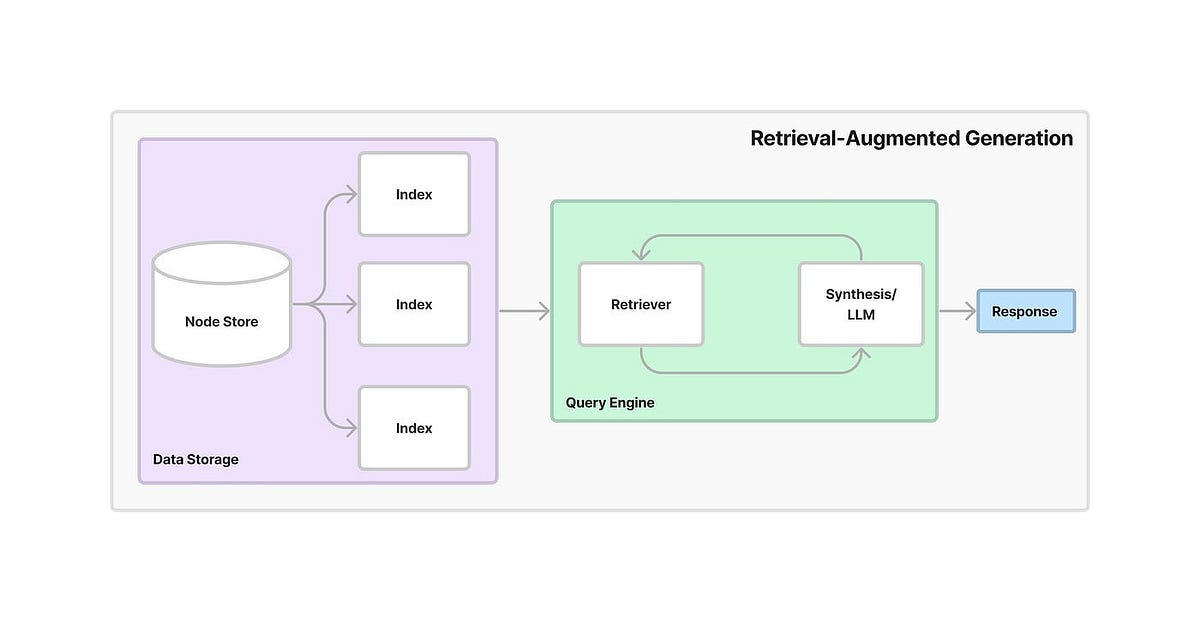
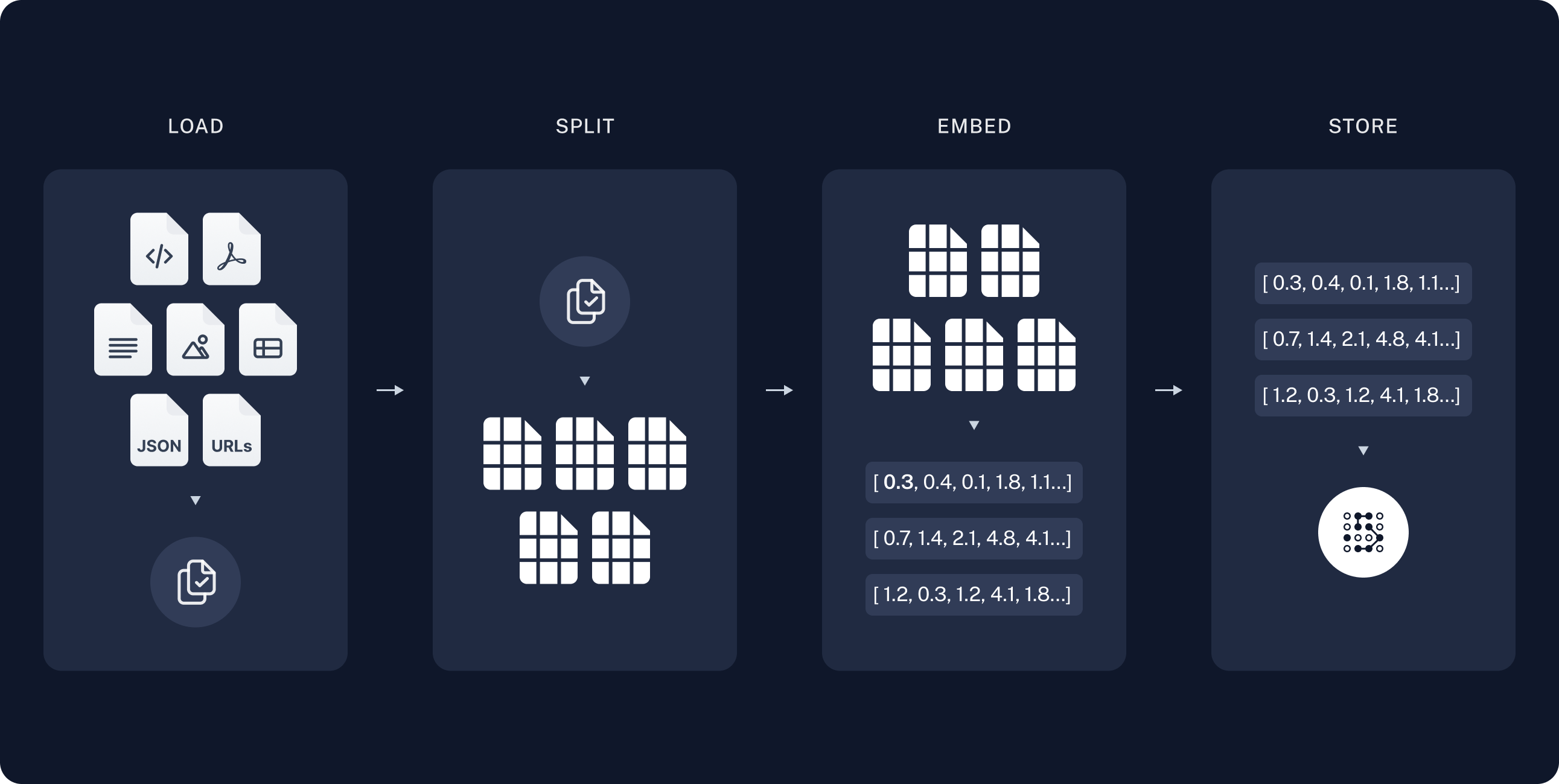
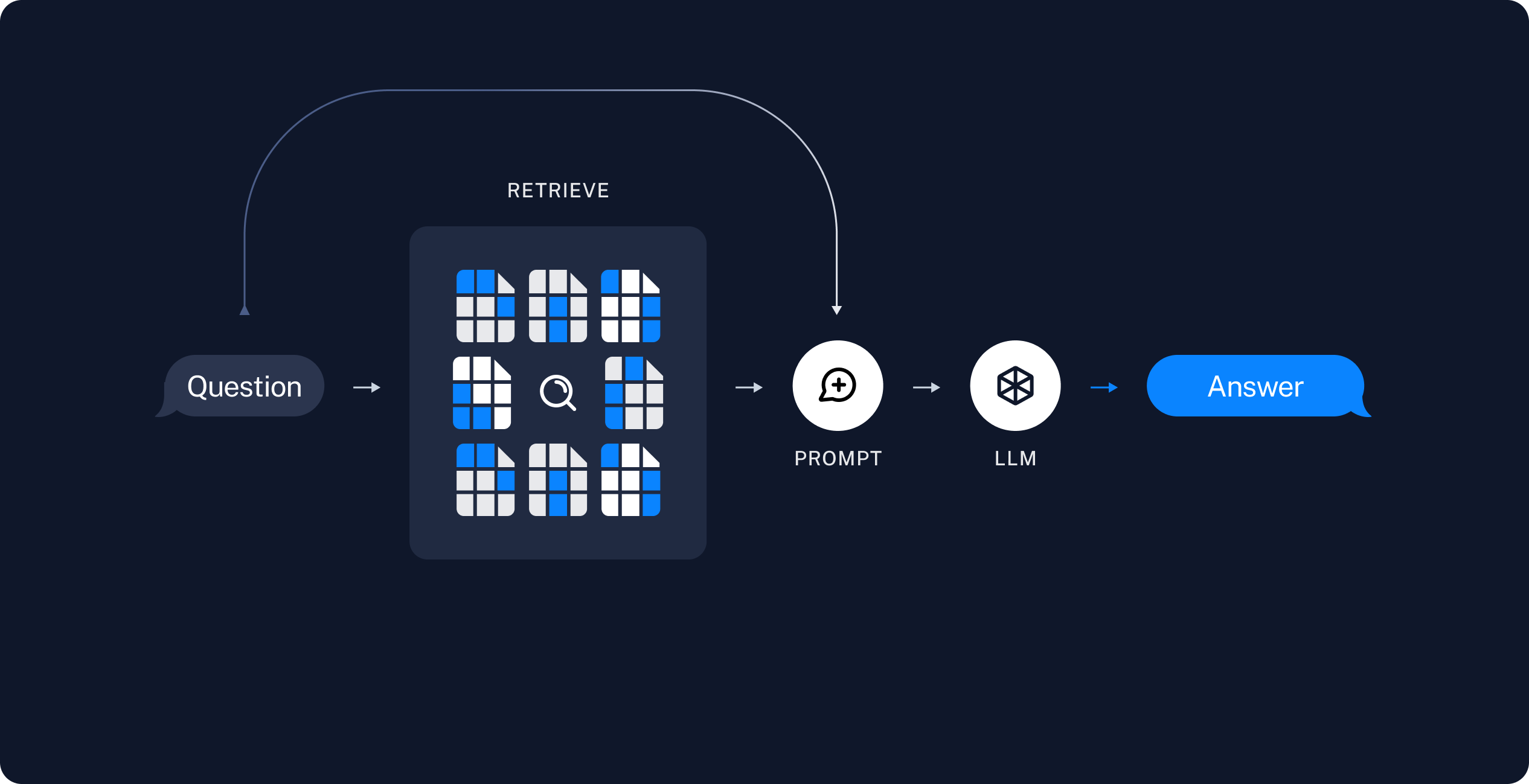
Local RAG in production breaks in creative ways. Eight months of running this and I still find new failure modes. Here's the shit that'll bite you at 3AM.
Common Production Failures and Solutions
GPU Memory Exhaustion (The Silent System Killer)
Ollama crashes with "connection error" when it runs out of VRAM. No helpful details, just dead silence. Took me way too long to figure this out the first time - spent two hours checking network configs before realizing the GPU was maxed out.
import torch
import logging
def monitor_gpu_memory():
"""Production GPU memory monitoring"""
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
memory_reserved = torch.cuda.memory_reserved(i)
memory_allocated = torch.cuda.memory_allocated(i)
memory_free = memory_reserved - memory_allocated
utilization = (memory_allocated / memory_reserved) * 100
if utilization > 90:
logging.critical(f"GPU {i} memory critical: {utilization:.1f}%")
elif utilization > 75:
logging.warning(f"GPU {i} memory high: {utilization:.1f}%")
return {
'device': i,
'utilization_percent': utilization,
'free_bytes': memory_free
}
## Implement automatic model unloading
class ModelManager:
def __init__(self):
self.last_used = {}
self.models = {}
self.max_idle_time = 300 # 5 minutes
def get_model(self, model_name):
if model_name not in self.models:
self.models[model_name] = self._load_model(model_name)
self.last_used[model_name] = time.time()
self._cleanup_idle_models()
return self.models[model_name]
def _cleanup_idle_models(self):
current_time = time.time()
idle_models = [
name for name, last_used in self.last_used.items()
if current_time - last_used > self.max_idle_time
]
for model_name in idle_models:
logging.info(f"Unloading idle model: {model_name}")
del self.models[model_name]
del self.last_used[model_name]
torch.cuda.empty_cache()
ChromaDB Collection Corruption (The Data Vanishing Act)
ChromaDB corrupted my collection overnight once. Queries that worked Monday returned nothing Tuesday. No errors, no warnings, just an empty collection where 300k documents used to live. Back up your shit or learn this lesson like I did.
import chromadb
import sqlite3
import shutil
from datetime import datetime
def backup_chromadb_collection(collection_name, backup_path):
"""Production-grade ChromaDB backup strategy"""
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
backup_dir = f"{backup_path}/chromadb_backup_{timestamp}"
try:
# Stop accepting new writes
collection = client.get_collection(collection_name)
document_count = collection.count()
logging.info(f"Backing up {document_count} documents from {collection_name}")
# Export collection data
all_data = collection.get(include=['documents', 'metadatas', 'embeddings'])
# Create backup archive
backup_data = {
'collection_name': collection_name,
'document_count': document_count,
'timestamp': timestamp,
'data': all_data
}
with open(f"{backup_dir}/collection_backup.json", 'w') as f:
json.dump(backup_data, f)
logging.info(f"Backup completed: {backup_dir}")
return backup_dir
except Exception as e:
logging.error(f"Backup failed: {e}")
return None
def restore_chromadb_collection(backup_path, new_collection_name):
"""Restore from backup during corruption recovery"""
try:
with open(f"{backup_path}/collection_backup.json", 'r') as f:
backup_data = json.load(f)
# Create new collection
collection = client.create_collection(new_collection_name)
# Restore data in batches
data = backup_data['data']
batch_size = 1000
for i in range(0, len(data['documents']), batch_size):
batch_docs = data['documents'][i:i+batch_size]
batch_metas = data['metadatas'][i:i+batch_size]
batch_embeddings = data['embeddings'][i:i+batch_size]
collection.add(
documents=batch_docs,
metadatas=batch_metas,
embeddings=batch_embeddings,
ids=[f"doc_{i+j}" for j in range(len(batch_docs))]
)
logging.info(f"Restored {len(data['documents'])} documents")
return True
except Exception as e:
logging.error(f"Restore failed: {e}")
return False
Ollama Service Management
Ollama services crash silently and don't automatically restart without proper systemd configuration. Production deployments require robust service management - study systemd best practices, service monitoring, and auto-restart strategies used by production services.
## /etc/systemd/system/ollama.service
[Unit]
Description=Ollama AI Service
After=network-online.target
Wants=network-online.target
[Service]
Type=exec
ExecStart=/usr/local/bin/ollama serve
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
Environment="OLLAMA_KEEP_ALIVE=24h"
User=ollama
Group=ollama
Restart=always
RestartSec=3
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=ollama
## Resource limits
LimitNOFILE=1048576
LimitNPROC=1048576
[Install]
WantedBy=multi-user.target
Enable automatic restarts and monitoring:
sudo systemctl enable ollama
sudo systemctl start ollama
sudo systemctl status ollama
## Monitor with journalctl
sudo journalctl -u ollama -f
Production Monitoring and Alerting
Local RAG systems need comprehensive monitoring because you control the entire stack. Cloud services provide built-in observability; local deployments require custom solutions. Check observability patterns, Prometheus setup guides, Grafana dashboards, and alerting strategies for production monitoring.
import psutil
import requests
import time
from prometheus_client import start_http_server, Gauge, Counter, Histogram
## Prometheus metrics
gpu_memory_usage = Gauge('gpu_memory_usage_bytes', 'GPU memory usage', ['device'])
cpu_usage = Gauge('cpu_usage_percent', 'CPU usage percentage')
chromadb_query_duration = Histogram('chromadb_query_duration_seconds', 'ChromaDB query duration')
rag_requests_total = Counter('rag_requests_total', 'Total RAG requests', ['status'])
class ProductionMonitoring:
def __init__(self):
# Start Prometheus metrics server
start_http_server(8090)
self.monitoring_active = True
def monitor_system_health(self):
"""Continuous system monitoring loop"""
while self.monitoring_active:
# CPU monitoring
cpu_percent = psutil.cpu_percent(interval=1)
cpu_usage.set(cpu_percent)
# Memory monitoring
memory = psutil.virtual_memory()
if memory.percent > 90:
self.send_alert("High memory usage", f"Memory at {memory.percent}%")
# GPU monitoring
self.monitor_gpu()
# Service health checks
self.check_service_health()
time.sleep(30) # Monitor every 30 seconds
def check_service_health(self):
"""Check if all services are responding"""
services = {
'ollama': 'http://localhost:11434/api/tags',
'chromadb': 'http://localhost:8000/api/v1/heartbeat'
}
for service, url in services.items():
try:
response = requests.get(url, timeout=5)
if response.status_code != 200:
self.send_alert(f"{service} unhealthy", f"Status code: {response.status_code}")
except requests.RequestException as e:
self.send_alert(f"{service} unreachable", str(e)")
def send_alert(self, title, message):
"""Send alerts to monitoring systems"""
alert_payload = {
'alert_type': title,
'message': message,
'timestamp': datetime.now().isoformat(),
'severity': 'warning'
}
# Send to Slack, email, or monitoring system
logging.critical(f"ALERT: {title} - {message}")
Docker Production Configuration
Production Docker deployments require careful resource allocation and restart policies. The standard Docker configurations fail under load.
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ./ollama_models:/root/.ollama
environment:
- OLLAMA_KEEP_ALIVE=24h
- OLLAMA_HOST=0.0.0.0
- OLLAMA_NUM_PARALLEL=4
- OLLAMA_MAX_QUEUE=512
deploy:
resources:
limits:
memory: 32G
reservations:
memory: 16G
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:11434/api/tags"]
interval: 30s
timeout: 10s
retries: 3
start_period: 60s
chromadb:
image: chromadb/chroma:latest
ports:
- "8000:8000"
volumes:
- ./chromadb_data:/chroma/chroma
- ./chromadb_backups:/backups
environment:
- CHROMA_SERVER_AUTHN_CREDENTIALS_FILE=/chroma/server.htpasswd
- CHROMA_SERVER_AUTHN_PROVIDER=chromadb.auth.basic_authn.BasicAuthenticationServerProvider
deploy:
resources:
limits:
memory: 8G
reservations:
memory: 4G
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/api/v1/heartbeat"]
interval: 30s
timeout: 10s
retries: 3
nginx:
image: nginx:alpine
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
- ./ssl:/etc/ssl/certs:ro
depends_on:
- rag-api
restart: unless-stopped
rag-api:
build:
context: .
dockerfile: Dockerfile.production
ports:
- "8080:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
- CHROMADB_HOST=chromadb
- CHROMADB_PORT=8000
- PYTHONUNBUFFERED=1
- LOG_LEVEL=INFO
depends_on:
ollama:
condition: service_healthy
chromadb:
condition: service_healthy
restart: unless-stopped
volumes:
- ./logs:/app/logs
Local RAG performance is unpredictable as hell. Query times range from 200ms to 30+ seconds depending on model load and document complexity. More hardware doesn't always help - learned that after throwing money at the problem.
## What actually helps with performance
def cache_frequent_queries():
# Redis cache saves your ass on repeated questions
import redis
cache = redis.Redis(host='localhost', port=6379, db=0)
def cached_query(question):
cache_key = f"rag:{hash(question)}"
cached = cache.get(cache_key)
if cached:
return json.loads(cached)
result = your_rag_query(question)
cache.setex(cache_key, 3600, json.dumps(result)) # 1 hour
return result
return cached_query
The Brutal Truth About Local RAG
Running local RAG sucks compared to cloud services. You're the monitoring team, backup specialist, scaling engineer, and the person who gets paged at 2AM when ChromaDB decides to corrupt itself again. It's exhausting.
The upside? Once it's working, you don't pay per query and your data stays put. No API bills, no rate limits, no wondering what OpenAI does with your proprietary docs.
Should you do this? If you're handling sensitive data at scale and know your way around servers, maybe. For prototypes or quick projects, just use OpenAI's API and save yourself the pain.
This setup has been running our Q&A system for 8 months. Still breaks occasionally but way cheaper than cloud APIs. Hardware investment pays off if you're processing serious volume.