Cache Selection:
Technical Requirements Drive DecisionsCaching solutions solve different problems. Redis 8.2.1 (August 2025) focuses on bug fixes with moderate update urgency. Memcached 1.6.39 (July 2025) continues stable evolution. Hazelcast 5.5.0 remains the distributed computing platform.## Redis:
Multi-Structure Data Store Redis 8.2.1 addresses key stability issues that have been fucking with production deployments:
Redis 8.2.1 addresses key stability issues that have been fucking with production deployments:
- CVE-2025-32023:
Fixed out-of-bounds write in HyperLogLog commands (this one took down our analytics cluster)
- XADD/XTRIM crash after RDB loading resolved (error: "WRONGTYPE Operation against a key holding the wrong kind of value")
- Active Defrag disabled during replica flushing (learned this the hard way when defrag killed our read replicas)The Redis data types include strings, lists, sets, sorted sets, hashes, streams, and Hyper
LogLogs.
Each structure has specific memory overhead patterns. Hash data types use approximately 40% more memory than equivalent JSON serialization, but provide atomic field operations.Memory fragmentation becomes problematic with frequent key expiration and will fuck your weekend. Monitor INFO memory output for mem_fragmentation_ratio values above 1.5. When ratio exceeds 2.0 (mine hit 3.7x during Black Friday), consider enabling active defragmentation but prepare for performance degradation during defrag cycles:bashCONFIG SET activedefrag yesCONFIG SET active-defrag-ignore-bytes 100mbCONFIG SET active-defrag-threshold-lower 10Redis clustering requires careful shard distribution planning.
The Redis Cluster uses hash slots (16384 total) distributed across nodes.
Resharding operations lock affected slots, potentially causing application timeouts during rebalancing.## Memcached: Simple Key-Value Store**Memcached Architecture:
Client-Server Simplicity**Memcached follows a straightforward client-server model where multiple clients connect to independent Memcached servers. Each server maintains its own hash table in memory, with no inter-server communication or clustering logic.Memcached 1.6.39 (July 28, 2025) provides incremental improvements to the core caching functionality. The BSD license allows unrestricted commercial use.
The architecture centers on a simple hash table with network access layer.
Memcached implements pure key-value storage with LRU (Least Recently Used) eviction. No data persistence, no complex data structures, no clustering coordination. The protocol specification supports text and binary modes for client communication.
Key operational characteristics:
- Memory overhead: approximately 5% above stored data size
- Network protocol:
TCP with optional UDP support
- Eviction: LRU algorithm when memory limit reached
- Concurrency: thread-per-connection modelThe performance tuning involves basic configuration parameters:```bashmemcached -m 64 -p 11211 -t 4 -c 1024# -m: memory limit (MB)# -p:
TCP port# -t: worker threads# -c: max simultaneous connections```## Hazelcast:
Distributed Data Platform Hazelcast 5.5.0 (July 2024) represents the current stable community release.
Hazelcast 5.5.0 (July 2024) represents the current stable community release.
The Community Edition uses Apache 2.0 licensing with practical limitations: maximum 2 cluster members for production deployment.
Commercial licensing required for larger clusters.The architecture implements a distributed data grid with automatic partitioning, replication, and fault tolerance.
Key components include:
- Data partitioning: 271 partitions distributed across cluster members
- Backup management:
Configurable backup counts for fault tolerance
- Discovery mechanisms: Multicast, TCP/IP, cloud provider integration
- Split-brain protection:
Quorum-based cluster consistencyHazelcast extends beyond caching to provide distributed computing capabilities:
- IMap:
Distributed hash map with near-cache support
- IQueue: Distributed queue implementation
- IExecutorService:
Distributed task execution
- Event streaming: Real-time data processing pipelinesThe clustering setup requires careful network configuration and will make you question your life choices.
Common discovery issues that destroyed my deployment timeline:
- Firewall blocking discovery ports (typically 5701-5703)
- took 3 hours to figure out corporate security was silently dropping packets
- Docker networking isolation preventing member communication
- bridge networks don't work, had to use host networking
- Kubernetes service mesh interfering with cluster protocols
- Istio intercepts everything and breaks discovery with error "Unable to connect to any address in the config"JVM memory management affects performance significantly.
The memory configuration requires tuning garbage collection for distributed data access patterns.
Typical settings for production deployment:```bash-Xmx8g -Xms8g-XX:+UseG1GC-XX:
MaxGCPauseMillis=200-XX:+UnlockExperimentalVMOptions```## Selection Criteria Based on RequirementsChoose caching solutions based on technical requirements rather than feature marketing:Memcached for simple key-value caching:
Session storage, page caching, API response caching
Predictable performance and memory usage patterns
Teams prioritizing operational simplicityRedis for structured data and complex operations:
Leaderboards (sorted sets), rate limiting (counters), pub/sub messaging
Applications requiring atomic operations on data structures
Teams comfortable managing memory fragmentationHazelcast for distributed computing workloads:
Multi-region data synchronization requirements
Distributed processing and computation grids
Enterprise environments with dedicated platform teams
The decision comes down to matching tool complexity to actual requirements.
Memcached's boring predictability beats Redis's fancy features when you just need fast key-value storage. Redis justifies its memory overhead when you need atomic operations on complex data structures. Hazelcast makes sense for distributed computing workloads where you'd otherwise build your own clustering layer.Don't fall for feature envy. Pick the tool that matches your team's operational maturity and sleep schedule preferences.**Now that you understand what each tool actually does, let's dig into the feature matrix and see how they stack up against each other on paper
- before we get to the performance reality check that'll save you from making expensive mistakes.**
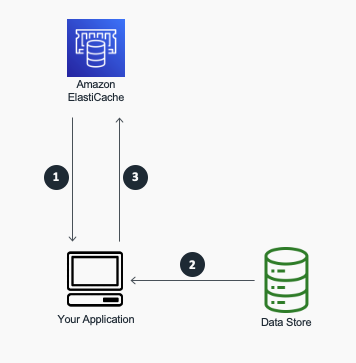
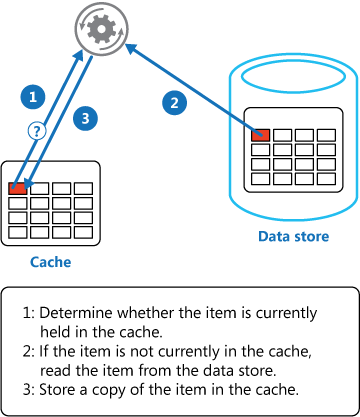 Redis Cluster distributes data across multiple nodes using hash slots.
Redis Cluster distributes data across multiple nodes using hash slots.
Each key maps to one of 16384 slots, distributed among cluster members. The Cache-Aside pattern shows how applications typically interact with Redis for optimal performance.Hazelcast implements automatic data partitioning with configurable backup strategies for fault tolerance.