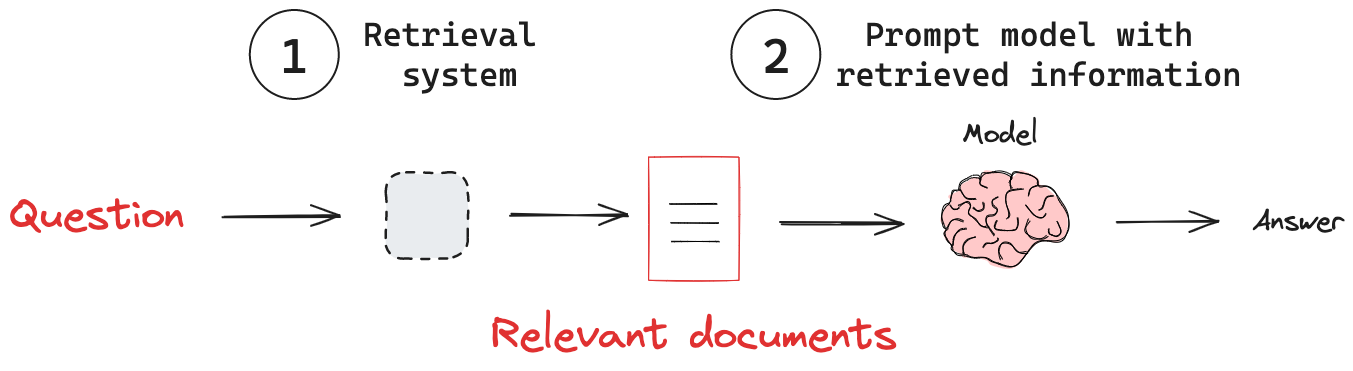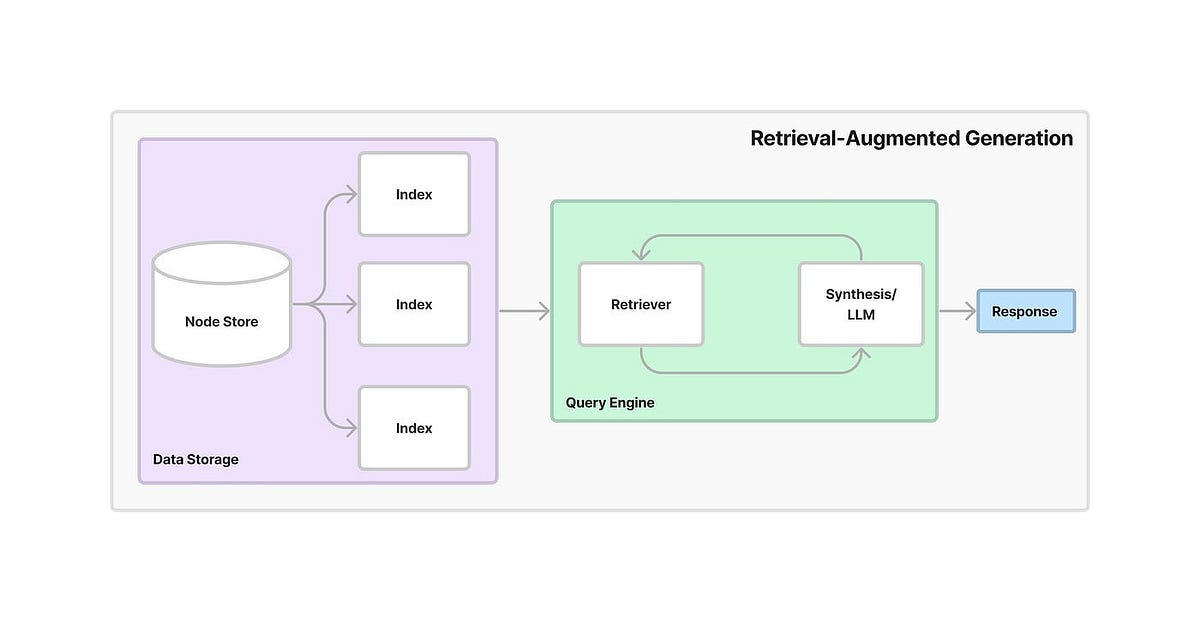
Everyone's building RAG systems because the demos look amazing. You feed some PDFs to ChromaDB, wire up LangChain, call GPT-4, and boom, ChatGPT for your docs. Then reality hits.
I've spent the last 18 months debugging RAG systems in production. Real users destroy your beautiful architecture.
The Three Components From Hell
OpenAI API - Looks great on paper. GPT-4 can answer anything! Except when their API shits the bed (seems like every other week lately), when you hit rate limits at 2pm on Tuesday for no goddamn reason, or when your bill jumps from $200 to $2,000 because someone figured out how to make your chatbot hallucinate 4,000-token responses. I learned this the hard way during a Black Friday demo - think our bill was like $850 or something insane like that.
Current pricing is around $5 per million input tokens for GPT-4, which sounds cheap until you realize embeddings cost extra, and every user question triggers multiple API calls. Budget at least $500/month for anything remotely useful.
LangChain - The Swiss Army knife of AI frameworks, which means it's good at nothing and breaks constantly. Version 0.1.0 silently broke our entire pipeline with a "small refactor" to their retrieval chains. Pin your version to 0.3.0 and pray they don't deprecate everything again. Spoiler: they will.
The LCEL syntax looks clean in examples but turns into undebuggable spaghetti the moment you need error handling or custom logic. The worst part? LangChain's error messages are about as helpful as a chocolate teapot. "Retrieval failed" - thanks, that narrows it down to literally everything.
ChromaDB - Fast vector search that randomly eats around 8GB of RAM and crashes without warning. The persistent storage works great until your Docker container restarts and all your embeddings vanish. Ask me how I know. (Hint: we lost 3 weeks of embeddings on a Tuesday morning)
Collections have a habit of corrupting themselves after around 50K documents or so. The error messages are useless: "Embedding dimension mismatch" tells you nothing when everything was working fine 10 minutes ago.
What Breaks In Production
The tutorials skip the part where OpenAI goes down for maintenance exactly when your CEO is doing a live demo. Or when ChromaDB decides to rebuild its HNSW index during peak traffic. Or when LangChain throws a cryptic error because someone uploaded a malformed PDF.
Your retrieval accuracy will be garbage until you spend weeks tuning chunk sizes, overlap parameters, and embedding models. The text-embedding-3-large model costs 6x more than the small version but only improves accuracy by 10%. You'll use it anyway because your boss wants "enterprise-grade" performance.
Memory leaks are everywhere. ChromaDB will slowly consume RAM until your server crashes. LangChain caches everything and never cleans up. OpenAI's Python client has connection pooling issues that manifest after exactly 4 hours of uptime.
Set your timeouts to something sane like 30 seconds, or users will sit there watching spinners while your system hangs. Implement circuit breakers or one failed service will cascade and kill everything. Cache embeddings aggressively or your OpenAI bill will bankrupt you.
The reality is that RAG systems are distributed systems, and distributed systems fail constantly. Every external API call is a potential failure point. Every network hop adds latency. Every service restart loses state.
Bookmark OpenAI's status page - their API goes down way more than they admit. And for the love of god, backup your embeddings somewhere else because ChromaDB will eventually eat them.
Read the Google SRE book if you want to understand why your RAG system is unreliable. Better yet, accept that it will break and design for graceful degradation from the start.
The Fallacies of Distributed Computing apply to every RAG system. The network is not reliable. Bandwidth is not infinite. Transport cost is not zero. The topology will change. Plan accordingly or spend your weekends fixing production.
But there's hope. After a year of 3am debugging sessions and production fires, I've identified the specific settings and configurations that actually work. Skip the theory - here's what keeps your RAG system running.