nobody documented. Only do this if Istio is already broken so badly that "definitely broken for 48 hours" is better than "maybe broken randomly."
What Nobody Mentions About Resource Usage


Envoy proxies are memory hogs - we're talking at least 40MB per pod, sometimes way more. Scale that to 100 services and you're looking at gigs of RAM just for sidecars. Linkerd's proxy? Uses like a tenth of that.
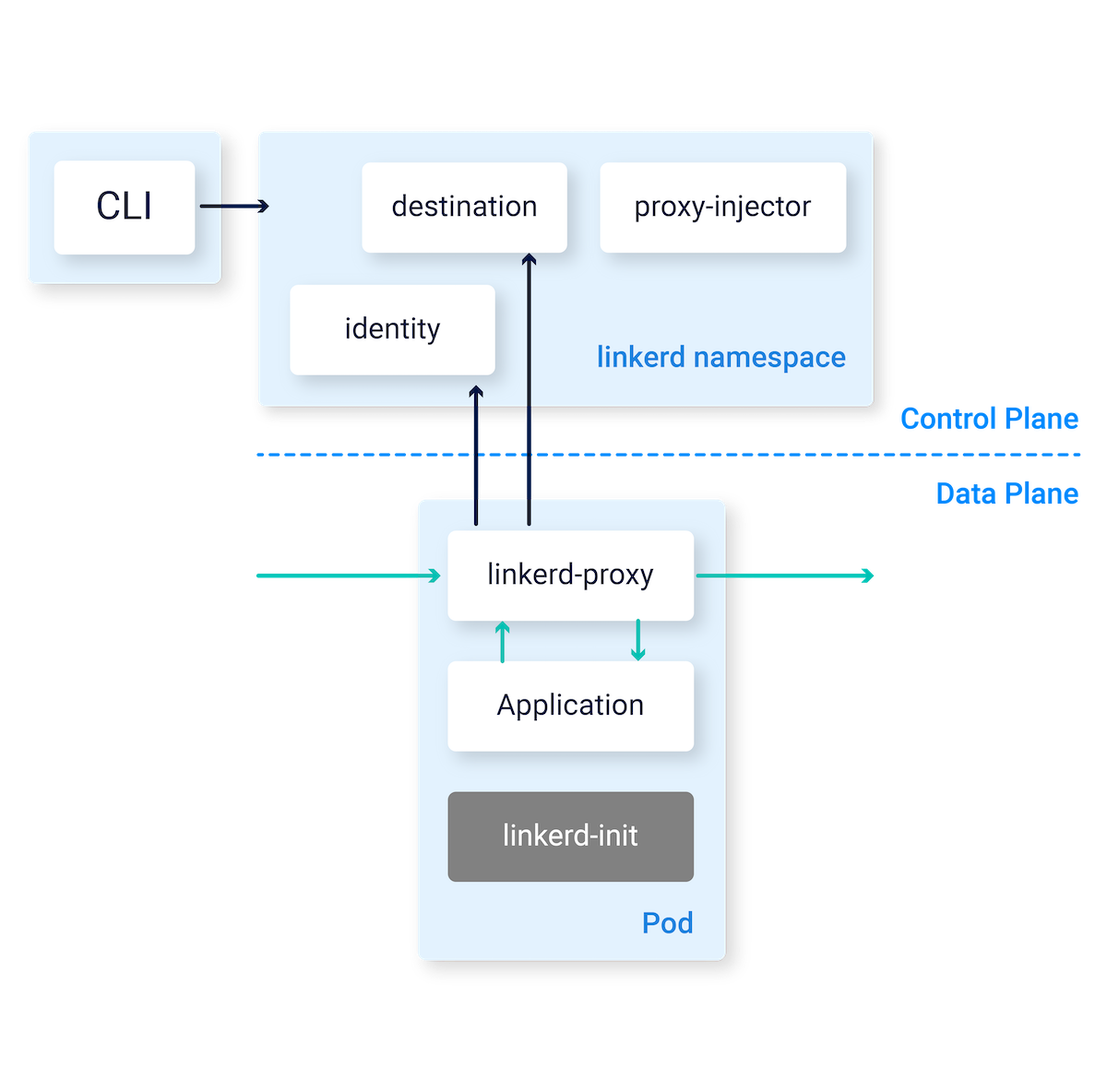
That's not an improvement, that's a completely different approach to resource efficiency. In our production clusters, we went from ~4GB for Istio down to under 1GB total for Linkerd on the same workloads.
Security Gotchas Everyone Hits
Both meshes do mTLS, but the certificate management is completely different. Istio uses Citadel (now called istiod) with its own CA that you probably never configured properly. Linkerd uses automatic certificate rotation that just works out of the box.
The migration pain point: your existing network policies assume Istio's certificate structure. I learned this the hard way when half our services started throwing x509: certificate signed by unknown authority errors after migration. Plan to rewrite your NetworkPolicies because the trust boundaries change completely. Also, if you're on Kubernetes 1.25+, PodSecurityPolicies are deprecated anyway so you'll be dealing with that shit too.
Observability: From Hell to Heaven
Istio's observability requires Prometheus, Grafana, Jaeger, and Kiali just to see what's happening. Each tool needs its own configuration, storage, and maintenance. When something breaks, you need to check four different dashboards to figure out which component is lying to you.
Linkerd ships with a built-in dashboard that actually shows useful information. No more spending 3 hours trying to figure out why Jaeger says everything is fine but users are getting 500s. It uses OpenTelemetry standards so your existing Datadog/New Relic setup doesn't completely shit itself during migration.
Configuration Translation Hell
Converting Istio VirtualServices to Linkerd's Gateway API resources is like translating Shakespeare into text message format - technically possible but you lose all the nuance and half of it breaks.
Real example that took me 3 hours to debug:
## This Istio config worked fine (somehow)
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
spec:
http:
- match:
- headers:
end-user:
exact: jason # Yeah this is terrible user routing but it was there when I started
route:
- destination:
host: reviews
subset: v2 # Don't ask me what v1 does, nobody knows
Becomes this mess in Gateway API:
## This breaks in subtle ways with Linkerd (took me 6 hours to figure out why)
apiVersion: gateway.networking.k8s.io/v1beta1
kind: HTTPRoute
spec:
rules:
- matches:
- headers:
- name: end-user
value: jason # The header matching works differently than Istio for some reason
backendRefs:
- name: reviews-v2 # Had to create a separate service because subset routing doesn't exist
The header matching works differently, subset routing doesn't exist, and you'll spend a day figuring out why 10% of your traffic disappears into the void.
The Timeline Reality
Vendor docs say 2-4 weeks. Reality? Plan for 8-12 weeks minimum if you actually want to sleep at night. Add another month if compliance is involved. Add another month when you discover your auth service has hardcoded Envoy dependencies nobody documented.
Every migration is a shitshow in its own special way, but here's what usually happens: First month you're optimistic and think this will be easy. Second month reality hits and everything takes 3x longer than expected. Third month is just fixing all the stupid stuff you broke trying to go fast. Fourth month is explaining to management why the "simple migration" is now 3 months overdue and the budget is shot.
Something always breaks during the migration, usually when you least expect it. Certificate rotation or service discovery issues seem to love happening right when you think everything's working.
The upside? Once you're done, you'll never want to touch Istio again. Linkerd just works, uses reasonable resources, and doesn't require a dedicated engineer to keep it running.
Useful shit when things break:
- Kubernetes Network Policies - for when your services can't talk to each other
- Envoy docs - because you'll need to debug Istio's broken configs
- CNCF Service Mesh Landscape - to see what else you could migrate to next