Why Everyone's Doing Microservices (And Why You Probably Shouldn't)
Everyone's jumping on the microservices bandwagon because Netflix does it, so clearly your ecommerce site with 3 users needs the same architecture. Here's the dirty truth: microservices solve scaling problems by creating operational complexity problems. Martin Fowler's famous article outlines the trade-offs, but most people skip the warnings and dive straight into the chaos.
![]()
You'll trade the simplicity of a monolith for the excitement of:
- Debugging network calls that randomly timeout (usually at 3am during peak traffic)
- Service discovery that discovers everything except the service you actually need
- Distributed transactions that are about as reliable as a chocolate teapot
- Logs scattered across 47 different services when something breaks - good luck finding the root cause
The Hard Requirements Nobody Mentions
Before you dive into this rabbit hole, here's what you actually need (not the bullshit marketing version):
Development Tools (That Will Randomly Break):
- Latest Docker Desktop - it'll break anyway, but at least get the newest broken version. Docker Desktop randomly stops working and nobody knows why
- kubectl - the CLI tool that will mysteriously lose connection to your cluster at the worst possible moment
- Recent Node.js (20+) - Node 20+ is more stable than earlier versions that had weird container-related bullshit
- Git - you'll need this to track which exact commit broke everything and made your weekend disappear
System Resources (More Than You Think):
- 16GB RAM minimum because Kubernetes will eat all of it for breakfast
- 100GB free space — container images are fucking huge and Docker never cleans up after itself
- Patience of a saint since you'll be debugging YAML for hours
Real Prerequisites Nobody Talks About:
- Experience debugging production at 3am — learned the hard way when our payment service died on Black Friday
- High tolerance for Docker Desktop shitting the bed every time macOS updates
- Understanding that Kubernetes error messages were written by sadists who despise developers
- Acceptance that your "highly available" setup will go down like a house of cards in a hurricane
What Actually Happens When You Deploy
Docker is supposed to solve the "works on my machine" problem, but now you get "works in my container" instead. Works great until it doesn't, then you spend 2 hours trying to figure out why the exact same image won't start.
Kubernetes promises to handle all the orchestration, but in reality you'll spend more time debugging Kubernetes than writing actual code. The official docs are completely useless when things break at 3am, which they always do - usually right when you're trying to sleep or during the most important demo of your career.
What Your Architecture Actually Looks Like:
Our setup looks nothing like those bullshit architecture diagrams:
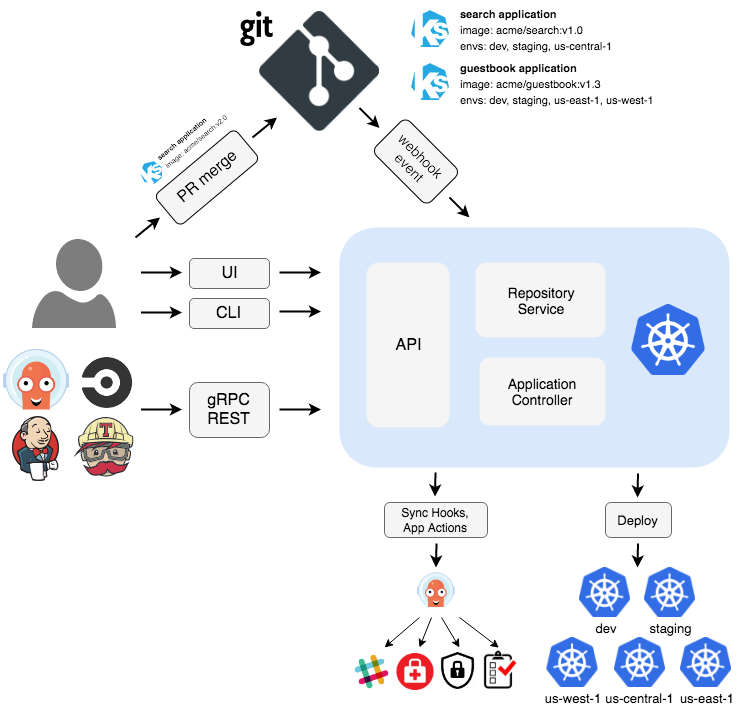
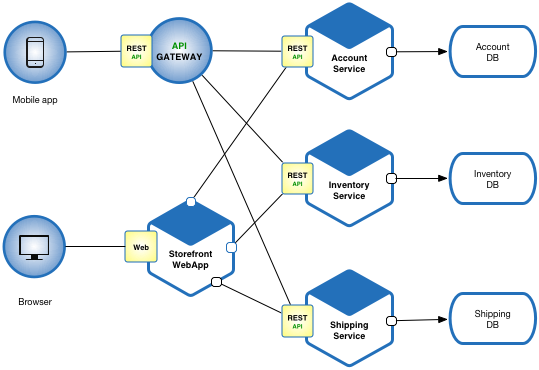
- Service Layer: 12 microservices where 3 are critical, 6 do jack shit, and 3 nobody remembers creating (probably from that intern last summer)
- API Gateway: Single point of failure masquerading as high availability - went down for 4 hours last month during peak traffic because fuck our users, right?
- Service Mesh: We added Istio thinking we were smart and somehow made everything 400ms slower - took me 6 hours to figure out the mesh was the problem
- Data Layer: 12 different databases because some $300/hour consultant said "database per service" - now we have 12 different ways for backups to fail
- Monitoring: Grafana dashboards cheerfully show green while customers are rage-tweeting about not being able to log in
Budget 2 weeks to get this working, 2 months to make it not suck. The learning curve is steeper than climbing Everest with no oxygen.
But you're here anyway, so let's get this disaster started. Now that you understand what you're getting into, let's start with the actual implementation. First up: setting up your development environment and building your first microservice that will inevitably break in spectacular ways.