Linkerd graduated from CNCF in July 2021, which means it's supposedly production-ready. In practice, it's one of the few service meshes that doesn't make you want to throw your laptop out the window.
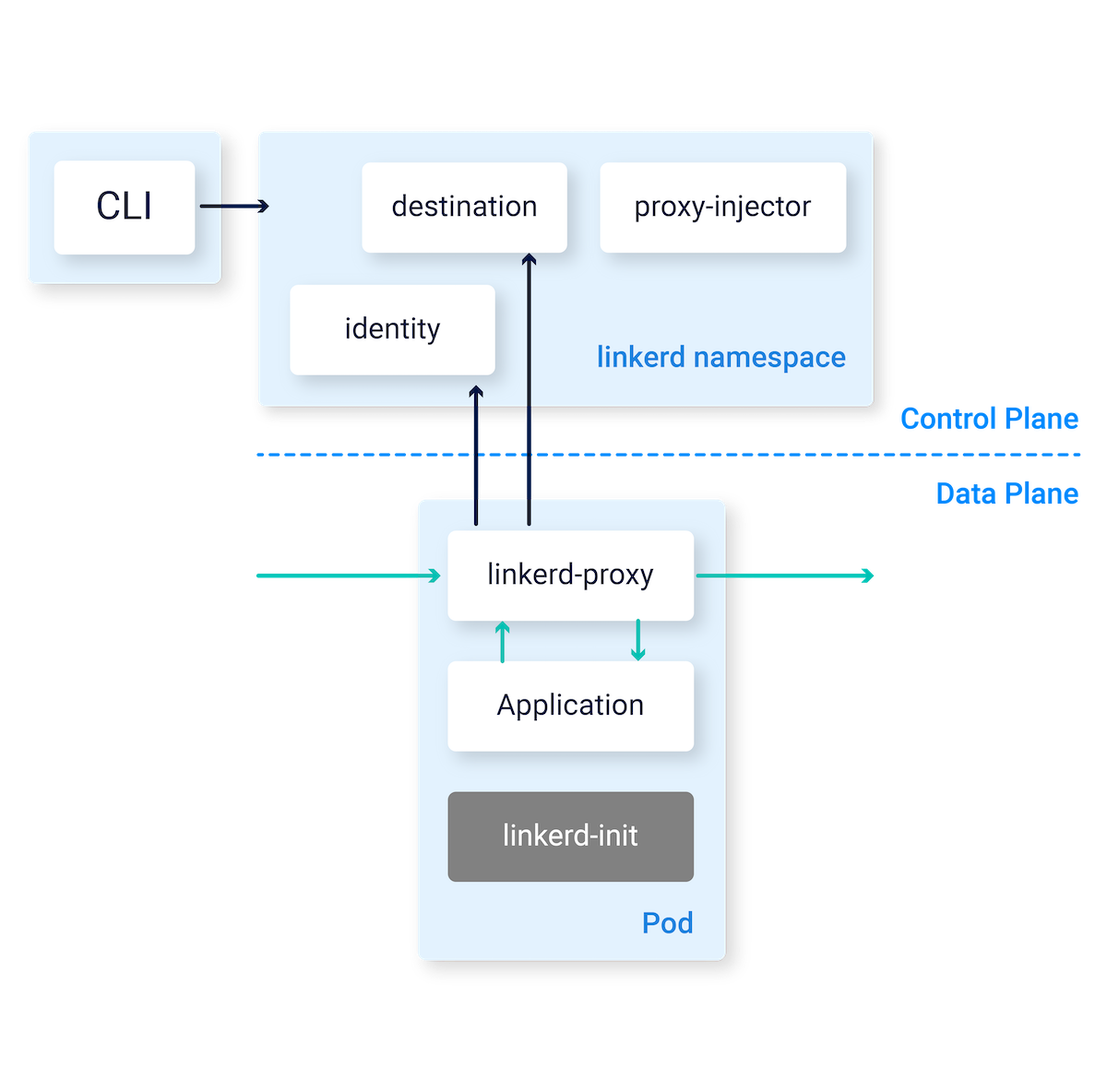
Core Components
Data Plane: The Rust proxy actually works as advertised. Uses about 10MB of RAM per pod instead of Istio's 50MB+, and you'll notice the difference when you're running hundreds of pods.
Control Plane: Runs in the linkerd namespace and usually stays out of your way. Takes about 200MB total, which is reasonable compared to other control planes that seem designed to consume all available memory.

The Good Stuff
mTLS happens automatically, which is nice because nobody has time to configure certificate chains manually. The certs rotate every 24 hours, and about 4 times a year something goes wrong and all your services stop talking to each other for 20 minutes.
All the metrics you actually need - request rate, error rate, latency. The dashboard is pretty but slow as hell with lots of services.
Load balancing that actually works with EWMA and circuit breaking. Unlike some meshes that seem to randomly distribute traffic and call it "load balancing."
Multi-cluster support got better in version 2.18 (April 2025). Still requires actual networking knowledge, which eliminates about 80% of the people who attempt it.
Gateway API support is there if you're into that sort of thing. Fewer YAML conflicts than the old ingress controller wars.
Protocol detection figures out if you're using HTTP, gRPC, or TCP without you having to annotate every damn service. Though you'll still end up explicitly declaring protocols when things get weird.
Performance Reality

The proxy adds about 0.5ms latency on P50, more when your network is shit. Still way better than Istio's "let me think about that for 10ms" approach.
Uses 8-15MB per sidecar, which adds up fast if you have hundreds of pods. But it's still better than alternatives that seem designed to consume all available RAM just because they can.
The Annoying Parts
Kubernetes version hell: Check the compatibility matrix or spend your weekend debugging weird API errors. Edge K8s versions break Linkerd in creative ways.
RBAC nightmare: You need cluster-admin or it won't work. linkerd check --pre will tell you this, but only after you've already wasted 30 minutes trying to install it with insufficient permissions.
Certificate rotation breaks randomly and you'll spend your weekend fixing it. I spent a Saturday morning debugging a cert rotation failure that took down our entire staging environment. The error logs were completely useless - just "TLS handshake failed" over and over. Monitor the certs or prepare to get paged at 2am.
Dashboard is pretty but useless at scale. Over 200 services and it becomes slower than Internet Explorer. Use Grafana instead.
Windows support exists but is labeled "preview" for a reason. Stick with Linux nodes unless you enjoy debugging unsolved problems


