Here's the deal - I've been running event-driven systems in production for 3 years, and this combo is the only thing that doesn't make me want to quit programming.
The Problem with Everything Else
Event sourcing logs every change as an event. That's your audit trail and your source of truth. Sounds simple until you try to build it in production.
Every other event sourcing setup I've tried either:
- Lost events when Kafka decided to take a nap (goodbye customer orders)
- Had workflows that died mid-process and never recovered (hello manual cleanup scripts)
- Required a PhD in distributed systems just to debug why shit stopped working
Temporal keeps your workflows alive no matter what breaks. Redis Streams are fast as hell and don't require a Kafka PhD to operate. Put them together and you get event sourcing that actually works.
What This Architecture Actually Does

Event-driven architecture enables decoupled microservices to communicate through events - this is the foundation pattern we're building on.
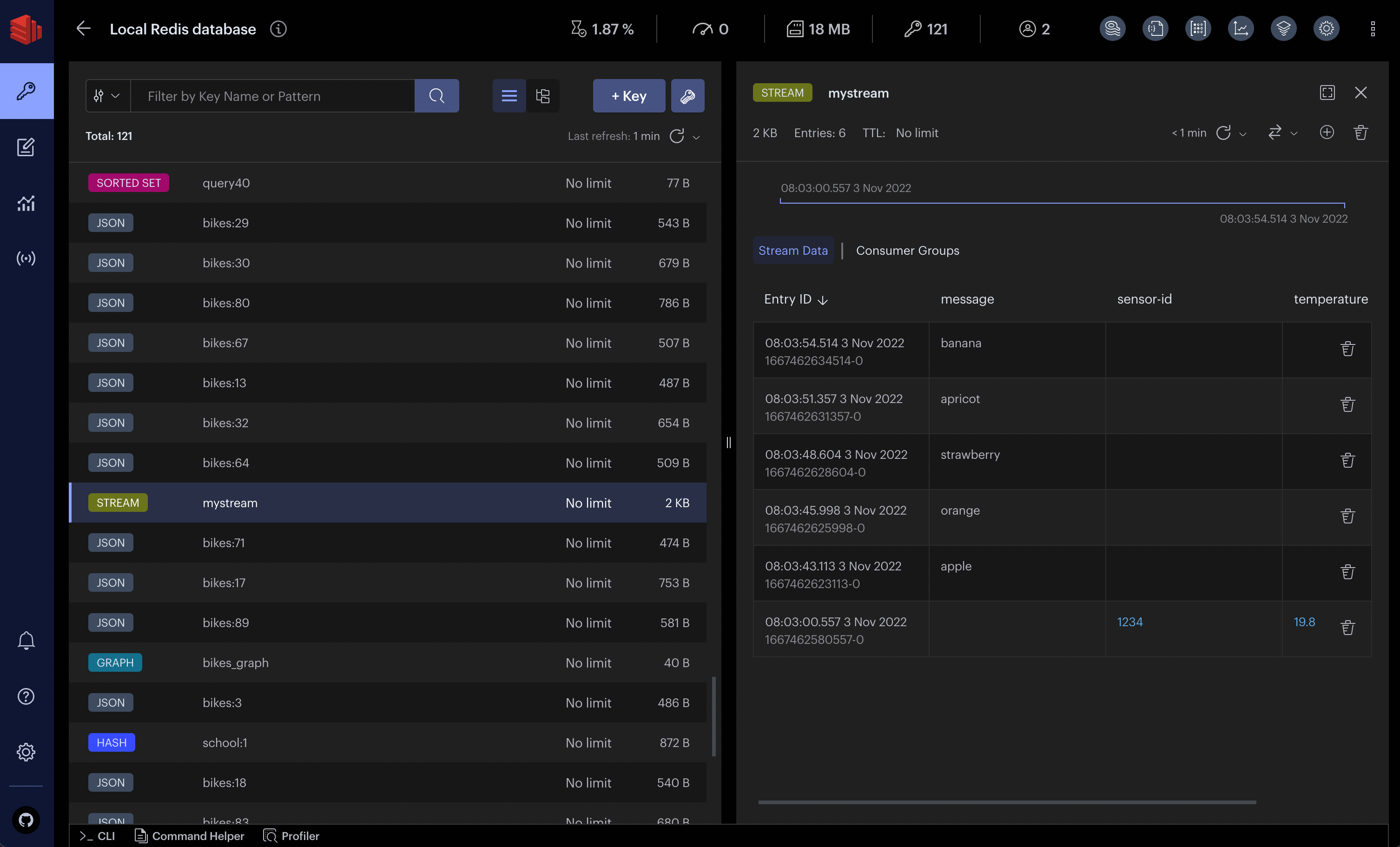
Redis Streams store your events - every user click, payment, order update, whatever. They're basically append-only logs that Redis manages for you. No manual partitioning bullshit, no dealing with consumer group rebalancing nightmares.
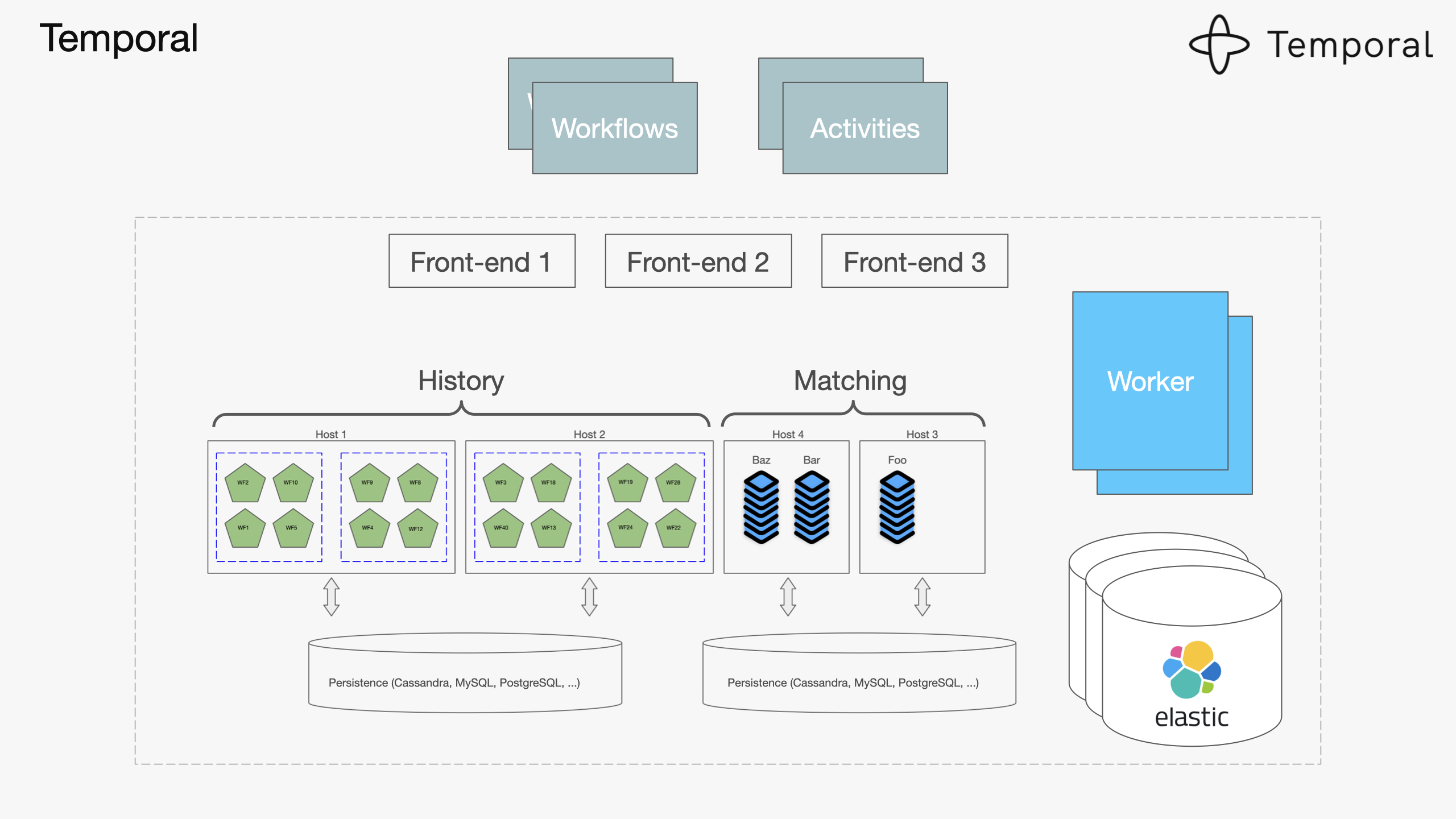
Temporal workflows coordinate the business logic. When an order comes in, the workflow ensures payment processing, inventory checks, and shipping notifications all happen in the right order - even if your payment service decides to timeout for 10 minutes. The money transfer example shows this pattern in action.

This diagram shows how Temporal workflows handle compensating actions when things go wrong - critical for event sourcing systems that need to maintain consistency.
I learned this during our Black Friday clusterfuck. Our old system lost a bunch of orders when the payment service shat itself for like 10 minutes. I think it was around 800 orders? Expensive lesson. With Temporal, workflows just pause and resume when services come back up. No lost orders, no manual reconciliation scripts at 3am.
Real Benefits (Not Marketing Bullshit)
Things Don't Stay Broken: Temporal workflows retry failed operations until they work. No more "oh shit, the payment went through but we never sent the email" scenarios.
You Can Actually Debug Problems: Redis Streams keep every event with timestamps. Temporal Web UI shows you exactly where workflows are stuck. No more guessing what went wrong.
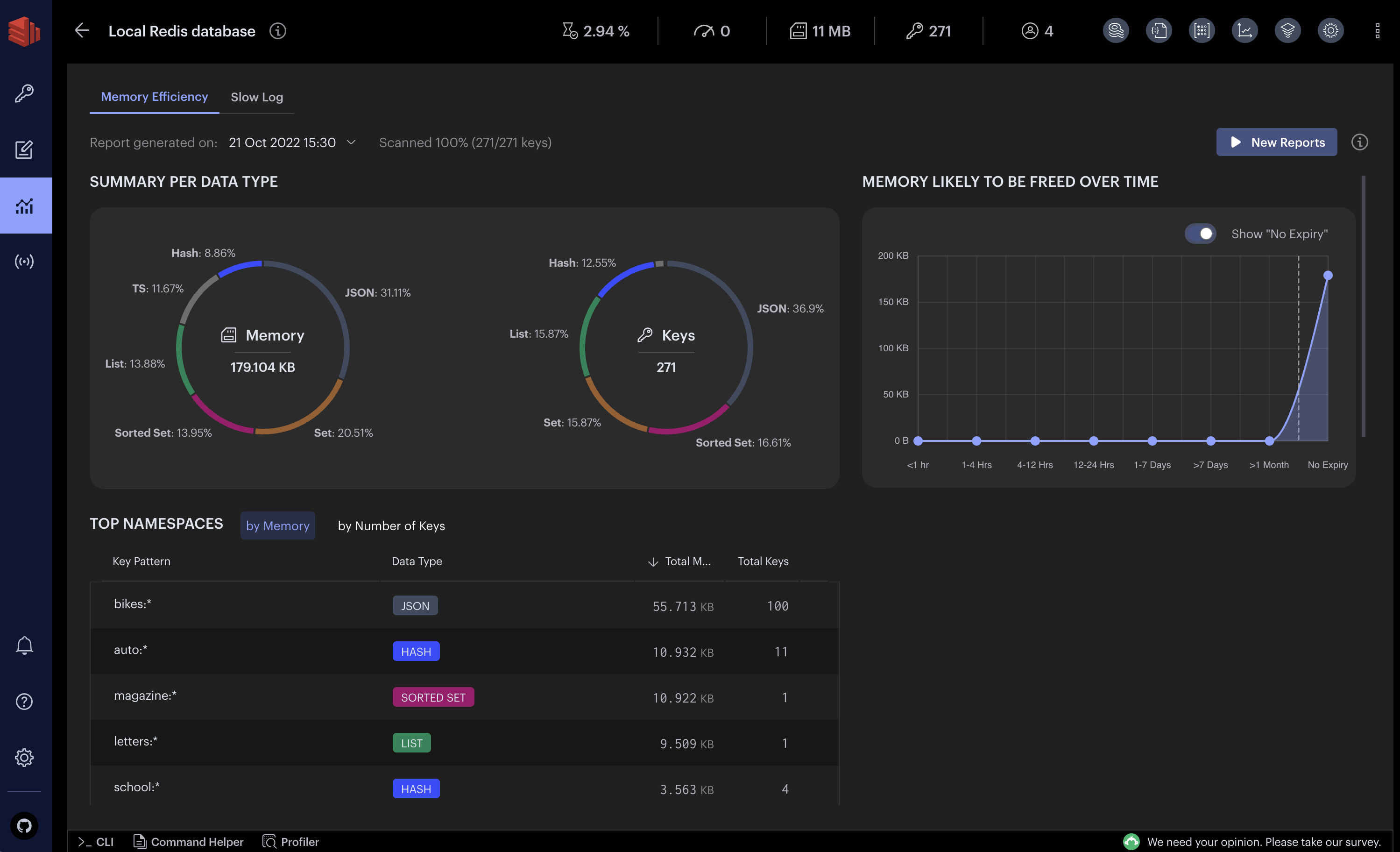
Scales Without Hiring a Platform Team: Redis consumer groups handle parallel processing. Temporal workers scale horizontally. We went from 1K to 50K daily orders without touching the architecture.
Event Replay Actually Works: Need to test new business logic? Replay events from last week. Fixed a bug? Reprocess the affected events. This saved my ass when we discovered a pricing calculation bug that affected 12K orders. The continue-as-new pattern is perfect for this.
That's the theory anyway. Now let me show you how to actually build this without losing your sanity.