LlamaIndex solves one specific problem: making your documents searchable without the usual embedding nightmare. Instead of building custom parsers for every document type and wrestling with vector databases, you get a framework that handles the tedious shit for you. Setup takes 2-3 days if you know what you're doing, longer if you don't.
The Real Problem: Most Document Parsers Are Garbage
Your company has thousands of PDFs, Word docs, and random files sitting around. Standard search sucks - try finding specific information in a 300-page compliance manual. Basic semantic search fails on technical documents with tables and diagrams. Building custom parsers takes months and breaks every time someone uploads a scanned PDF.
LlamaIndex handles this complete shitshow by parsing documents without you having to write custom code for every format. Claims to support 160+ formats via LlamaHub but realistically about 40-50 work reliably. PDFs with complex layouts are hit-or-miss. Scanned documents? Forget about it unless you preprocess with OCR tools first.
Budget 16GB+ RAM for anything serious - memory usage explodes with large document collections. Found this out the hard way when our staging server ran out of memory processing a 10,000 document corpus. Kubernetes kept killing pods with OOMKilled status and we couldn't figure out why until we watched htop during ingestion - RAM usage climbed from 2GB to 15GB in 20 minutes. Check the GitHub issues for similar experiences and memory optimization tips. Memory profiling with py-spy helps identify leaks, and chunking strategies matter more than you think. Batch processing limits also bite you - OpenAI's API chokes on more than 1000 concurrent embedding requests.
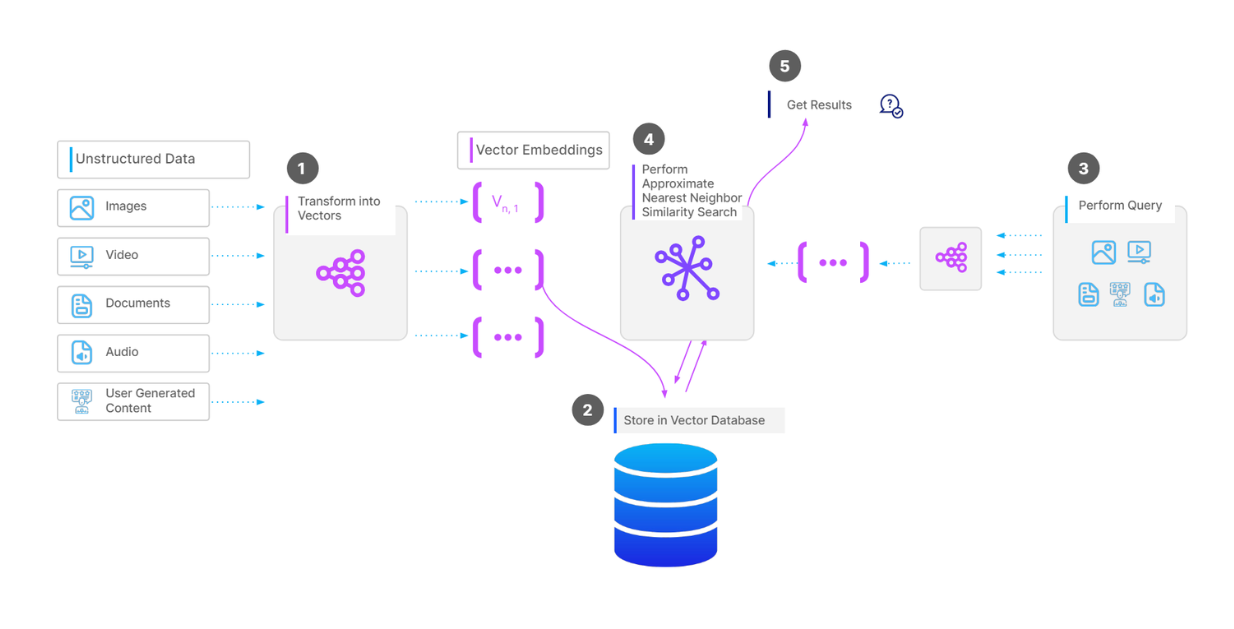
How It Actually Works (When It Works)
Three stages that sometimes work: ingest your docs, index them for search, query when users ask questions. The document readers do okay with clean PDFs but struggle with anything complex. Tables spanning pages? Good luck. Charts and diagrams? Usually get ignored or mangled.
Indexing creates different search strategies depending on what you need:
- Vector search using OpenAI embeddings - works well but expensive as hell. Expect $50-200/month in embedding costs for real use
- Keyword search using BM25 algorithms - faster but misses semantic meaning
- Hierarchical indexes - supposed to preserve document structure but breaks on malformed PDFs
- Knowledge graphs using NetworkX - cool in theory, unreliable with messy real-world documents
Pro tip: Start with vector search only. The hybrid approaches sound smart but add complexity you don't need until you're processing millions of documents. Check Pinecone's RAG guide for fundamentals.

Got a specific error during indexing? ECONNREFUSED when connecting to vector database usually means your Pinecone API key is wrong or the service is down. The async connection pool helps but you still need proper retry logic with exponential backoff for production.
Performance: Better Than Building From Scratch
LlamaIndex processes a lot of documents daily - the exact numbers from their marketing site are probably inflated. Companies like Salesforce and KPMG use it in production, which means it doesn't completely fall apart at scale.
Retrieval accuracy improved about 35% in recent versions according to benchmarks. Still not perfect - expect 15-20% of queries to return irrelevant results, especially with technical jargon or industry-specific terms.
Response times typically 500ms to 3 seconds depending on document size and query complexity. Faster than building your own solution but slower than dedicated search engines.
Integrations: The Good and the Painful
LlamaIndex connects to most things you'd expect: AWS Bedrock, Azure OpenAI, GCP Vertex AI for cloud deployment. LlamaDeploy guide covers the basics but Docker's networking makes me want to throw my laptop - use host.docker.internal instead of localhost for Mac/Windows. Vector databases like Pinecone, Weaviate, and Chroma work well. Enterprise sources like SharePoint, Google Drive, and Notion are supported.
The fine print: SharePoint integration is finicky with permissions. OAuth token expires every hour and Microsoft's API rate limiting is aggressive - expect HTTP 429 errors regularly. Google Drive connector sometimes hits rate limits. Notion works great until you have deeply nested pages. Always test with your actual data sources before committing.
Boeing reportedly saved 2,000 engineering hours using pre-built components. Your mileage will vary depending on how well your data fits their assumptions. Check community discussions for real-world integration experiences. MongoDB Atlas and Elasticsearch also work if you're already using them.
LlamaCloud: Managed Service That Costs Real Money
LlamaCloud handles the infrastructure so you don't have to manage vector databases and embedding services. SOC 2 compliant, auto-scaling, all the enterprise checkboxes. 150,000+ signups suggests people want managed RAG infrastructure.
Pricing starts reasonable but scales fast with usage. Document parsing costs add up quickly with large corpora. Free tier is enough for prototypes, production will hit paid plans fast.
LlamaIndex matured from a hackable library to something you can actually run in production without constant babysitting. Still requires understanding the concepts but won't randomly break like earlier versions. Good choice if you need document Q&A and don't want to build everything from scratch.