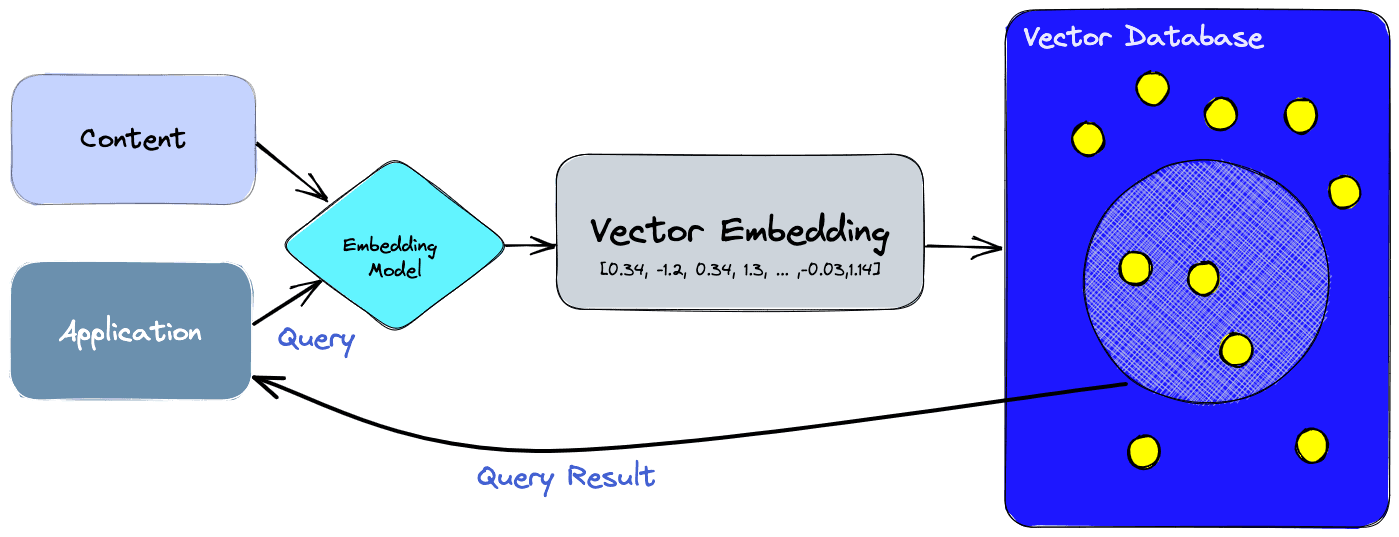
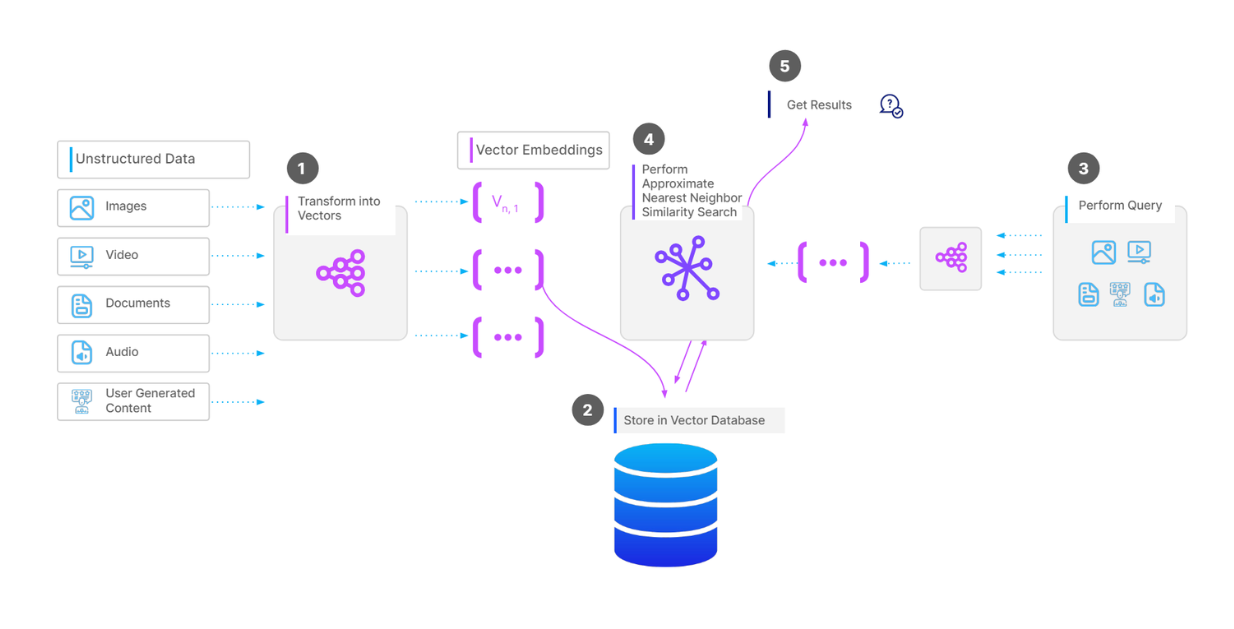
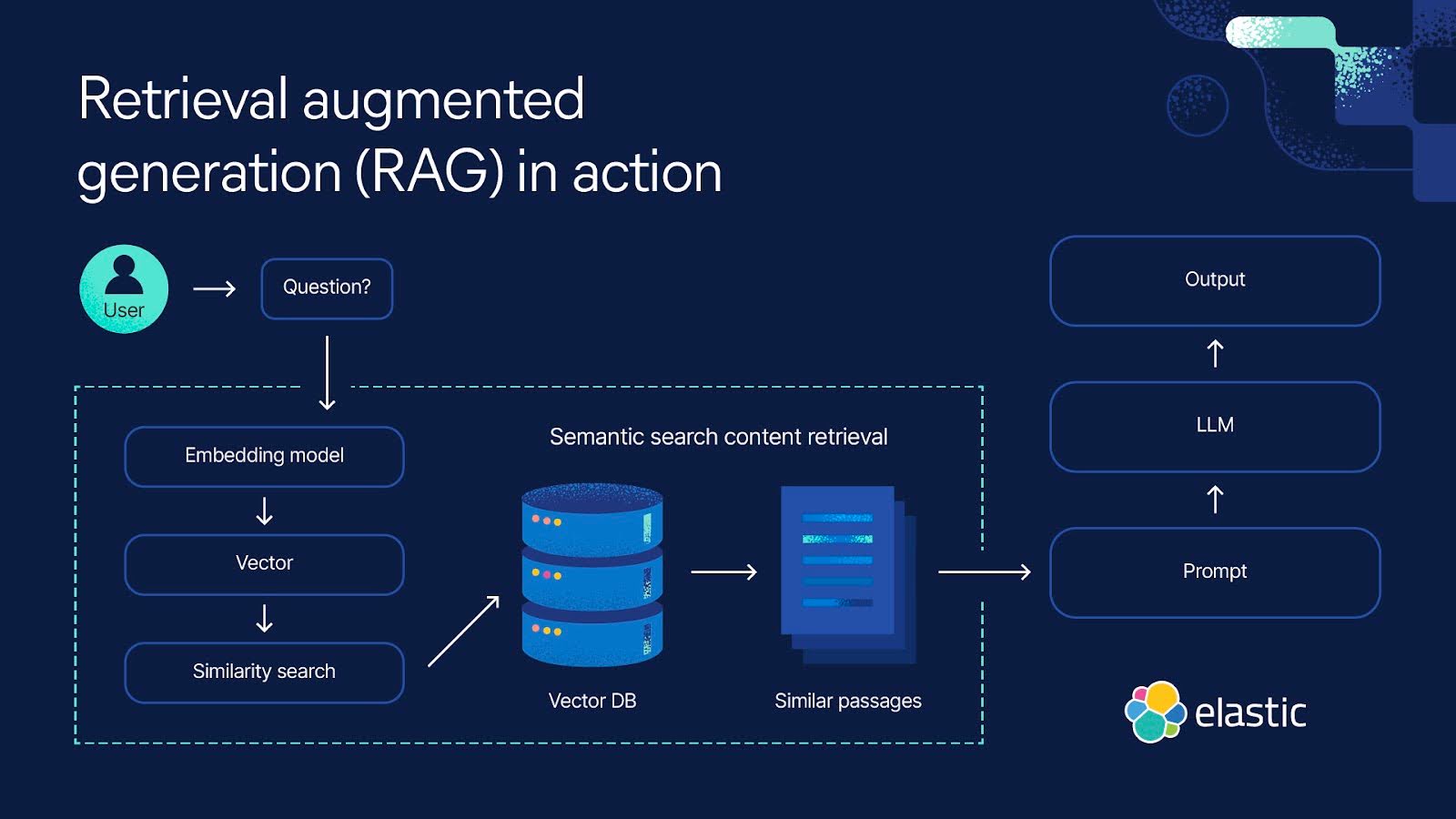
Our LangChain RAG system was choking. We had 50k+ documents, and queries were taking 3-4 seconds on a good day. The memory usage was insane - our Docker containers were eating 8GB RAM just sitting idle. When I found myself writing custom chain logic to make basic document search not suck, I knew something was wrong.
The Real Problems LangChain Couldn't Solve
Query performance was complete trash. Our users wouldn't shut up about it. I burned weeks optimizing retrieval chains, messing with similarity thresholds, and swapping vector stores. Nothing worked. The whole thing crumbles under document-heavy workloads.
Memory leaks everywhere. After processing a few thousand queries, memory usage would balloon. I'd restart containers daily. The chain abstraction created objects that never got garbage collected properly - a known issue in the LangChain community.
Agent hell. Don't even get me started on LangChain agents. Half the time they'd fail silently. The other half they'd spiral into infinite loops calling the same tool over and over like a broken record. Debugging felt like trying to fix a car with a blindfold on because error messages were useless: "Agent failed to complete" - oh wow, thanks for that earth-shattering insight. The agent documentation looks pretty but production reality is a dumpster fire.
What Actually Made Me Switch
I tried LlamaIndex on a Friday afternoon, mostly out of frustration. Built a simple RAG system in 30 minutes that worked better than our LangChain monstrosity. Here's what immediately worked:

- Queries went from 3+ seconds to under 500ms - same documents, same questions
- Memory usage dropped from 8GB to 2GB for the same workload
- Error messages were actually readable - "Failed to retrieve from vector store: Connection timeout" instead of cryptic chain failures
The breaking point was when I ran both systems side-by-side for a week. LlamaIndex consistently returned more relevant results and didn't crash once. LangChain went down twice from memory issues, including one 3am outage that had me frantically restarting containers.
Look, after dealing with that 3am bullshit, here's when you should NOT put yourself through this migration:
Before You Make This Mistake
Don't migrate if you're heavily using LangChain agents. LlamaIndex's agent support is half-baked at best. If your system depends on complex multi-step reasoning with tools, stick with LangChain until LlamaIndex catches up.
Don't migrate if you're doing basic chat. If you're just building a chatbot without document retrieval, LangChain's conversation chains work fine. LlamaIndex is overkill.
Do migrate if document search is your main use case. That's where LlamaIndex actually shines.
Version Reality Check
LlamaIndex changes constantly - I migrated on v0.13.6 but they just dropped v0.14.1 with breaking changes. Pin your fucking versions or everything explodes. The API changes constantly, so pin your versions or watch everything implode. I learned this when v0.13.7 randomly broke our PDF processing pipeline on a Tuesday morning - spent 4 hours rolling back.
The migration took me two weeks because I didn't expect the dependency hell and API differences. Plan for longer than you think. Check the migration guides for specific component conversions.